Redis面试资料全收录,网盘里有你想要的那些干货和技巧分享

Redis面试资料全收录
Redis到底是什么?能干什么?参考了“JavaGuide”和众多技术博客的开篇介绍) Redis,简单说就是一个速度超级快的“内存数据库”,它把所有数据都放在内存里操作,所以读写速度比传统硬盘数据库(比如MySQL)快得多,能达到每秒几十万次操作,它常被用来做两件事:

- 缓存:这是最常用的场景,把MySQL等数据库中经常被查询的热点数据放到Redis里,下次查询直接读Redis,极大减轻后端数据库的压力,加快网站响应速度。
- 分布式锁:在分布式系统(多个服务实例)中,为了保证同一时间只有一个服务能操作某项资源(比如秒杀时扣减库存),可以用Redis实现一个简单的锁机制。
为什么Redis这么快? (这个问题是面试必问的,答案要点综合了“小林coding”和经典面试题解析)
- 基于内存:内存的访问速度是纳秒级别的,而硬盘是毫秒级别的,差了好几个数量级,这是Redis快的根本原因。
- 单线程模型:Redis的核心网络模型是单线程的(新版本引入了多线程处理某些IO,但核心命令处理还是单线程),这意味着它不用考虑多线程带来的锁竞争、上下文切换等开销,避免了不必要的性能损耗,很多人误以为单线程是弱点,其实在内存操作下,CPU很少成为瓶颈,单线程反而简化了实现,保证了原子性。
- 高效的数据结构:Redis内置了多种优化过的数据结构,比如简单动态字符串(SDS)、跳跃表(SkipList)等,这些结构的设计就是为了追求极致的速度。
- IO多路复用:Redis使用epoll这样的IO多路复用技术,用一个线程来监控大量的客户端连接,哪个连接有数据来了就处理哪个,避免了为每个连接创建线程的开销,非常适合高并发的场景。
Redis有哪些数据类型?分别用在什么场景? (这部分是基础,所有资料都会讲,但“程序员小灰”会用更生动的例子解释) 别只知道String和List,面试官喜欢问得深。

- String(字符串):最基础的类型,可以存字符串、整数、浮点数,常用场景:缓存用户信息(JSON序列化后存入)、计数器(文章的点赞数,用INCR命令非常方便)。
- List(列表):一个双向链表,常用场景:消息队列(LPUSH生产消息,RPOP消费消息,但有不完善的地方)、最新文章列表(LPUSH加入新文章,LTRIM截取最新的N条)。
- Hash(哈希):类似Java里的Map,适合存储对象,比如存储用户信息,可以用一个用户ID作为key,用户的姓名、年龄、邮箱等作为field-value对,这样比将整个对象序列化成JSON字符串再存为String,更方便修改某个字段。
- Set(集合):无序且元素唯一,常用场景:共同关注(求两个用户的关注交集)、抽奖(SADD加入参与者,SRANDMEMBER随机抽奖)。
- ZSet(有序集合):带分数的Set,可以根据分数排序,这是Redis的王牌数据结构,常用场景:排行榜(以文章ID为member,点击量为score,自动排序)、延时队列(用时间戳作为score,到期处理)。
- Bitmaps(位图):本质是String,但可以按位操作,常用场景:统计用户签到情况(每一天对应一个bit,签到则为1)、大数据量的布尔统计(如日活用户)。
- HyperLogLog:用于做基数统计,即估算一个集合中不重复元素的个数,特点是占用空间极小,但有小于1%的误差,常用场景:统计UV(网站独立访客数)。
- Geospatial:用于存储地理位置信息,并支持距离计算、范围查询等,常用场景:附近的人、打车软件找附近的车。
Redis的持久化机制怎么选? (这个问题涉及数据安全,参考了“阿里云开发者社区”和“Redis实战”相关的讨论) 数据都在内存里,服务器重启或宕机不就全没了吗?所以需要持久化到硬盘,Redis主要有两种方式:
- RDB(快照):在指定的时间间隔内,生成内存数据的一个完整快照文件(dump.rdb)。优点:文件紧凑,恢复大数据集速度极快。缺点:可能会丢失最后一次快照之后的数据(比如5分钟持久化一次,宕机就会丢失最近5分钟的数据)。
- AOF(追加日志):记录每一次写操作命令,以日志的形式追加到文件末尾。优点:数据安全性高,最多丢失1秒的数据(可配置)。缺点:AOF文件通常比RDB文件大,恢复速度慢。
怎么选? 通常两者结合使用,用AOF来保证数据不丢失,作为数据恢复的第一选择;用RDB来做冷备,便于快速恢复和灾难恢复。

