红色惊喜带你快速过Redis面试,这些题和答案你得看看

(引用来源:网络技术社区“红色惊喜”系列文章)
Redis面试,别怕,咱们今天就用大白话过一遍那些常问的,让你心里有个底,面试官也是人,他问你问题是想知道你到底用没用过,理不理解,所以别死记硬背,理解着说最重要。
第一类:Redis是个啥?为啥快?
这几乎是开场必问,看看你对Redis的基本认知。
-
问题:说说Redis是什么?和MySQL有啥不一样?
- 答案: Redis就是个速度超快的“大字典”或者“钥匙柜”,你给它一个键(key),它立马能给你返回对应的值(value),这个值可以是字符串、列表、集合等等,它最大的特点就是把数据都存在内存里,所以读写操作就像我们直接从电脑内存里取东西,快到飞起,而MySQL这类数据库,数据主要是存在硬盘上的,读写要经过磁盘I/O,自然就慢多了,简单说,Redis是内存数据库,主打高性能、高并发读写;MySQL是硬盘数据库,主打的是数据的持久化存储和复杂查询。
-
问题:Redis为啥这么快?除了内存还有别的原因吗?
- 答案: 光说内存还不全面,你得说出另外几个关键点,第一,确实是基于内存,这是基础,第二,它用了单线程模型来处理网络请求和键值对操作,你可能会想,单线程不是容易堵吗?好处就在于它避免了多线程带来的频繁上下文切换和竞争条件的开销,对于这种内存操作来说,单线程的效率反而很高,第三,它用了IO多路复用技术,这个听起来高级,其实可以理解为一个大堂经理(单线程)同时监听很多个客人的需求(网络连接),哪个客人有需求了就去处理一下,而不是傻等着一个客人办完再接待下一个,这样就能用单个线程处理大量并发连接了,第四,它的数据结构是专门设计的,非常高效,比如简单动态字符串、压缩列表这些。
第二类:数据怎么存不丢?——持久化问题

既然数据在内存里,一断电就没了,那Redis怎么保证数据不丢失呢?这就是持久化要解决的问题。
-
问题:Redis有哪两种持久化方式?说说它们的特点。
- 答案: 主要有两种:RDB和AOF。
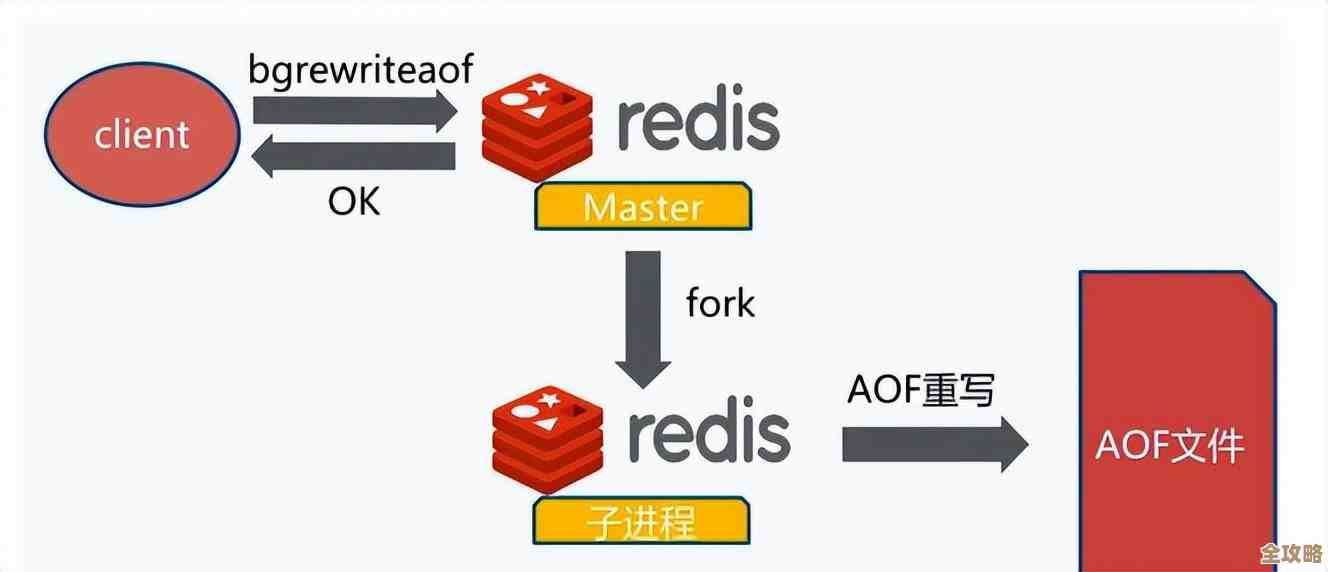
- RDB(快照): 就像是给当前的数据拍一张全景照片,然后把照片存到硬盘上,可以设置每隔一段时间拍一次,比如5分钟内有100个key变了就拍一张。好处是恢复数据快,因为就是直接加载那个照片文件;坏处是可能会丢失最后一次快照之后的数据(比如刚拍完照,服务器断电了,那之后修改的数据就没了)。
- AOF(日志): 它不拍照,而是像个记账先生,把每一次写操作命令都记录在一个日志文件里,当Redis重启时,就把这个日志里的命令从头到尾再执行一遍,这样就能重建数据。好处是数据安全性高,一般最多丢失一秒的数据(可以配置);坏处是日志文件通常会比RDB文件大,恢复数据的时候重放所有命令,速度比加载RDB慢。
- 答案: 主要有两种:RDB和AOF。
-
问题:生产环境一般怎么选?
- 答案: 为了兼顾性能和数据安全,通常两者都开启,用RDB做定期的冷备,万一出问题了有个快速的恢复点,同时用AOF来保证尽可能少的数据丢失,Redis重启的时候会优先使用AOF文件来恢复,因为数据更完整。
第三类:内存满了怎么办?——数据淘汰策略

