分布式数据库架构那些事儿,设计特点其实没那么复杂但挺关键

说到分布式数据库,听起来好像是那种只有大厂的技术专家才需要关心的、特别高深莫测的东西,但其实它的核心设计思想,如果我们用生活中的例子来打比方,就会发现它的那些关键特点其实并不复杂,但确实非常关键,这就像管理一个团队,人少的时候怎么都行,人多了就必须得有一套章法,否则就乱套了。
(来源:分布式系统的基本理念)
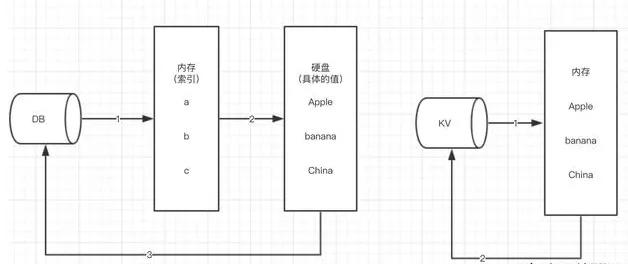
分布式数据库要解决的根本问题就一个字:“大”,这个“大”体现在三个方面:数据量太大,一台机器存不下了;访问的用户太多,一台机器处理不过来了;对可靠性的要求太高,一台机器万一坏了,整个服务就不能停了,这就好比一家小卖部,一个老板加一个账本就能搞定所有生意,但当你开的是像沃尔玛那样的全球连锁超市,你就不可能把所有商品的库存信息、所有门店的销售记录都记在一个本子上,也不可能只让一个人去处理全球的收银,你必须把数据和计算任务分摊到很多地方、很多人身上,这就是分布式数据库要干的事。
它是怎么做到的呢?主要有几个关键的设计特点,我们一个一个用大白话说。
第一个特点:数据分片——把大象放进冰箱,得分层切块。

你不能把整个公司的账本都塞给一个会计,那样他会累死,查账也慢,分布式数据库的做法叫“分片”,就是把一大块数据,比如10亿条用户信息,切成很多个小块,比如按用户ID的字母顺序分,A开头的放一起,B开头的放一起……或者按地域分,北京的用户数据放一组服务器,上海的放另一组。
(来源:数据库分片技术)
这样做的好处是,当你要查一个用户的信息时,你不用去10亿条数据里大海捞针,你只需要知道这个用户是哪个片区的,直接去问负责那个片区的“小会计”就行了,大家各管一摊,并行工作,速度和效率自然就上来了,这个设计特点的关键在于“怎么切分”最合理,切得不好会导致有些服务器特别忙(数据热点),有些特别闲,这就失去了分布式的意义。
第二个特点:多副本复制——重要的事情备份三遍。

光是把数据分开存放还不够,万一某个“小会计”的办公室着火了,他管的那部分账本不就全没了吗?这风险太大了,分布式数据库一定会给每一片数据都做好几个备份,放在不同的机器上,甚至不同的城市机房裡,这就像公司的重要文件,不但总经理办公室有一份,财务总监那里有备份,可能还会在银行的保险柜里再存一份。
(来源:数据复制与一致性模型)
这样,即使一台机器宕机了,系统可以立刻切换到有备份的机器上继续提供服务,保证了高可用性,也就是我们常说的“服务不中断”,这里的关键点在于,如何保证这几个备份之间的数据是“一致”的?比如总经理修改了文件,如何确保财务总监和银行里的备份也能同步更新?这就是分布式系统里最核心也最复杂的“一致性”问题,不同的数据库在处理这个问题上会有不同的侧重点,有的追求强一致性(所有备份瞬间同步,但可能慢一点),有的追求最终一致性(允许短暂不一致,但最终会同步,速度更快)。
第三个特点:无中心化与中心化——是各自为战还是有总指挥?

在管理架构上,分布式数据库主要有两种路子,一种是“无中心”的,就像一个小型创业团队,没有明确的老板,每个成员地位平等,有事大家一起商量着来(通过一种复杂的投票机制),这种结构很民主,没有单点故障(因为没老大),但商量事情的效率可能不高。
另一种是“有中心”的,就像传统的公司架构,有一个主节点(Master)充当“总指挥”,它负责接收所有写请求,然后下达命令给各个从节点(Slave),这种结构效率高,管理简单,但风险是“总指挥”成了关键单点,它要是出问题了,整个系统就瘫痪了(虽然通常会有备用的总指挥随时准备接班)。
(来源:CAP定理与分布式架构权衡)
选择哪种架构,往往是在一致性、可用性、分区容错性这三个方面做权衡,这是一个著名的“CAP定理”说的,简单理解就是,在分布式系统里,你很难同时把这三样都做到完美,必须有所取舍,为了极高的可用性,可能就得在数据一致性上稍微放松一点要求。
所以你看,分布式数据库架构的那些事儿,其设计特点并不神秘,它核心就是解决“单机搞不定”的问题,通过分片来解决规模和性能问题,通过复制来解决可靠性问题,并通过不同的架构选择来平衡效率、一致性和可用性,这些设计点每一个单拎出来看,逻辑都很直接,但把它们巧妙地组合在一起,并能在真实的、复杂的网络环境中稳定运行,这才是其“挺关键”和真正有技术含量的地方,它不是什么银弹,而是一套根据实际业务需求,在诸多技术约束下做出的精妙权衡方案。
本文由水靖荷于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84818.html