Redis改动那些事儿,怎么改才算真懂Redis的门道

说到Redis的改动,很多人第一反应可能就是去改配置文件,或者敲几个命令调调参数,但这只是最表面的操作,就像你买了一台高性能跑车,只会踩油门和刹车,远远谈不上“懂车”,真懂Redis改动门道的人,心里装的不是一个个孤立的命令,而是一整套从里到外的逻辑,他们明白,任何改动都要回答三个核心问题:为什么要改?改了会影响谁?万一改砸了怎么兜底?

最基础的层面是“运行时动态调整”,这是Redis一个非常强大的特性,让你不需要重启服务就能修改很多关键参数,你发现某个Redis实例的内存使用率持续走高,快要触及maxmemory红线了,你可以立刻通过CONFIG SET maxmemory命令,在线调大内存上限,先确保服务不宕机,再比如,面对突发的流量高峰,写操作暴增,可能导致AOF文件同步策略(appendfsync)为everysec时依然有些吃力,你可以临时将其设置为no,让操作系统来决定同步时机,用可能丢失最多数秒数据的风险来换取极高的写入吞吐量,度过高峰后再改回来。
但只会动态调整,顶多算个“救火队员”,门道在于,你要清楚这些临时改动都是“治标不治本”的,调大了内存,你得立刻去分析内存增长的原因,是业务数据自然增长,还是出现了内存泄漏(比如大量Key过期不及时)?临时放松了AOF同步策略,你必须有后续的监控和预案,确保风险可控,动态调整是给你争取排查问题的宝贵时间,而不是解决问题的终点。

