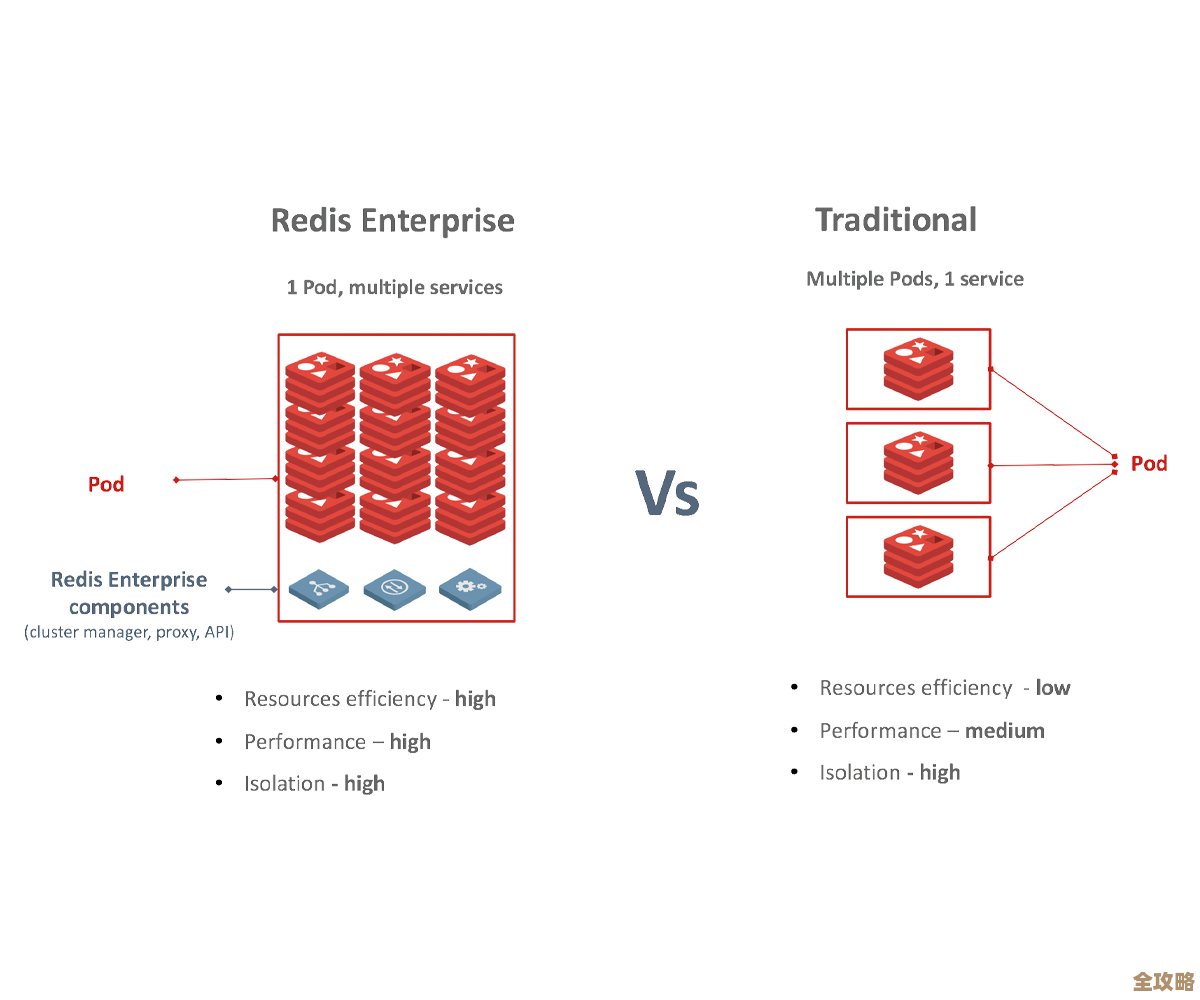
Kubernetes监控中那些容易踩坑的地方,别一不小心就掉进去啦

主要参考了知乎专栏“云原生监控实战”、个人技术博客“酷壳-CoolShell”中陈皓关于分布式系统排查的观点,以及Prometheus官方文档中关于常见配置陷阱的章节)
很多人一开始就栽在监控数据采集不全这个坑里,Kubernetes的环境是动态的,Pod今天在这台机器上,明天可能就被调度到另一台了,如果你还按照老办法,只盯着固定的IP地址或者主机名去监控,那肯定会漏掉一大堆数据,你用个脚本去抓取某个Pod的指标,但这个Pod重启了,IP变了,你的监控立马就瞎了,正确的做法是必须利用Kubernetes的服务发现机制,让监控系统(比如Prometheus)能自动发现集群里有哪些Pod、Service需要监控,并动态更新抓取目标,你要是没配置好这个,监控覆盖率就是个笑话,出了问题根本找不到北。
第二个大坑是关于资源请求和限制(Requests and Limits)的监控误解,很多人以为在yaml文件里设置了CPU限制为1核,这个Pod就一定能用到1核,监控图表上看到使用率低就高枕无忧了,这错得离谱,CPU限制其实是一个上限,它并不能保证Pod总能获得它请求的资源,当节点资源紧张时,即使你的Pod设置了Requests,它的性能也可能因为CPU节流(Throttling)而下降,你光看CPU使用率的平均值可能发现不了问题,但容器的CPU throttling指标会告诉你它被限制了多少次、多长时间,忽略这个指标,你就会对应用的性能瓶颈视而不见,用户感觉卡顿了,你这边监控却显示一切正常,这就非常尴尬了。
第三个坑是日志监控的混乱,Kubernetes鼓励应用把日志打到标准输出(stdout)和标准错误(stderr),这本来是个好设计,方便用DaemonSet like Fluentd去收集,但坑在于,如果你集群里跑的应用五花八门,每个应用的日志格式都自成一派,时间戳格式、日志级别定义、关键信息字段全都对不上,那你收集上来的就是一堆没法有效检索和聚合的废料,更头疼的是,如果应用本身不健全,没打足够的上下文信息(比如唯一的请求ID),当一个请求链路过多个Pod时,你根本没法把散落在各处的日志串起来还原现场,不事先规范好日志格式和内容,日志监控的投入很可能打水漂。

第四个容易掉进去的坑是只监控基础设施,不监控应用业务指标,你可能把节点的CPU、内存、磁盘IO都监控得滴水不漏,Pod的状态也尽在掌握,觉得这就够了,但用户不关心你的节点负载是50%还是70%,他们只关心服务能不能用、响应快不快,一个电商网站,你需要监控的关键业务指标可能是“下单成功率”、“支付接口响应时间99分位数”,如果只盯着资源指标,可能出现一种情况:所有基础设施监控项全绿,但用户就是没法下单,因为某个微服务内部的业务逻辑出了错,这种时候,没有业务指标告警,你就是最后一个知道问题的人。
