用Redis来缓解数据库锁表问题,避免因锁表导致系统卡顿和性能下降

在现代的软件系统中,数据库往往是承载核心数据和处理关键业务逻辑的地方,当大量用户同时访问系统,尤其是进行写操作(比如抢购商品、更新同一用户的账户余额、秒杀活动等)时,数据库为了保证数据的一致性,会使用“锁”的机制,这就好比一个房间(数据行或整张表)一次只允许一个人(一个数据库连接)进去修改东西,其他人必须在门口排队等候,当排队的人太多,或者里面的人待的时间太长(执行复杂的更新操作或事务未及时提交),门口就会堵得水泄不通,导致整个系统响应变得极慢,甚至完全卡死,这就是我们常说的“锁表”问题,锁表会直接导致用户体验变差,业务无法正常进行。
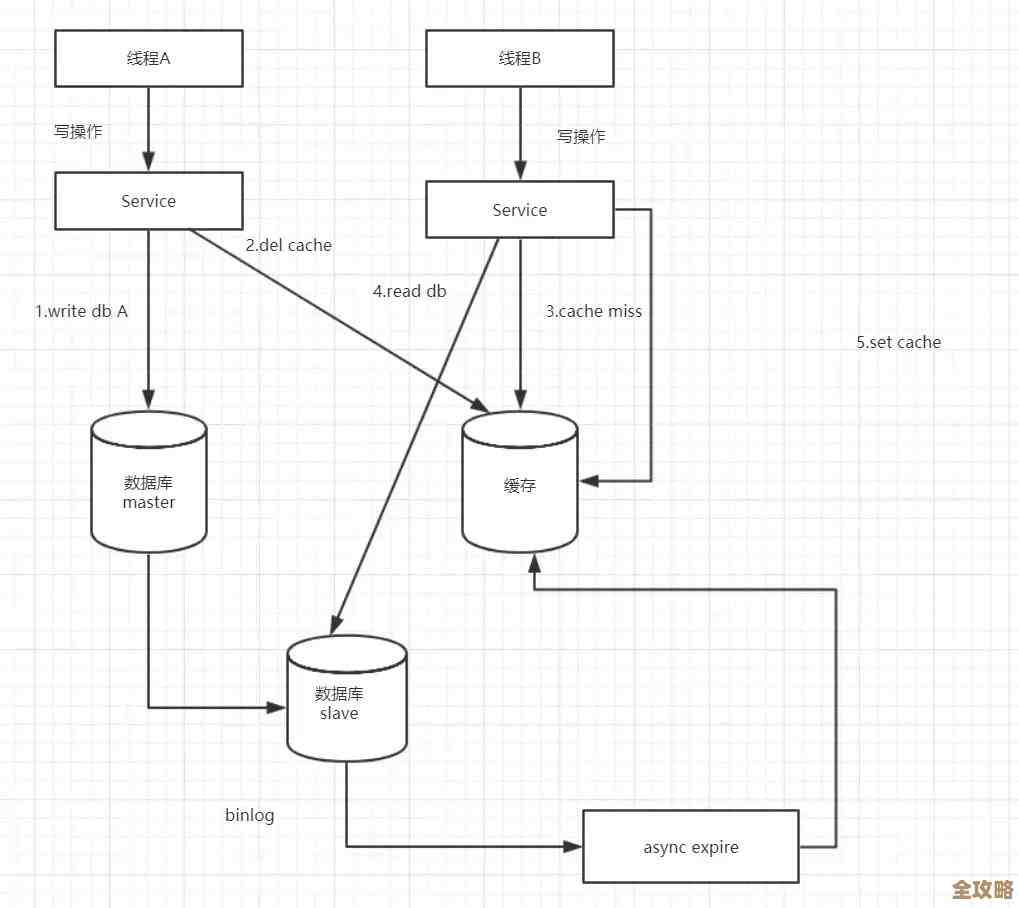
为了解决这个问题,一个有效的方法就是引入Redis,Redis是一个基于内存的数据存储,它的读写速度极快,比基于磁盘的传统数据库(如MySQL)要快几个数量级,我们可以利用Redis的这个特性,将一部分原本直接由数据库承担的、容易引起锁表压力的操作,“拦截”在数据库之前,从而保护数据库,缓解锁表问题,这就像在通往房间的狭窄走廊上设置了一个宽敞的预备大厅(Redis),先让大部分人在大厅里进行初步处理和排队,然后有秩序地、少量地放人进入房间,这样就避免了门口的直接拥堵。
利用Redis缓解锁表主要有以下几种常见的思路和做法:
第一,使用Redis作为高速缓存,减少数据库的直接读压力。 虽然读操作本身通常不会加写锁,但高并发的读操作会占用大量的数据库连接资源,可能间接影响写操作的执行,加剧锁表现象,我们可以把那些频繁读取但又不经常变化的数据(例如商品分类信息、用户的基本信息、热点文章内容等)缓存到Redis中,当应用程序需要这些数据时,首先去Redis中查找,如果找到(缓存命中)就直接返回,不再访问数据库,只有Redis中没有时,才去数据库查询,并将结果写入Redis以备后续使用,这样一来,绝大部分的读请求都被Redis消化掉了,数据库的压力骤减,能够更专注、更快速地处理那些必须由它来完成的写操作,从而降低了因资源竞争导致锁表的概率,这种做法是应用Redis最广泛、最基础的场景。
第二,使用Redis实现简单的锁机制(如SETNX命令),将分布式锁前置。
在某些需要强一致性的写操作场景下,锁是不可避免的,但我们不一定要用数据库的行锁或表锁,可以尝试用Redis来实现一个分布式的锁,在秒杀系统中,为了防止超卖,必须确保每个商品库存的扣减是原子性的,传统做法是在数据库事务中通过select ... for update锁定商品库存行,然后更新,在高并发下,大量事务竞争同一行锁,极易造成锁等待和数据库卡顿。
