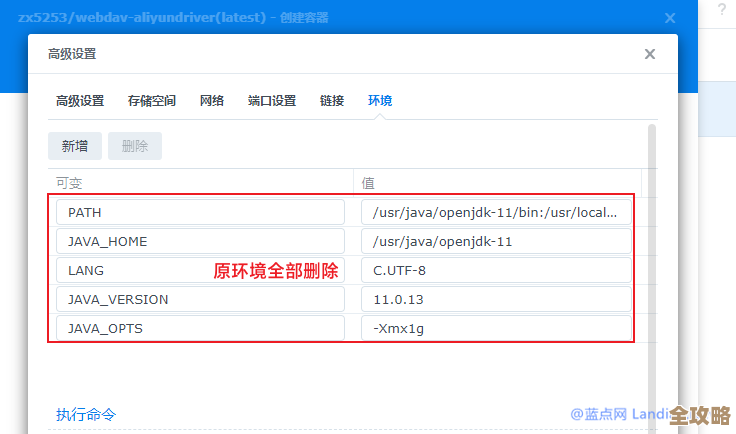
用Redis搞个稳定的任务队列,怎么持续不断地跑起来才靠谱

要使用Redis搞一个稳定的任务队列,并且让它能一直可靠地跑下去,关键在于想清楚任务从生到死的每一个环节可能出什么幺蛾子,然后针对性地解决,这不像写个简单的列表然后弹出元素那么简单,你得考虑各种失败的情况,保证任务不会莫名其妙地消失,下面我们就一步步拆解。
核心思想:任务不能丢,即使处理程序挂了也能重来。
最简单的想法可能是用Redis的列表(List),生产者用LPUSH往列表左边放任务,消费者用RPOP从右边取任务,但这里有个大问题:如果消费者用RPOP拿到任务后,还没来得及处理就崩溃了,这个任务就永远丢失了,因为它在被RPOP的那一刻就已经从Redis里删除了。
第一个关键点来了:不能直接用会删除元素的弹出命令,Redis提供了一个救星命令:BRPOPLPUSH(或者在更新版本中,有功能类似的BLMOVE),这个命令的作用是,从一个列表弹出一个元素,同时把这个元素备份到另一个列表(比如叫“进行中列表”或“处理中列表”),这个操作是原子性的,意味着要么成功,要么失败,不会出现元素从一个列表消失了却没进另一个列表的中间状态。
具体流程是这样的:
- 生产者:依然用
LPUSH将任务放入“待处理任务队列”(比如叫queue:task)。 - 消费者:不使用
RPOP,而是使用BRPOPLPUSH source_queue processing_list timeout,这个命令的意思是:阻塞地(B)从source_queue(即queue:task)中弹出最右边的任务,并立即将其放入processing_list(比如叫queue:processing),如果队列为空,则等待最多timeout秒。 - 消费者成功拿到任务后,开始处理业务逻辑。
- 处理成功后,消费者需要再从
processing_list中把这个任务删除(比如用LREM),表示任务彻底完成。
这样一来,任何时候,所有正在被处理但还没确认完成的任务,都明明白白地躺在queue:processing这个列表里,这是实现可靠性的基石。
光有备份还不够,万一消费者在处理任务中途彻底崩溃了呢?

如果消费者进程在处理任务时突然崩溃,那么这个任务会永远留在queue:processing列表里,没人去删除它,这就成了“幽灵任务”,导致任务实际上没有完成,为了解决这个问题,我们需要引入看门狗或者回溯机制。
你需要有另一个独立的监控进程(或者由消费者进程在启动时自己检查),定期去扫描queue:processing列表,这个监控进程要做什么呢?它需要检查这些“进行中”的任务是否“超时”了。
这里就需要给任务带上“时间戳”,在将任务放入队列时,最好将任务设计成一个JSON字符串,里面除了业务数据,还包含一个比如timestamp字段,记录任务被放入“进行中列表”的时间(或者一个唯一的任务ID也可以用于追踪)。
监控进程的逻辑:

- 定期(比如每分钟)取出
queue:processing列表里的所有任务。 - 检查每个任务的时间戳(或根据任务ID查询其状态)。
- 如果发现某个任务在“进行中列表”里待的时间超过了预设的超时时间(比如5分钟),我们就认为处理它的消费者已经崩溃了。
- 监控进程需要把这个“超时”的任务,从
queue:processing列表里移除,并重新放回queue:task队列的头部(用LPUSH),让其他健康的消费者可以重新处理它。
这个过程通常被称为“任务回溯”,这样就解决了消费者崩溃导致的任务卡死问题。
除了处理过程,生产者和Redis本身也可能出问题。
- 生产者丢任务怎么办? 生产者调用
LPUSH后,应该检查Redis的返回值,确保任务添加成功,如果失败(比如网络问题或Redis宕机),生产者需要有重试机制,对于极其重要的任务,生产者甚至可以先把任务持久化到自己的数据库,再发往Redis,这样即使Redis暂时不可用,之后也能恢复。 - Redis宕机了怎么办? Redis挂了,内存里的任务就全没了,这是最严重的情况。必须开启Redis的持久化功能,Redis有两种主要持久化方式:RDB(定时快照)和AOF(记录每一条写命令),对于任务队列这种场景,建议至少开启AOF,并且设置
appendfsync为everysec,这样最多丢失1秒钟的数据,虽然会牺牲一点点性能,但换来了数据的安全性,对于要求更高的场景,甚至可以搭建Redis主从复制(Replication)和哨兵(Sentinel)机制,实现高可用,主节点挂了,从节点能顶上去。
让整个系统持续不断地跑起来
上面说的都是核心机制,要让整个系统7x24小时稳定运行,还需要在部署和运维上下功夫:
- 消费者进程要足够健壮:你的消费者程序不能有内存泄漏,不能被一个异常任务就打得整个进程退出,要用
try...catch捕获所有可能的异常,确保即使某个任务处理失败,进程也只是记录日志并继续处理下一个任务,对于处理失败的任务,可以放入一个“失败队列”供后续排查,而不是让进程崩溃。 - 消费者需要多开:只运行一个消费者进程是单点,一旦它挂了,整个队列就停了,一定要启动多个消费者进程(甚至是跨机器的),让他们同时从Redis队列里抢任务,Redis的列表操作是原子的,所以不用担心任务被重复消费,
BRPOPLPUSH命令会保证一个任务只会被一个消费者拿到。 - 要有监控和告警:监控几个关键指标:
queue:task的长度:如果这个队列长度持续增长,说明生产者速度大于消费者,可能消费者处理能力不足或者出问题了。queue:processing的长度和任务停留时间:如果这里有大量超时任务,说明消费者集群可能出现了大面积故障。- Redis的内存和连接数使用情况。 一旦这些指标出现异常,要能及时发出告警(比如发邮件、短信),让运维人员能第一时间介入。
一个靠谱的Redis任务队列,核心是BRPOPLPUSH命令+处理中列表+超时回溯机制,在此基础上,通过Redis持久化保证数据不丢,通过多消费者实例避免单点故障,通过完善的监控告警系统来发现潜在问题,把这些环节都做好了,你的任务队列就能稳定、持续地跑下去了。
本文由召安青于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/78838.html