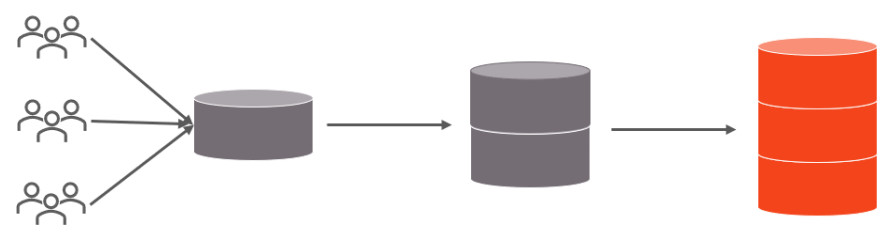
问卷数据到底怎么一步步进数据库,收集完了接下来咋处理存储啥的

你得明白,问卷数据不是自己长腿跑进电脑里的,它需要一个清晰的路径,这个过程就像一条流水线,一步步来,不能乱。
第一步:设计问卷时就要想着怎么收
在你还没把问卷发出去之前,就得定好数据最后的“家”在哪里,这决定了你用什么工具和方式收集。
- 传统老方法:纸质问卷。 这种方式,数据一开始是“睡着”的,存在于一张张纸上,收集完后,需要人工手动把答案录入到电脑里,人们会用Excel表格或者专门的软件(如SPSS、EpiData)来建立一个“电子表格”,每一行代表一份问卷,每一列代表一个问题,这个过程非常耗时,而且容易出错,比如看错打错数字,所以现在除非特殊情况,一般不推荐。
- 现代主流:在线问卷工具。 这是现在最常用的方式,比如用问卷星、腾讯问卷这类平台,你在这些平台上设计好问卷,生成一个链接或二维码发给别人填写。关键点在这里:当你使用这些工具时,数据从被提交的那一刻起,就已经自动进入了这个工具提供商自己的数据库里了,你不需要自己搭建数据库,平台已经帮你做好了,你的数据就存储在它们的服务器上。
第二步:数据收集与初步进入“临时仓库”
无论用什么方法,数据都会先汇集到一个地方,我们可以把它想象成一个“临时仓库”。
- 对于在线问卷工具,这个“临时仓库”就是平台本身的数据库,你作为用户,登录后台就能看到所有回收的问卷原始数据,你可以实时查看回收数量,每个选项的选择比例等初步统计结果,但这时候的数据还是“原始”的,可能存在很多问题,不能直接用来分析。
- 对于纸质问卷,这个“临时仓库”就是你手动录入后形成的那个Excel表格,在录入过程中,严格的质量控制非常重要,最好有专人录入,另一人复核,确保数据准确。
第三步:数据清洗——给数据“洗个澡”
这是整个流程中最关键、最费神的一步,原始数据就像刚从地里挖出来的萝卜,带着泥,必须洗干净才能吃,数据清洗的目的就是处理掉这些“泥”,保证数据的质量和一致性,主要做以下几件事:
- 查缺补漏: 检查是否有空白问卷,或者某道题很多人没回答,你需要决定怎么处理这些缺失值,是删除这份问卷?还是用某种方法(比如用平均值)填充?这个要根据研究的严谨性来决定。
- 排查无效答案: 一道年龄题,有人填了“300岁”;一道单选题,有人却选了多个答案(在线工具通常可避免,但纸质或文本题可能出现),这些明显不合逻辑的答案就是“异常值”,需要找出来并剔除或修正。
- 统一格式: 这点在手动录入时尤其重要,北京”这个词,有人录成“北京市”,有人只写“北京”,在分析时,电脑会认为这是两个不同的地方,所以清洗时需要把所有表述统一成一个标准格式。
- 处理开放题: 如果问卷有“其他,请说明”这类开放题,答案会五花八门,你需要阅读这些文本,对其进行归类编码,问“不喜欢的原因”,有人写“太贵”,有人写“价格高”,你都可以将其归类编码为“1-价格因素”,这样,文本信息就变成了可以统计的数字代码。
数据清洗工作大部分在Excel里通过筛选、排序、替换等功能就能完成,如果数据量大且复杂,可能会用到Python(如Pandas库)或R语言等工具,效率更高。
第四步:数据存储与管理——搬进“正式库房”
数据清洗干净后,就需要把它存放到一个安全、稳定、便于长期使用和分析的地方,这里的选择取决于你的需求和数据量。
- 小规模、一次性分析: 如果你的问卷数据量不大(比如几千条),并且分析目的很简单,做完一次报告可能就不太用了。保存为Excel文件(.xlsx)放在电脑硬盘或云盘(如百度网盘、腾讯微云)上就足够了,这是最简单直接的方式。
- 大规模、需要长期追踪或复杂分析: 如果你的数据量非常大(几十万条以上),或者你的业务需要频繁地调用、分析这些数据,甚至需要把问卷数据和其他数据(如用户购买记录)合并分析,那么就需要用到数据库了。
- 常见的数据库有MySQL、PostgreSQL等。 这些是专门用来存储和管理海量数据的软件,它们的好处是查询速度快、支持多人同时访问、能保证数据的安全和一致性。
- 怎么进去? 通常需要程序员或数据分析师通过编写代码(比如用Python的SQLAlchemy库),或者使用数据库管理工具,将清洗好的Excel或CSV文件“导入”到数据库中,数据在数据库里会被整齐地组织成一张张表,表与表之间可以建立关联。
第五步:数据分析与可视化——从数据里“挖金子”
数据存好了,最后一步就是让它产生价值,根据你的分析目标,使用合适的工具和方法。
- 简单分析: Excel本身就有很强的功能,可以做描述性统计(计算平均值、百分比等)、交叉分析(看不同人群的选择差异)、制作图表(饼图、柱状图等)。
- 高级分析: 如果需要做更深入的推断统计,比如研究变量之间的关系、进行预测等,可能会用到专业的统计分析软件如SPSS,或者编程语言如Python(搭配NumPy, Pandas, Scikit-learn等库)和R语言,这些工具能实现更复杂的模型和算法。
总结一下整个流程就是: 设计问卷(定好收集方式)-> 收集数据(进入临时仓库:在线平台后台或初始Excel)-> 数据清洗(在Excel等工具中去污存真)-> 数据存储(根据情况存为文件或导入专业数据库)-> 数据分析(用Excel或专业工具挖掘洞察)。
整个过程环环相扣,每一步的细心程度都直接决定了最终分析结果的可靠性和价值。

本文由酒紫萱于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79573.html