内存是有限的,当Redis的内存用完了,再有新数据进来怎么办?
- 问题:Redis的内存淘汰策略有哪些?常用的是哪种?
- 答案: 策略有好几种,主要分两类:一类是针对设置了过期时间的key,另一类是针对所有key,常用的几个是:
- volatile-lru:在所有设置了过期时间的key中,挑最近最少使用的那个淘汰掉,这是最常用的策略。
- allkeys-lru:在所有key中,挑最近最少使用的淘汰,如果你的应用没有明显热点数据,用这个比较好。
- volatile-ttl:在设置了过期时间的key中,挑剩余寿命最短的淘汰。
- noeviction:不淘汰任何key,如果内存满了,再有写请求就直接报错,这是默认策略,但生产环境一般不会用这个。
- 答案: 策略有好几种,主要分两类:一类是针对设置了过期时间的key,另一类是针对所有key,常用的几个是:
第四类:怎么搭建高可用的Redis?——主从、哨兵、集群
单机Redis万一挂了,整个服务就瘫了,所以高可用方案必问。
- 问题:说说主从复制、哨兵(Sentinel)、集群(Cluster)都是干嘛的?
- 答案:
- 主从复制: 就是搞一个主库(Master),一个或多个从库(Slave),主库负责写,从库负责读,并且自动从主库那里同步数据。好处是读写分离,提高读性能,也有了一份数据备份。坏处是主库挂了,需要手动把从库变成主库,不能自动切换。
- 哨兵(Sentinel): 它就是来解决主从“不能自动切换”问题的,哨兵是一个独立的进程,它时刻监控着主从库的健康状态,一旦发现主库挂了,它就会自动从从库中选举出一个新的主库,并让其他从库连接新的主库。它主要负责自动故障转移。
- 集群(Cluster): 当数据量特别大,一台机器内存装不下时,就需要用集群,它把数据分片存储在多个Redis节点上,同时每个分片还有自己的从库做备份。它主要负责数据分片和负载均衡,当然也集成了类似哨兵的高可用功能,简单说,哨兵解决高可用,集群解决海量数据存储和高并发。
- 答案:
第五类:实战中常遇到的问题
- 问题:什么是缓存穿透、击穿、雪崩?怎么解决?
- 答案:
- 穿透:查询一个根本不存在的数据,缓存和数据库都没有,这样每次请求都会打到数据库上。解决:1. 对不存在的key也缓存一个空值(null”),并设置一个短的过期时间,2. 用布隆过滤器快速判断某个key是否在数据库中存在。
- 击穿:一个热点key突然过期了,此时大量请求同时涌来,全部打到数据库上。解决:1. 设置热点key永不过期,2. 用互斥锁,只让一个请求去查数据库重建缓存,其他请求等待。
- 雪崩:大量key在同一时间过期,或者Redis集群宕机,导致所有请求都打到数据库,数据库扛不住就崩了。解决:1. 给key的过期时间加上随机值,避免同时过期,2. 搭建Redis高可用集群(哨兵/集群),3. 服务降级和熔断机制。
- 答案:
就是“红色惊喜”系列中总结的Redis面试核心内容,覆盖了大部分基础和中高级问题,希望这些大白话的解释能帮你更好地理解和应对面试。
本文由太叔访天于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84845.html