Redis真是那个谁啊,NoSQL里一直霸榜不服不行的数据库

直接整理自网络技术社区、开发者论坛及行业技术博文的常见讨论,非原创观点,仅为信息整合。)
Redis真是那个谁啊,NoSQL里一直霸榜不服不行的数据库,这话可不是随便说说的,你去翻翻DB-Engines的数据库排名,Redis在Key-Value存储类别里常年稳坐头把交椅,有时候综合排名也能挤进前十,跟那些老牌关系型数据库掰手腕,作为一个内存型数据库,这地位确实够硬。
为啥Redis能这么牛?首先就得说它的速度,Redis把所有数据都放在内存里操作,读写的速度快的吓人,官方号称能达到每秒几十万次的OPS,这种性能,对付高并发场景,比如电商平台的秒杀、社交媒体的实时消息推送、游戏里的排行榜更新,简直就是量身定做,有程序员开玩笑说,当你觉得系统慢得不行的时候,第一个想到的救命稻草往往就是Redis,很多大厂,像微博、知乎、GitHub,它们的架构里Redis都扮演着至关重要的角色,是扛住海量访问的功臣。
Redis虽然被归为NoSQL,但它可不是个简单的键值对存储那么简单,它支持的数据结构特别丰富,除了最基础的String,还有List、Set、Hash、Sorted Set这些,你别小看这些数据结构,它们让Redis能玩的活儿非常多,比如用List可以做简单的消息队列,用Sorted Set可以轻松实现实时排行榜,用Hash来存储对象信息非常方便,这种灵活性,让Redis的应用场景远远超出了单纯的缓存,很多开发者觉得,Redis更像是一个“数据结构服务器”,你用起来感觉像是在编程语言里操作本地数据结构一样顺手,只不过它是网络化的、持久化的。
再说说它的持久化机制,虽然数据主要存在内存,但Redis提供了RDB和AOF两种方式把数据写到硬盘上,防止服务器重启或者宕机导致数据全部丢失,RDB像是定期给数据拍个快照,AOF则是记录下每一次写操作命令,这种设计在速度和数据安全性之间取得了不错的平衡,让用户可以根据业务需求灵活选择,这也是为什么很多人敢把一些重要的中间状态也放在Redis里的原因。
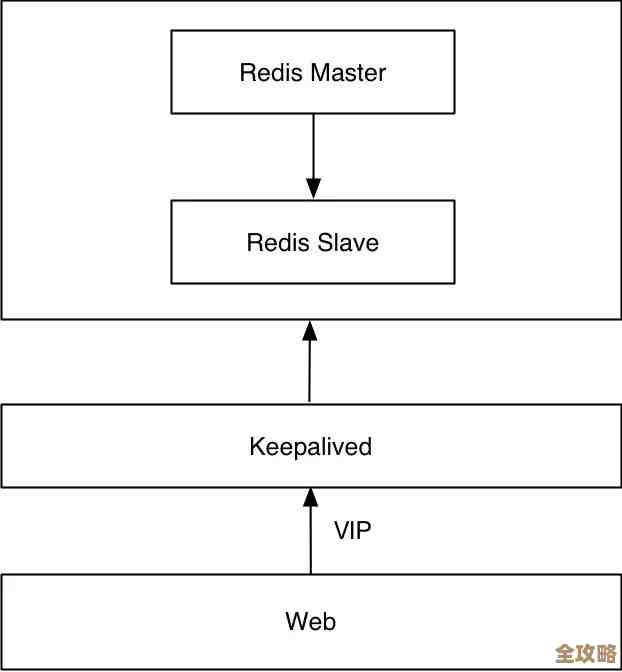
还有主从复制、哨兵模式、集群功能这些,让Redis在保证高性能的同时,也具备了高可用性和可扩展性,当数据量大了,单个实例扛不住了,Redis集群可以横向扩展,把数据分布到多个节点上,哨兵模式能自动监控主节点,一旦挂了,能从节点里选个新的顶上去,保证服务不中断,对于互联网公司来说,这种能力是必不可少的。
Redis也不是没有缺点,比如因为数据都在内存,所以成本比较高,能存的数据量受限于内存大小(虽然现在有了一些扩展方案),它的事务和传统数据库的ACID事务也不太一样,不支持回滚,但在它擅长的领域——高速读写、缓存、会话存储、实时系统这些方面,这些缺点往往是可以接受或者有办法绕开的。
在开发者圈子里,Redis的口碑非常好,它学习曲线平缓,API简单直观,文档也清晰,新手很容易上手,而且社区非常活跃,遇到问题很容易找到解决方案,这种“好用”的特性,也是它能持续流行的重要原因。
综合来看,Redis能在NoSQL领域霸榜这么多年,靠的不是运气,是实打实的性能、灵活性和可靠性,它已经成了现代互联网技术栈里一个几乎绕不开的基础组件,说它“不服不行”,确实一点都不过分。
(以上观点综合自CSDN、知乎、InfoQ、掘金等开发者社区及Redis官方文档相关讨论。)

本文由符海莹于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82045.html