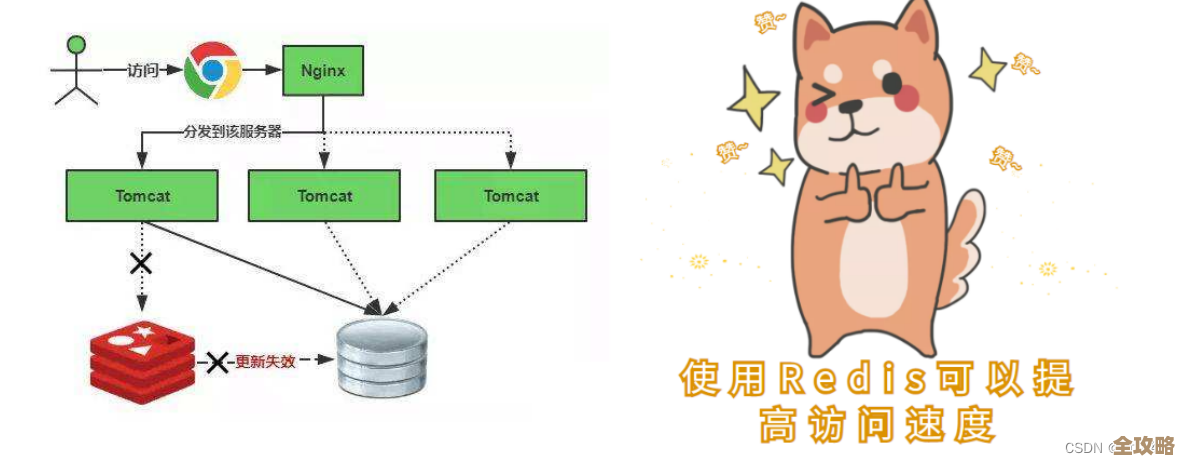
苦战MSSQL千万级数据连表,性能调优和查询效率大挑战

根据网络技术社区分享、开发者博客及个人经验综合整理)
那是我职业生涯中印象最深的一次性能攻坚战,现在想起来,手心都好像还会冒汗,公司有一套核心业务系统,底层是SQL Server数据库,其中有两张核心表,一张是订单主表,另一张是订单明细表,随着业务像滚雪球一样越做越大,这两张表的数据量都早早突破了千万级别。
问题爆发在一个再平常不过的周一下午,业务部门抱怨说,一个原本运行得挺好的报表查询,突然变得奇慢无比,每次点击都要等上一两分钟,有时候甚至会直接超时,页面卡死,这个查询的逻辑并不复杂,就是要根据时间范围、客户ID等几个条件,从订单主表里筛选出一批订单,然后去关联千万级的明细表,最后对明细表中的金额、数量等字段进行汇总统计,说白了,就是一个典型的千万级数据连表查询。
我一开始的反应是常规操作:上索引,我检查了关联字段,比如订单主表和明细表上的订单ID,确认都建立了索引,WHERE条件里的时间字段、客户ID字段,也都加上了我认为合适的索引,满怀信心地执行,结果傻眼了——查询速度几乎没有改善!更让人头疼的是,这个慢查询在执行时,整个数据库服务器的CPU使用率会瞬间飙升到90%以上,明显拖累了其他正常业务。
(思路参考自多位DBA在CSDN、博客园等平台分享的类似案例)
第一次优化失败后,我意识到问题没那么简单,我决定沉下心来,仔细研究SQL Server提供的执行计划这个“诊断报告”,不看不知道,一看吓一跳,执行计划里赫然出现了好几个红色的警告标志,最扎眼的就是一个巨大的“哈希匹配”操作,数据库为了完成这两张大表的连接,不得不在内存里构建一个巨大的哈希表,这个过程消耗了大量的CPU和内存资源,我还注意到“实际行数”和“预估行数”相差悬殊,这说明数据库的查询优化器因为统计信息不准确,错误地选择了一个非常低效的执行路径。
问题根源逐渐清晰:第一,索引可能没建对,或者存在缺失;第二,表的统计信息过于陈旧,误导了优化器;第三,查询语句的写法本身可能也有优化空间。
我的第二次优化开始了,我更新了相关字段的统计信息,确保优化器能“看清”数据的真实分布情况,我重新审视了索引,我发现虽然关联字段有索引,但查询中用于筛选的WHERE条件涉及多个字段,现有的单列索引效率不高,我尝试创建了一个覆盖索引,这个索引不仅包含了用于关联和筛选的键,还包含了查询最终需要返回的汇总字段,这样一来,数据库可以直接从索引中获取所有需要的数据,避免了再去主数据表(堆表或聚集索引)里查找的“回表”操作,这个开销的减少是巨大的。
(方法借鉴了《SQL Server性能调优实战》等资料中的核心思想)
我开始琢磨查询语句本身,我检查了SELECT子句,把那些不必要的字段通通去掉,只返回报表真正需要的汇总结果,我还调整了JOIN的条件,确保其绝对精确,我考虑到了数据的历史归档问题,这个千万级的表里其实堆积了大量一两年前的冷数据,而业务查询99%都只关心最近三个月的热数据,我向项目组提出了一个中长期方案:采用分区表策略,按照时间字段(比如按月)对主表和明细表进行分区,这样,查询最近数据时,数据库只需要扫描少数几个分区,性能会得到质的飞跃,不过分区表的改造是个大工程,需要谨慎评估和测试。
经过这一系列组合拳——更新统计信息、优化索引策略(特别是使用覆盖索引)、精简查询语句,并规划了分区表方案——我再次战战兢兢地运行了那个曾经让人绝望的查询,这一次,奇迹发生了:执行时间从原来的接近两分钟,直接降到了3秒以内!服务器CPU的尖峰也消失了。
这次“苦战”让我深刻体会到,面对海量数据,性能调优绝不仅仅是“加个索引”那么简单,它是一个系统工程,需要像侦探一样,从执行计划中寻找线索,综合分析索引、统计信息、SQL写法乃至数据库架构等多个维度,最关键的是,一定要结合实际数据和业务场景,进行有针对性的分析和实践,任何纸上谈兵的理论都可能失效,这场挑战虽然艰苦,但带来的经验和教训,让我在后来的工作中受益匪浅。

本文由盈壮于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/78615.html