云原生数据湖到底怎么用才不浪费资源又能发挥最大价值呢?

关于怎么用好云原生数据湖,让它既省钱又高效,这确实是很多公司头疼的问题,根据一些行业实践者的分享,比如来自某技术社区的一位资深架构师“老王”的观点,核心在于从一开始就建立一个“精打细算”的文化和一套有效的管理机制,而不是等到账单爆表了再手忙脚乱。
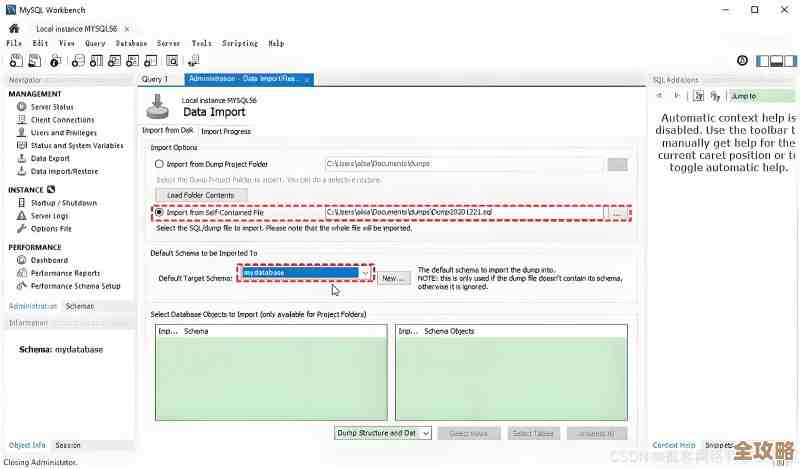
最基础也最重要的一点是,别把数据湖当成一个“什么都往里扔”的垃圾场,听起来简单,但很多人栽在这第一步,云原生数据湖的存储成本可能看起来不高,但如果没有规矩,数据就会疯狂增长,变成一堆没人管理、没人使用的“数据债务”,这不仅浪费存储费用,更会拖垮后续的数据处理性能,必须建立严格的数据入湖规范,来自某电商公司的案例提到,他们要求任何数据入湖前都必须有明确的负责人、数据字典(也就是说明这个数据是干什么的)和生命周期策略,无效的、过时的数据要定期清理,不能让它永远占着空间。
要非常关注数据的“流动成本”,在云上,把数据从存储的地方移动到计算的地方,或者在不同服务之间传输,都可能产生巨大的网络费用,这就是所谓的“数据出口费”或“带宽费”,一位来自某云厂商的解决方案工程师在一次分享中强调,聪明的做法是“计算向数据靠拢”,意思是,尽量让你的数据分析工具(比如Spark、Presto等)直接在数据存储的地方运行,而不是把海量数据拉到一个集中的计算集群再处理,这样可以显著降低网络传输成本,对数据进行分层存储也很关键,把经常要用的“热数据”放在高性能但较贵的存储层(如SSD),把偶尔查询的“温数据”放在标准存储层,把几乎不用的“冷数据”归档到最便宜的归档存储层,云服务商通常都提供自动化的生命周期策略,可以设置规则让数据自动在不同层级间移动,这能省下一大笔钱。
计算资源的使用要有“弹性”思维,但不能“放任自流”,云原生的最大优势就是按需付费,可以随时开启和关闭计算资源,但问题在于,如果管理不善,很容易出现计算集群一直空转、或者任务一拥而上导致资源争抢的情况,某共享出行平台的数据团队在他们的技术博客中写道,他们通过采用“无服务器”架构的查询服务(比如AWS Athena、BigQuery)来处理即席查询(就是临时起意的分析需求),这类服务你只需要为每次查询扫描的数据量付费,不用管理服务器,特别适合不固定的、小批量的分析任务,而对于有规律的、大批量的数据处理任务(比如每天凌晨的报表作业),则使用可自动伸缩的集群(如EMR、Dataproc),并设置好最大节点限制和自动关闭策略,任务一完成集群就自动缩容或关闭,避免资源闲置。
价值体现在“用得好”,而不仅仅是“存得多”,数据湖的终极目标是赋能业务,如果数据湖里的数据没有被充分利用,那建得再省也是一种浪费,这就需要配套完善的数据发现和数据治理工具,要让业务人员和技术人员能轻松地找到他们需要的数据,并且信任数据的质量,可以建立统一的数据目录,像图书馆的检索系统一样,让大家能快速搜索和理解湖里有啥数据,推广自助数据分析平台,让业务人员经过简单培训后,能自己动手从数据湖中提取信息,减少对数据工程师的重复性需求依赖,这样才能真正释放数据的价值。
不让云原生数据湖浪费资源并发挥最大价值,关键靠三件事:一是立规矩,管好数据的“进口”和“归宿”;二是精打细算,关注存储和计算的每一分钱;三是促使用,让数据能方便、可靠地转化为业务洞察。 它是一个持续优化的过程,需要技术、流程和文化的共同配合。

本文由太叔访天于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73884.html