Redis高可用到底怎么搞,简单聊聊那些保证应用不停的技术秘密

说到Redis高可用,说白了就是想办法让Redis服务“打不死”或者“倒了能立刻爬起来”,别让它拖累了整个网站或应用,这就像给Redis上了几道保险,确保它出问题时,业务还能基本正常运转,这里就简单聊聊几种最常见也最实用的技术手段。
最经典、最广为人知的方法就是主从复制配合哨兵模式(来源:Redis官方文档和普遍实践),你可以把它想象成“主仆”模式,你至少需要部署两个Redis实例,一个当“主人”(主节点),其他的当“仆人”(从节点),主节点主要负责处理客户端的写请求(比如新增、修改数据),而从节点则乖乖地、实时地从主节点那里复制数据,保持数据一致,这样一来,从节点就有了主节点数据的完整副本。
读请求怎么办呢?通常可以让应用直接去读主节点,但如果读的压力很大,也可以把一部分读请求分摊到从节点上,这叫“读写分离”,能大大减轻主节点的负担。

但光有主从复制还不够,万一主节点突然“挂掉”了(比如服务器宕机),虽然从节点数据是完整的,但它自己不会主动“上位”变成新的主节点,这时写服务就彻底中断了,我们需要一个“监工”,这就是哨兵。
哨兵本身也是一个或多个独立的进程,它的任务就是像个保安一样,不间断地盯着主节点和从节点是否还“活着”,它会定期向所有Redis节点发送心跳包检查健康状态,一旦哨兵发现主节点失联了,它就会自动触发一套故障转移流程:多个哨兵会开会确认主节点是不是真的挂了(避免误判),然后从众多从节点中选举出一个表现最好的(比如数据最新的那个),把它提升为新的主节点,哨兵还会通知客户端(应用端)这个变化,让客户端把后续的写请求都发到新的主节点上,这套机制基本能实现业务的自动恢复,不需要人工半夜爬起来处理。

主从加哨兵的模式虽然解决了高可用问题,但有个天生的局限:它无法解决数据量特别大的问题,因为每个节点都存储全量数据,写操作只能由主节点进行,无法水平扩展写性能。
为了解决这些问题,另一种更高级的架构就派上用场了——Redis Cluster集群模式(来源:Redis官方解决方案),这个模式可以理解为“分片集群”,它不再区分严格的主仆,而是把数据分散到多个主节点上存储,每个主节点负责整个数据集的一部分(称为一个数据分片),你有100G的数据,可以分成5个20G,分别存储在5个主节点上。

每个主节点同样会有自己的从节点(通常是一到多个),这些从节点负责复制对应主节点的数据,并在主节点故障时顶替上去,保证每个分片的高可用,客户端连接集群时,会拿到一份“数据分布图”,知道哪个key应该到哪个节点上去存取,Redis Cluster会自动处理数据的分布、故障发现和转移、以及集群扩容缩容时数据的迁移。
这种模式既实现了高可用,又通过分片突破了单机内存限制,并且分摊了写压力,是目前处理大规模数据和高并发场景的主流选择。
除了上述两种核心架构,还有一些辅助性的技术也能提升可用性,比如持久化(来源:Redis核心功能),虽然它主要目的是防止数据丢失,但也间接支持了高可用,通过RDB快照和AOF日志两种方式将内存数据保存到硬盘,这样即使所有Redis实例都挂了,重启后也能从磁盘快速恢复数据,不至于从零开始。
在客户端层面也可以做一些优化,比如使用连接池减少连接开销,或者实现本地缓存(如Ehcache、Caffeine)作为Redis的前置缓存,这样即使Redis短暂不可用,应用也能从本地缓存中获取部分数据,起到“挡一下”的缓冲作用,给故障恢复留出时间。
Redis高可用的技术秘密核心在于“冗余”和“自动故障转移”,主从复制是数据冗余的基础,哨兵提供了主节点的自动故障转移能力,而Cluster集群则在更高维度上实现了数据分片和分片内的高可用,根据你的业务数据量、并发量和可用性要求,选择合适的组合方案,就能让Redis服务变得足够坚韧。
本文由召安青于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82077.html
相关文章
-
MSSQL账户权限怎么配合索引建得更好其实挺关键的事儿
-

容器要快又稳,别忘了这些关键点,不然容易出问题
-
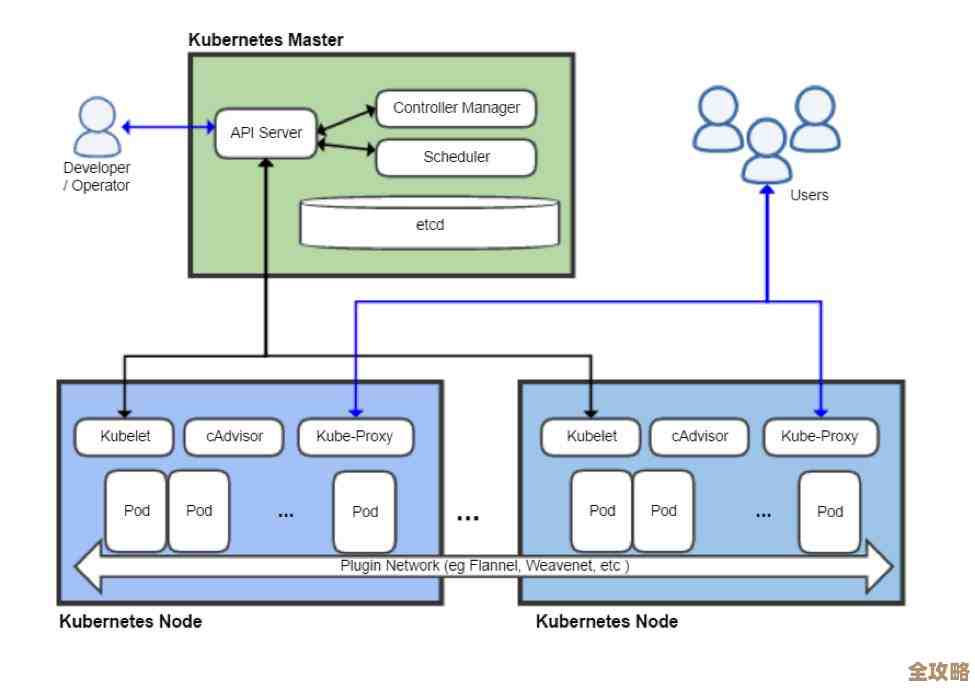
Kubernetes调度器到底怎么挑选节点和安排任务的那些事儿
-

租个MSSQL数据库,商业数据处理其实没那么难,轻松搞定需求真方便
-
PostgreSQL用着用着突然invalid_grant_operation报错了,远程怎么快速修复这故障呢
-
MySQL报错MY-012846和ER_IB_MSG_1021,远程帮忙修复故障全过程分享
-

MySQL报错4047,提示ER_WARN_SQL_AFTER_MTS_GAPS问题,远程帮忙修复故障方案
-
ORA-55468报错,规则库找不到或者没权限,远程帮你解决问题