InnoDB里数据页到底怎么一步步变成索引,这过程其实没那么简单

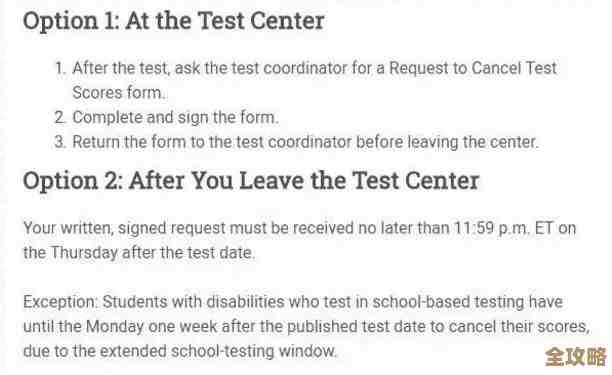
想象一下,你有一本非常厚的电话簿,但不是按姓氏首字母排序的,而是按照人们注册电话的时间顺序胡乱记录的,如果你想找“张三”的电话,你必须从第一页开始,一页一页地翻,直到找到为止,这效率太低了,InnoDB存储引擎在开始处理数据时,最初面临的情况就有点像这样,但它非常聪明地通过一系列步骤,把这些杂乱无章的数据页(可以理解为电话簿的每一页)组织成了一个高效的索引结构,也就是我们常说的B+树索引,这个过程,远不止是简单排个序那么简单。
我们要理解最基本的单位:数据页,在InnoDB的世界里,磁盘和内存之间交互数据的基本单位就是“页”,默认大小是16KB,每当有新的数据插入时,比如一条新的用户记录,InnoDB并不是直接把它写到磁盘的某个随机位置,它会尝试把这条记录放进一个合适的数据页里,你可以把一个数据页想象成一个固定大小的容器或者一个笔记本的页面。

最开始,当表的数据量还很小时,可能只有一个数据页,这时候,新记录就简单地追加到这个页里,这个最初的数据页,在索引的演化过程中,扮演着一个非常关键的角色,它最终会成为B+树索引的根节点,但此时,它还只是一个孤零零的页面,里面装着所有数据,可以理解为既是根,也是叶子。
随着数据不断插入,这个唯一的数据页迟早会被填满,就像一本笔记本写满了,你需要一本新的,当第一个数据页满了之后,InnoDB会申请一个新的空白数据页,这时,问题就来了:新来的数据应该放在哪里?如果还是胡乱放,那么查找数据就又退化成“翻遍所有笔记本”的糟糕状态了,为了解决这个问题,InnoDB开始引入“页分裂”和“目录项”这两个核心机制,这是构建索引的关键一步。

当新数据需要插入,但目标页已经满了,InnoDB不会简单地把它扔到新页就完事,它会进行一个精巧的操作:页分裂,大致过程是,它会将已满的那个页(比如我们称之为页A)中的数据大致分成两半,把后半部分数据移动到一个新申请的页(页B)中,再把新插入的记录根据其大小,放入页A或页B中合适的位置,这就像是你把一本写满的笔记本从中间撕开,把后半部分内容装订到一本新笔记本里,然后再把新内容插入到两本笔记本中正确的位置,以保证内容依然是按主键顺序排列的。
光有分裂还不够,现在数据分散在了两个页里,系统怎么知道要找的记录是在页A还是页B呢?这就需要建立一个“目录”,InnoDB的做法是,在之前那个唯一的根页面上,不再直接存放用户数据,而是把它升级成一个专门存储“目录项记录”的页,这些目录项记录非常简单,每个记录只包含两个核心信息:一个是下属页中最小的主键值,另一个是指向该下属页的指针。

根页面上现在会有两条目录项记录:第一条记录指向页A,并标明页A中所有记录的主键都小于某个值X;第二条记录指向页B,并标明页B中所有记录的主键都大于等于X,这样,当你要查找一条主键为Y的记录时,InnoDB只需要在根页面这个“顶层目录”里看一眼,比较一下Y和X的大小,就能立刻判断出Y如果存在,肯定是在页B里,然后它就直接去页B里精准查找了,效率得到了巨大提升。
随着数据量的持续增长,可能连第二层的目录项页(也就是之前的页A和页B,它们现在存放实际数据,被称为叶子节点)也会被填满,当某个叶子节点再次需要分裂时,这个过程会向上递归,分裂出来的新页信息,需要被记录到它的上一层目录页(也就是父节点)中,如果父节点(此刻可能还是根节点)也满了怎么办?那么父节点自己也会发生分裂。
父节点的分裂过程类似:根节点这个目录页本身也会一分为二,然后需要再创建一个新的、更高层级的根页来容纳这两个分裂出来的目录页的目录项,这样一来,树的层级就增加了一层,原来的根节点现在降级为中间层的目录节点,而新创建的页成为了新的根节点。
通过这样一层一层的目录项记录和不断发生的页分裂,最终就形成了一棵倒挂的树,也就是B+树,最顶上的叫根节点,中间的是非叶子节点(内部节点),它们只存放目录项,不存放实际的全部数据;最底下的则是叶子节点,它们之间通过指针相互连接形成一个双向链表,所有真实的用户数据都存放在叶子节点里。
从最初一个杂乱堆积数据的数据页,到最终形成一棵层次分明、查询高效的B+树索引,这个过程是动态的、自下而上生长的,它依赖于数据页的申请、记录的按序插入、页面的分裂以及目录项记录的建立和维护,每一步都不是简单的物理排序,而是一种逻辑结构的精妙构建,确保了即使在海量数据下,也能通过有限的几次磁盘IO快速定位到目标数据,这也就是为什么说,数据页变成索引的过程,其实没那么简单。
本文由盘雅霜于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84973.html