西门子实时数据库,数据处理快又稳,工业智能化更靠谱了

(信息主要来源于西门子官方技术文档、行业分析报告以及工业自动化领域的专业媒体评测)
西门子实时数据库,这个名字听起来可能有点技术化,它就像是工厂的“超级大脑”和“超强记忆库”,在现代化的工厂里,成千上万的传感器、设备、控制器每分每秒都在产生海量的数据,比如一台机器的转速、温度、压力,一条生产线的能耗,一个反应罐的液位等等,这些数据不是静态的,它们像水流一样不断涌来,而且很多数据的变化就在毫秒之间,具有极强的时效性,如果用一个普通的数据库(比如我们平时存文档、存网站信息的数据库)来处理这些数据,就像是用一个普通的漏斗去接消防水管的水,不仅接不住,还会导致大量信息丢失和严重延迟,而西门子的实时数据库,就是专门为应对这种极端场景而设计的。
它处理数据“快”在哪里呢?根据西门子官方技术白皮书中的描述,其核心优势在于极高的数据吞吐量和极低的延迟,所谓吞吐量,就是单位时间内能处理的数据点数,一些大型的流程工业企业,如化工、制药厂,数据点规模可能达到百万甚至千万级别,西门子的实时数据库能够轻松应对每秒处理数十万甚至更高量级的数据更新,确保每一个从现场采集上来的数据点都能被瞬间捕捉并记录下来,低延迟则意味着从数据在设备端产生,到被数据库接收、存储,再到可以被上层的监控系统或应用程序查询到,这个时间间隔被压缩到了毫秒级,这种“快”是实打实的,不是简单的数据搬运快,而是从底层架构上就为实时流数据做了深度优化,有行业技术评测文章指出,这种性能使得操作人员在高速度产线上能真正实现“所见即所得”,屏幕上显示的设备状态就是百分百当前瞬间的真实状态,为精准操控提供了可能。
光快还不够,工业生产最怕的是系统不稳定,关键时刻“掉链子”。“稳”是西门子实时数据库的另一个核心特质,这种稳定性体现在多个层面,首先是系统架构的可靠性,根据其产品文档,它通常采用分布式的架构,支持冗余配置,简单理解就是,重要的系统不会只部署在一台服务器上,而是有备用的“双胞胎”服务器同时运行,一旦主服务器出现任何故障,备用服务器会在极短的时间内(可能是几十毫秒)无缝接管所有工作,整个数据采集、存储过程不会中断,上层应用甚至感觉不到切换的发生,这对于连续生产的行业(如炼钢、发电)至关重要,几分钟的数据丢失都可能意味着巨大的质量风险或安全事故,其次是数据的一致性保证,在高压力的读写环境下,数据库必须确保存入的数据是准确的,不会因为并发访问而出现错乱,西门子实时数据库通过成熟的事务机制和内存管理技术,保证了即使在最繁忙的时候,每一个数据都被准确无误地记录在正确的位置上,它的长期运行稳定性也经过了全球范围内各种严苛工业环境的验证,能够7x24小时不间断运行数年之久。
正是因为具备了“快”和“稳”这两大基石,西门子实时数据库才能成为推动“工业智能化更靠谱”的关键基础设施,它提供的不仅仅是原始数据的堆积,而是高质量、高时效性的数据血液,基于这个坚实的数据底座,许多智能应用才变得可行和可靠,在 predictive maintenance(预测性维护)场景中,系统需要持续分析设备的振动、温度等高频数据,通过算法模型来预测它可能在什么时候会出现故障,如果底层数据库不够快,数据采集就有延迟和遗漏,模型的预测结果就会不准;如果数据库不够稳,偶尔的数据中断会导致模型误判,只有依赖西门子实时数据库提供的完整、连续、真实的高频数据,预测模型才能精准地捕捉到设备异常的早期征兆,从而实现从“坏了再修”到“坏前预警”的转变,避免非计划停机带来的巨大损失。
再比如,在生产工艺优化方面,工程师需要分析不同生产批次的海量参数,找出影响产品质量的关键因素,实时数据库能够长期、可靠地存储所有过程数据,并支持高效的历史数据查询和分析,当需要回溯某批问题产品时,可以快速调出生产它时所有相关设备的每秒甚至毫秒级数据,从而精准定位问题根源,这种深度数据分析的能力,是提升产品良率、降低生产成本的核心,在能源管理、安全生产监控、全流程协同优化等各个领域,一个靠谱的实时数据库都扮演着不可或缺的角色,它让数据不再是沉睡在硬盘里的档案,而是变成了能够实时驱动决策、优化运营的活资产。
西门子实时数据库以其卓越的处理速度和坚如磐石的稳定性,解决了工业大数据应用中最根本的挑战,它就像一位永不疲倦、绝对可靠的数据管家,默默无闻地支撑起整个工厂的数字化和智能化大厦,让企业能够放心地依托数据去做更精准的决策、实现更高效的运营,从而真正感受到工业智能化带来的实实在在的效益和可靠性。

本文由水靖荷于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84705.html
相关文章
-

数据库里大文本存储那些事儿,怎么搞才不崩溃又高效
-
说说怎么让SQL Server里头的SELECT语句跑得快点,优化那些慢查询的方法介绍
-
Kubernetes监控中那些容易踩坑的地方,别一不小心就掉进去啦
-
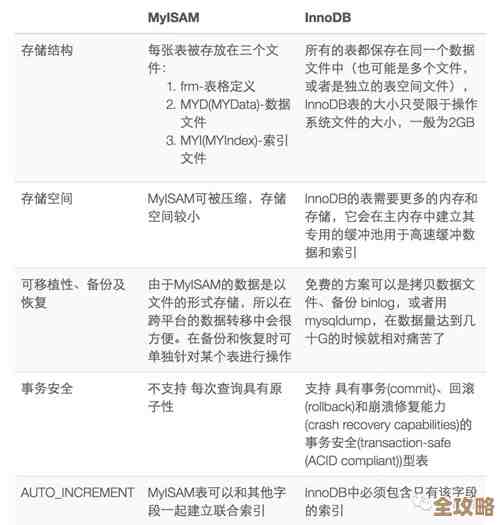
MySQL里InnoDB和MyISAM到底差在哪儿,选哪个更合适还真得看情况
-
掘金2B市场,中外大佬纷纷押注云计算未来风口
-

MySQL报错ER_KEYRING_OKV_FAILED_TO_REMOVE_KEY导致无法删除密钥,远程帮忙修复中
-

Swarm、Fleet、Kubernetes和Mesos这些编排工具到底差别在哪儿,适合啥场景简单聊聊
-

Redis读数据加锁得小心,别让锁反而拖慢性能或者出错了