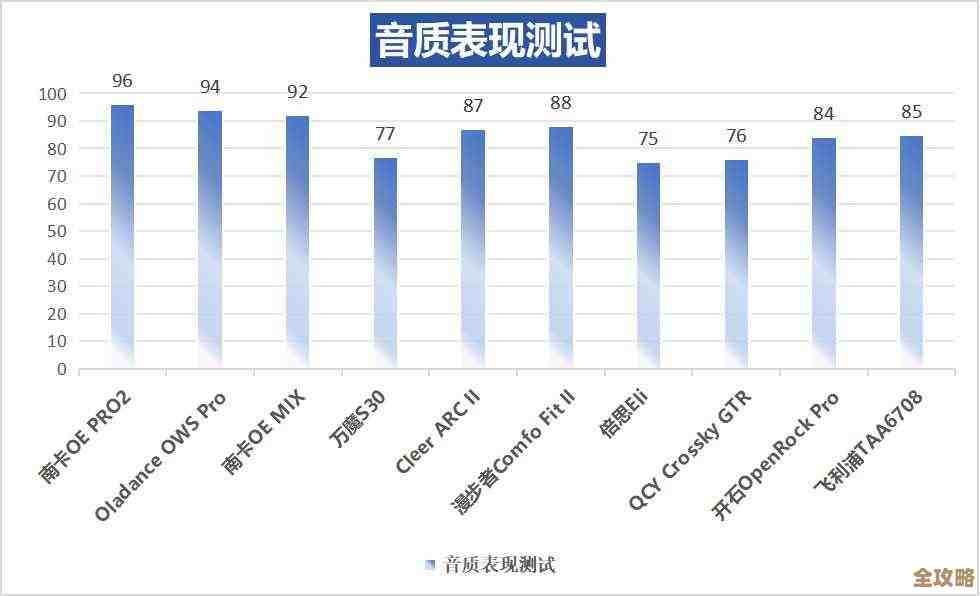
用Redis统计函数来搞数据统计,效率和性能能不能提升点儿?

用Redis来搞数据统计,确实能在很多场景下让效率和性能得到非常明显的提升,但这并不意味着它能完全替代传统的数据库,说白了,它就是一把锋利的“瑞士军刀”,在特定的任务上比“大砍刀”(传统数据库)更好用,下面我们就来具体聊聊它为什么快,以及怎么用它来统计。
核心优势:为什么Redis这么快?
这得从它的老本行说起,Redis首先是一个内存数据库(来自:Redis官方文档对其架构的描述),这意味着所有数据都直接放在服务器的内存里,而内存的读写速度,和我们平常电脑硬盘或者数据库服务器的硬盘比起来,那不是一个数量级的,硬盘读写,特别是随机读写,需要磁头寻道等机械操作,速度慢得多,而内存是电子的,直接通过电路访问,速度极快,当你做统计时,需要频繁地读写数据,比如增加一个计数、记录一个状态,Redis直接在内存里完成,自然就快了。
另一个关键是它单线程的模型(来自:Redis官方对单线程模型的说明),听起来单线程好像会慢,但其实避免了多线程环境下复杂的锁竞争和上下文切换带来的开销,对于Redis这种主要操作都是内存读写的场景,CPU很少成为瓶颈,网络和内存速度才是,单线程模型让Redis的实现变得简单高效,它按顺序处理所有命令,不会出现并发问题,这也为我们做数据统计提供了便利,比如计数操作本身就是原子的,不用担心出错。
实战场景:Redis怎么帮我们做统计?
光说不练假把式,我们看看Redis具体能做什么样的统计。
-
实时计数:这是最经典的场景。 比如统计网站的实时在线人数、一篇帖子的点赞数、一个视频的播放量,如果用传统数据库,每次有人点赞你都去数据库里
UPDATE article SET likes = likes + 1 WHERE id = 123,数据库的磁盘IO和锁机制在高并发下很快就会成为瓶颈,而在Redis里,你只需要一个简单的命令INCR article:123:likes,这个操作在内存中完成,是原子性的(不会有两个请求同时读到同一个值然后加一导致计数不准),速度极快,你需要看结果时,再用GET article:123:likes直接读出来就行。 -
唯一性统计:比如统计一篇新闻文章的独立访客数(UV)。 传统做法可能是在数据库里记录每次访问的IP或用户ID,然后用
DISTINCT关键字去重计数,数据量一大,这个查询会非常慢,Redis提供了HyperLogLog这种数据结构(来自:Redis命令参考中对PFADD/PFCOUNT的介绍),它最大的优点是占用空间极小,只需要12KB内存,就能统计接近2^64个不重复元素,并且误差率不到1%,你只需要用PFADD article:123:uv user_id_1 user_id_2来添加用户,然后用PFCOUNT article:123:uv来获取大概的独立用户数,对于不需要100%精确,但要求高效率、低存储成本的场景,比如大盘数据的UV统计,这简直是神器。 -
排序统计:比如搞个实时排行榜。 游戏里的玩家积分榜、电商商品的销量榜,如果用数据库,你可能要频繁地
ORDER BY score DESC LIMIT 100,对数据库压力很大,Redis的ZSET(有序集合)天生就是干这个的,每次用户得分更新,你用ZADD ranking score user_id,数据会自动按照分数排序,要看Top 100?直接用ZREVRANGE ranking 0 99 WITHSCORES,瞬间返回,效率极高。 -
区间统计和频率统计:比如统计一天内用户登录的分布情况(每小时登录人数)。 传统方法可能得写个复杂的SQL分组查询,Redis的
Bitmap(位图)可以很巧妙地解决,你可以把每一天的24小时看成24个位(bit),用户ID假设是数字,在每小时整点,如果用户登录了,就用SETBIT login:20231027 15(假设用户ID是15,小时是10点)将对应位置设为1,统计第10小时有多少人登录?一个BITCOUNT login:20231027命令就出来了,这种方式极其节省空间,且统计速度飞快。
Redis也不是万能的,它有它的局限性:
- 内存限制: 数据都放内存,成本比硬盘高,虽然Redis有各种数据结构优化内存使用,但海量数据存储还是得靠传统数据库。
- 持久化问题: 虽然Redis有持久化机制(RDB快照和AOF日志),但和传统数据库的ACID特性相比,在数据可靠性上还是有差距,它更适合做缓存和允许少量数据丢失的实时统计。
- 复杂查询能力弱: Redis没有SQL那样强大的查询语言,你很难执行像“查找所有点赞数超过100且发布时间在今天内的文章”这样的复杂关联查询,这种工作最好还是交给关系数据库。
用Redis来做数据统计,在需要高并发、低延迟、实时性的“轻量级”统计任务上,效率和性能的提升是巨大的,它通过内存操作和高效的数据结构,把那些频繁、简单的计数、排序、去重操作变得飞快,正确的做法往往是“分工合作”:让Redis扛住前线的实时数据写入和简单的实时查询,然后把聚合后的结果定期同步到传统数据库里,用于做更复杂的离线分析和报表生成,这样各取所长,整个系统的性能和功能就都能得到保障,如果你的项目正被频繁的数据统计操作拖慢,引入Redis绝对是一个值得认真考虑的优化方案。

本文由盘雅霜于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71577.html