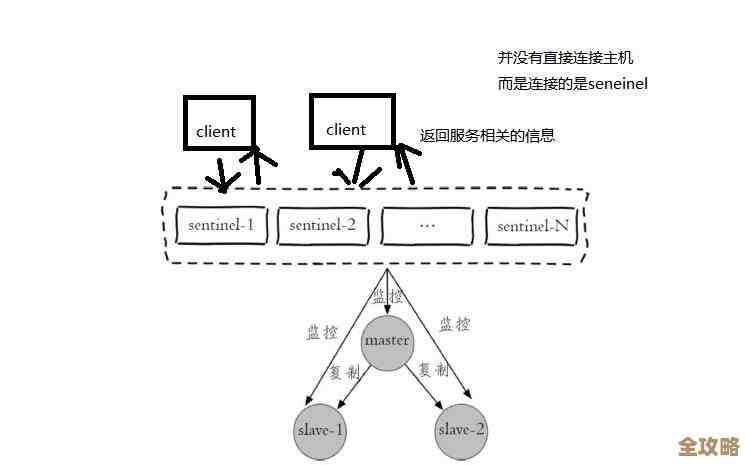
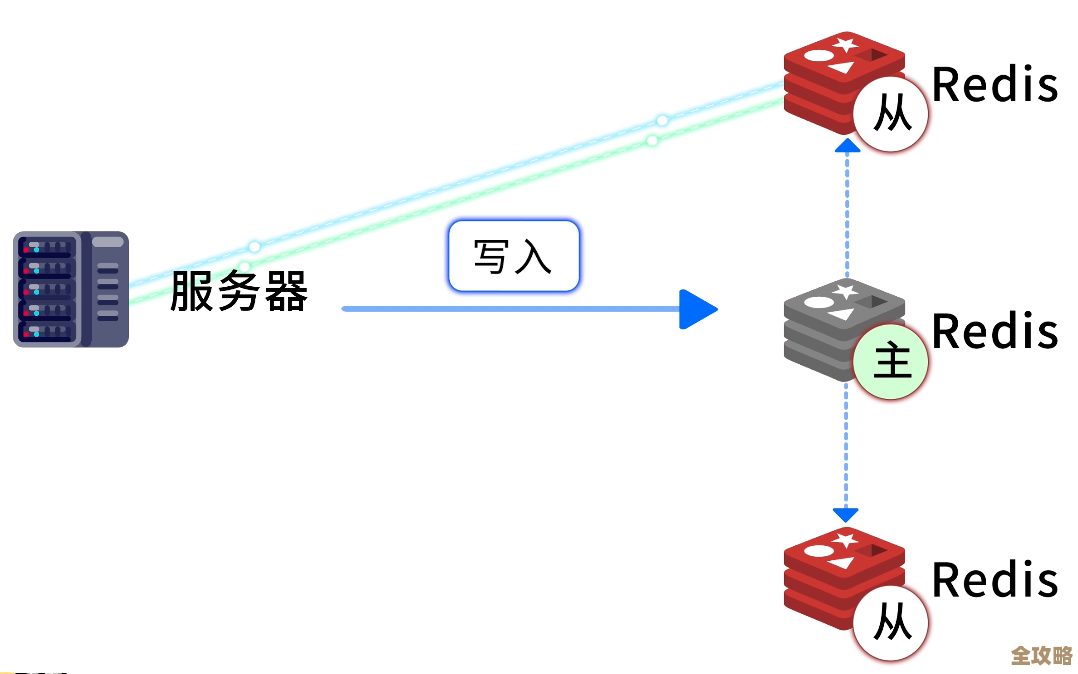
更深一层的改动,涉及到“架构与数据模型”,这就不是敲个命令能解决的了,需要你停下服务,深思熟虑,你是否遇到了持久化带来的性能瓶颈?是应该从RDB切换到AOF,还是启用混合持久化?这个改动决策取决于你对数据安全性和性能之间权衡的理解,又比如,当单个Redis实例不堪重负时,你是选择“纵向扩容”(升级更大内存的服务器),还是“横向拆分”(搭建Redis集群)?
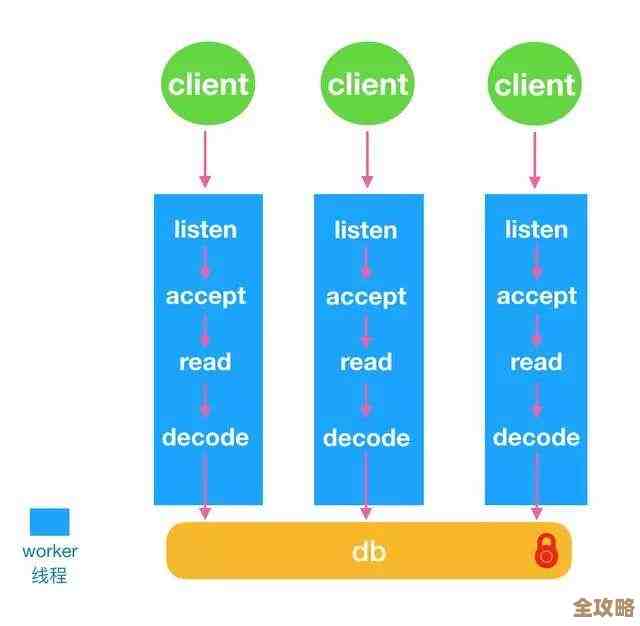
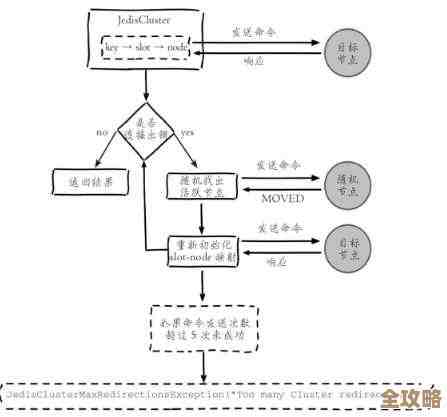
这里面的门道就深了,纵向扩容简单粗暴,但总会碰到物理极限,且成本高昂,横向拆分是更优雅的方案,但它要求你对数据分片规则、客户端路由方式有深刻理解,更关键的是,它可能要求你“改动数据本身”,举个例子,你之前把所有用户数据都放在一个巨大的Hash键里,现在要拆分成集群,这个巨大的Key就成了无法分割的“钉子户”,迁移起来极其痛苦,真懂行的人,在设计数据模型之初,就会考虑到未来的扩展性,避免使用过大的Key,而是设计出易于分片的Key结构。
最高级别的改动,其实是“打补丁”或“改源码”,这听起来很硬核,但确实是解决某些极端问题的终极手段,你的业务场景需要一种特殊的数据结构,Redis原生命令无法高效支持;或者你发现了Redis某个版本的一个影响你核心流程的Bug,等不及官方修复。
这时候,真懂Redis门道的人,会去深入研究Redis的源码,他们知道Redis是单线程Reactor模型,知道如何在不破坏其事件循环机制的前提下,安全地添加新的命令或修改现有逻辑,这种改动风险极高,需要深厚的C语言功底和对Redis内核的透彻理解,但一旦成功,你就能让Redis完美地贴合你的业务,发挥出极致的性能,这就像是给跑车更换了自研的发动机,达到了“人车合一”的境界。
总结起来,Redis改动的门道是一个递进的过程:从救急的“动态调整”,到治本的“架构与数据模型优化”,再到终极的“源码级定制”,每深入一层,都需要更全面的知识储备和更严谨的风险评估,真懂Redis的人,不会盲目执行一个在网上搜到的“性能优化”命令,而是会像医生一样,先“望闻问切”准确诊断,再开出针对性的“药方”,并且随时准备好“应急预案”,他们改动的是配置和代码,但背后驾驭的是对内存、网络、磁盘IO和数据一致性的综合理解。 参考和融合了普遍存在的Redis运维实践、开发者社区常见问题讨论以及《Redis设计与实现》等经典书籍中对Redis可配置性和扩展性的阐述)

本文由称怜于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82721.html