第五个坑是告警配置的“狼来了”效应,这又分两种情况:一种是告警太敏感,阈值设得太低,比如CPU使用率一过80%就告警,但你的应用本身就有波峰波谷,导致一天到晚告警响个不停,运维人员最后就麻木了,真有事反而忽略了,另一种更糟糕的是告警不精准,信息量不足,比如只告警说“某个Pod内存使用率高”,但没说是哪个命名空间、哪个Deployment下的哪个Pod,也没附上相关的日志片段或最近的事件,收到这种告警,排查起来就像大海捞针,白白浪费黄金处理时间,好的告警应该能直接指引到问题的核心,并且避免噪音。

第六个坑,存储监控的复杂性被低估了,在Kubernetes里,你用Persistent Volume Claim (PVC)申请了存储,感觉就像用本地磁盘一样,但背后可能是网络存储(如NFS、Ceph),这时候,你光监控PVC的已用空间百分比可能不够,因为存储后端的性能瓶颈(比如IOPS、网络带宽)会直接影响应用的读写速度,导致请求超时,而这些问题,在容器层面的监控里是看不到的,你必须深入到存储系统本身去监控它的延迟、吞吐量等指标,忽略了这一层,当数据库性能骤降时,你查遍应用和节点都找不到原因,最后才发现是存储网络出了状况。
第七个坑,忽略了Kubernetes组件的健康度,你的应用Pod可能都运行得好好的,但控制平面(API Server、Scheduler、Controller Manager)或者工作节点的组件(kubelet、container runtime)可能已经出问题了,kubelet一旦不稳定,就可能无法向API Server报告节点状态,导致虽然节点实际已故障,但你在监控上看不到,调度器还会继续往这个坏节点上调度新Pod,引发连锁故障,必须对Kubernetes的核心组件建立独立的、高可用的监控,不能以为部署完就一劳永逸了。
还有一个隐形的坑是监控系统自身的资源管理,监控系统本身也是跑在Kubernetes上的一个负载,它需要消耗CPU、内存,尤其是存储(时间序列数据膨胀得非常快),如果你没给Prometheus之类的组件设置合理的资源限制,或者没规划好数据的保留策略,它可能一不小心就把节点的磁盘写满,或者因为OOM(内存溢出)被系统杀掉,到时候,不仅监控系统瘫痪,还可能拖垮整个节点上的业务Pod,这就成了“医者不能自医”的笑话,监控系统成了最脆弱的单点。
在Kubernetes里搞监控,你得有动态的、多层次的视角,从基础设施到应用、从资源到业务、从数据采集到告警响应,每个环节都可能藏着坑,只有把这些容易忽略的地方都考虑周全,你的监控系统才能真正成为保障系统稳定的眼睛和耳朵,而不是一个摆设或者新的故障源。
本文由黎家于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84741.html