ORA-26021报错提示索引分区加载成功但键异常,远程帮忙修复故障中

开始)
用户打电话过来,声音很着急,说他们的数据库在做一个数据加载的操作,具体是用SQL*Loader往一个很大的表里灌数据,这个表是分了区的,就是按照时间,比如每个月的数据放在一个分区里,操作完成之后,系统提示说索引的分区加载是成功的,但是紧接着就报了一个ORA-26021的错误,用户说错误信息里提到了“键”有问题,他们自己尝试了一些方法,比如重建索引,但有时候能成功,有时候又会报别的错,问题好像会反复出现,所以他们需要远程帮忙赶紧修复这个故障,因为这会影响到后续的业务报表生成。
我让用户把完整的错误信息截图发过来,ORA-26021的错误描述,根据Oracle官方文档的说明,指的是在试图更新一个不可用的索引时发生的,具体到这种情况,索引分区状态显示是“USABLE”(可用的),但实际索引条目可能已经损坏或不一致,导致数据库无法正常使用这个索引,所以报了“键”异常。“键”在这里指的就是索引里面用来快速查找数据的那一列或多列的值。
结合用户说的用SQLLoader加载数据,我初步判断问题很可能出在加载数据的方式上,我详细询问了用户他们使用的SQLLoader的控制文件是怎么写的,用户提供了控制文件的内容,我注意到里面有一个关键参数:SKIP_INDEX_MAINTENANCE=TRUE,这个参数的意思是,在加载数据的过程中,为了追求加载速度,暂时跳过对相关索引的维护,也就是说,数据直接灌进了表的分区里,但对应的索引分区并没有同步更新。

用户解释说,他们知道这个参数的作用,所以他们在数据加载完成后,手动执行了了一条语句来重建这个索引分区,比如ALTER INDEX idx_name REBUILD PARTITION partition_name;,奇怪的是,执行这个重建语句时,系统有时候能成功,但有时候会报出ORA-26021的错误,甚至有时会报出其他关于唯一性约束冲突的错误(比如ORA-00001),这正是问题的诡异之处,也是用户感到困惑的地方。
我告诉用户,这种情况的根本原因在于数据本身可能存在问题,当设置SKIP_INDEX_MAINTENANCE=TRUE后,SQL*Loader会忽略所有与索引相关的检查,包括唯一性约束检查,这意味着,在加载数据的过程中,很有可能有一些重复的数据被直接加载到了基础表里,这些重复的数据违反了索引的唯一性约束(如果索引是唯一索引的话),但因为在加载时跳过了检查,所以当时没有报错。
当我们事后去重建索引时,数据库会尝试根据表里的实际数据来重新构建索引条目,一旦它尝试为那些重复的数据创建索引,就会立刻发现违反了唯一性规则,从而抛出ORA-26021或其他约束冲突的错误,重建索引有时能成功,有时失败,这完全取决于当时加载的数据中是否包含了重复记录,以及重复记录的多少和分布情况,这可能解释了为什么问题会时而出现,时而又好像正常了。

为了确认这个判断,我指导用户进行以下排查步骤,我让他们检查这个索引是否是唯一索引,用户确认了,这个索引确实是一个唯一索引,是基于几个业务字段组合起来保证唯一的,这进一步印证了我的猜测。
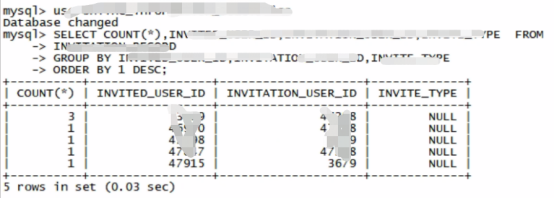
最关键的一步是检查基础表分区中是否存在重复数据,我让用户执行了一个查询,根据索引定义的几个列进行分组计数,查找计数大于1的记录,查询语句类似于:SELECT col1, col2, col3, COUNT(*) FROM table_name PARTITION (partition_name) GROUP BY col1, col2, col3 HAVING COUNT(*) > 1;,用户执行后,果然返回了几条记录,明确显示在刚刚加载的数据分区里,存在重复的“键”值,这就是导致索引重建失败的“罪魁祸首”。
问题根源找到了,解决方案就清晰了,我们需要先清理掉表里的重复数据,然后再重建索引,我向用户解释了两种处理重复数据的常见思路:

第一种思路是,如果这些重复数据是完全多余的,也就是说不应该存在任何重复,那么就需要删除重复项,只保留一条,我提供了一个标准的删除重复记录的SQL脚本模板,利用ROWID来区分重复记录中的不同行,只保留ROWID最小(或最大)的那一条,删除其他重复行,我提醒用户,在执行删除操作前,务必确认好要保留哪条数据,如果业务上有其他判断标准,需要修改脚本的逻辑,最重要的是,强烈建议他们先对这个数据分区做一个备份,比如通过CREATE TABLE table_backup AS SELECT * FROM table_name PARTITION (partition_name);,以防误删。
第二种思路是,如果经过业务确认,这些“重复”数据可能是有意义的,或者是因为数据来源本身就有问题,那么就需要联系业务部门澄清数据的准确性,在数据问题解决之前,可能无法重建唯一索引。
用户根据业务规则判断,这些重复数据属于无效数据,可以删除,于是他们采用了第一种方案,在我的指导下,他们先备份了数据,然后谨慎地执行了删除重复记录的语句,执行完毕后,再次运行检查重复数据的查询,确认重复项已经被清除。
我让用户再次执行索引分区重建命令:ALTER INDEX idx_name REBUILD PARTITION partition_name;,这次命令很快执行成功,没有报任何错误,用户随后进行了一些简单的查询测试,验证了索引确实已经恢复正常,查询速度也回到了预期水平。
总结这次远程故障修复,根本原因在于为了追求数据加载性能而使用了SKIP_INDEX_MAINTENANCE参数,但数据源本身存在质量问题(重复记录),导致了索引状态不一致,给用户的建议是,以后在使用类似跳过索引维护的功能时,一定要确保数据源的清洁度,或者在加载完成后,先系统性地检查数据质量,然后再处理索引,如果无法保证数据源绝对干净,可能需要在加载过程中保持索引维护开启,虽然会牺牲一些性能,但能保证数据的即时一致性。 结束)
本文由太叔访天于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74990.html