我们可以改用Redis:每个商品ID对应一个Redis键,当用户发起秒杀请求时,应用程序首先尝试用SETNX命令去设置这个键(如果键不存在则设置成功,表示获取锁成功),只有一个用户能设置成功,他获得了“购买资格”,获得资格的用户再去数据库执行真实的库存扣减和订单创建流程,其他没有抢到锁的用户则直接返回失败或提示已售罄,通过这种方式,我们将成千上万的并发请求拦截在了Redis这一层,最终落到数据库上的写操作被控制在了库存数量这个可控的范围内(比如100个商品最多只有100个写请求),数据库的压力变得非常小,根本不会发生严重的锁表,这种模式也被称为“逻辑锁前置”或“缓冲队列”。
第三,利用Redis的数据结构和原子操作,在内存中完成计算。
对于一些可以接受最终一致性的计数类、统计类操作,我们甚至可以完全避免在高峰期直接写数据库,Redis提供了丰富的原子操作(如INCR, DECR, HINCRBY等),可以保证在多线程并发环境下安全地执行计算。
举个例子,比如文章的点赞数、视频的播放次数,如果用户每点一次赞,我们都直接去数据库执行UPDATE articles SET likes = likes + 1 WHERE id = ?,在高流量下,这篇热门文章的数据行会频繁被锁,影响其他读取该文章的操作,我们可以换个思路:在Redis中用一个键(如article_like:{文章ID})来存储点赞数,用户点赞时,只需执行INCR命令,这个操作在内存中瞬间完成,速度极快,且不会阻塞,我们可以通过一个后台任务,定时(比如每5分钟)将Redis中的点赞数同步到数据库中,这样,就将一个高频的、离散的数据库写操作,转化为了一个低频的、批量的更新操作,彻底避免了在数据库层面因热点数据更新导致的锁表问题。
需要注意的问题 引入Redis也不是银弹,它带来了新的复杂性,数据一致性需要仔细设计,缓存和数据库之间的数据可能短暂不一致(最终一致性),Redis是内存数据库,需要考虑数据的持久化策略和宕机恢复方案,避免数据丢失,Redis本身也可能成为瓶颈,需要做集群化部署来保证高可用。
通过将Redis作为数据库前面的一个高速缓冲层,通过缓存读请求、前置分布式锁、内存计算异步持久化等策略,可以有效地将高并发流量进行“削峰填谷”,大幅减少数据库在同一时刻面临的并发写压力和锁竞争,这样做的核心思想是“空间换时间”和“分层过滤”,让每个组件(Redis和数据库)专注于自己最擅长的领域(内存高速读写和磁盘数据持久化),从而从整体上提升系统的吞吐能力,避免因数据库锁表导致的系统卡顿和性能下降问题。

本文由盈壮于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/78461.html