Redis架构那些事儿,聊聊它到底是怎么设计和运行的原理

主要参考自Redis官方文档、经典技术书籍《Redis设计与实现》以及多位资深技术博主如“程序员小灰”、“小林coding”等的解读文章)
Redis的事儿,咱们可以从它为什么这么快开始聊,很多人一提到Redis,第一反应就是“快”,但它到底快在哪儿呢?这得从它的“地基”说起。

Redis是个“内存仔”,它把所有数据都放在电脑的内存里,内存的读写速度,比去硬盘上找数据要快成千上万倍,这就好比你要查字典,Redis是把整本字典都背下来了,张口就来;而传统数据库还得去书架上翻书,自然慢得多,但这也带来了一个核心问题:内存贵且断电后数据就没了,所以Redis也得想办法把数据存到硬盘上以防万一,这个我们后面再说。
光有内存还不够,怎么高效地用内存是关键,这就引出了Redis的第二个特点:它自己构建了一套非常精炼的“数据结构”,不像传统数据库用表格那种复杂结构,Redis给你的是一些直接好用的“小工具”,比如简单的字符串(String)、列表(List)、哈希表(Hash)、集合(Set)等等,这些数据结构在内存中的组织方式非常高效,是Redis速度的灵魂,比如它的哈希表,在数据量小的时候用一种紧凑的方式存储,节省空间;数据量变大后,又能平滑地转换成真正的哈希表结构,保证查找速度,这种对细节的优化无处不在。

第三,Redis是“单线程”干核心活的,你可能纳闷了,单线程不是容易堵车吗?为啥还快?这里有个关键点要分清:Redis处理网络请求和执行命令的核心模块,是用的一个线程,这意味着,它不用像多线程程序那样,费劲去处理“锁”的问题——多个线程同时改一个数据会打架,单线程就简单多了,所有命令排着队,一个一个处理,避免了上下文的切换和竞争条件,反而非常利索,这并不是说Redis完全不用其他线程,在最新的版本中,像一些耗时的操作,比如把数据持久化到硬盘(快照)、删除大Key等,它会用额外的后台线程去处理,不耽误主线程接待客户。
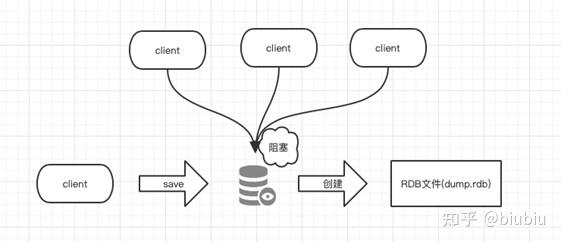
说到持久化,这就是Redis解决“内存数据易失”的法宝,它主要有两种方式,相当于给内存数据拍照片,第一种叫RDB(快照),就像是在某个时间点,给整个数据库“咔嚓”拍一张完整的照片存起来,这个照片文件比较紧凑,恢复起来快,但缺点是两次拍照之间的数据可能会丢失,第二种叫AOF(追加日志),它不拍照片,而是拿个小本本记下所有修改数据库的命令,这样即使服务器宕机,重启后只要把本子上的命令重新执行一遍,就能恢复数据,数据安全性高,但日志文件会越来越大,恢复起来也慢,所以生产环境 often 两者结合使用,取长补短。
当数据量特别大,或者需要承受超高并发时,一台Redis服务器可能就顶不住了,这时候就需要“分布式架构”,也就是Redis集群,它的思路很简单:把一大锅数据,分到好几个小锅(不同的Redis实例)里去煮,Redis集群通过一种叫“哈希槽”的机制来分锅,整个数据库被分成16384个槽位,每个键值对根据key计算出来一个值,决定它属于哪个槽,然后这些槽被合理地分配给集群中的每个节点,这样,当你访问一个key时,客户端就能知道该去找集群里的哪台机器了,实现了数据的分散存储和负载均衡。
Redis还有“主从复制”这个法宝,就是让一台Redis服务器(主节点)的数据,自动同步到其他几台(从节点)上去,这样做有两个大好处:一是读写分离,写的操作都交给主节点,读的操作可以分散到从节点,提升整体读的能力;二是高可用,万一主节点宕机了,可以从从节点中选一个新的主节点出来,继续提供服务,保证系统不瘫痪。
总结一下Redis的设计哲学:一切为了速度,通过内存存储、高效的数据结构、单线程模型减少内部损耗,再辅以持久化机制保证数据安全,用集群和主从模式来突破单机限制,它就像一个精心设计的现代化厨房,每个环节都力求高效、直接,没有多余的动作,这才造就了其极高的性能。

本文由邝冷亦于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72291.html