缓存穿透、击穿、雪崩是什么?怎么解决? (这是缓存经典难题,几乎每份面试资料都会重点讲,思路大同小异)
- 缓存穿透:查询一个根本不存在的数据,缓存和数据库都没有,导致每次请求都直接打到数据库上,像“穿透”了缓存。解决:① 对不存在的key也缓存一个空值(设置短过期时间)。② 使用布隆过滤器(Bloom Filter)在缓存前做一层拦截,快速判断key是否存在。
- 缓存击穿:一个热点key突然过期,此时有大量并发请求这个key,请求全部打到数据库,造成数据库压力激增。解决:① 设置热点key永不过期。② 使用互斥锁(Mutex Lock),只让一个请求去数据库加载数据,其他请求等待。
- 缓存雪崩:同一时间大量缓存key集体过期,或者Redis服务器宕机,导致所有请求都涌向数据库,导致数据库崩溃。解决:① 给缓存过期时间加上随机值,避免同时过期。② 搭建Redis集群,实现高可用。③ 服务降级和熔断机制,保护数据库。
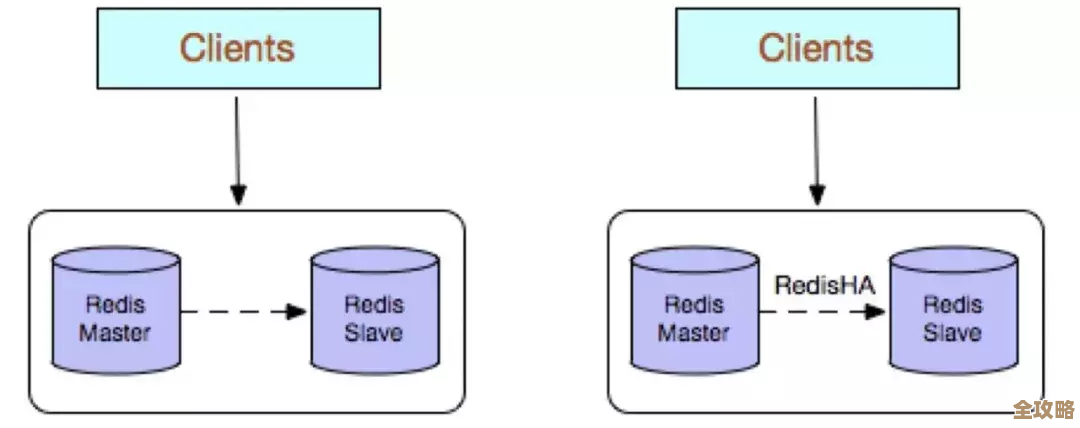
Redis如何保证高可用? (参考了关于Redis主从复制和哨兵模式的常见讲解) 单机Redis有宕机风险,所以需要集群方案。
- 主从复制(Replication):一个主节点(Master)负责写,多个从节点(Slave)负责读和备份,数据从主节点同步到从节点,这实现了读写分离和数据备份,但主节点宕机需要手动切换。
- 哨兵模式(Sentinel):哨兵是一个独立的进程,它监控主从节点的健康状态,当发现主节点宕机时,它能自动将一个从节点提升为新的主节点,让客户端切换到新的主节点上写作,实现了自动故障转移,这是常用的高可用方案。
- 集群模式(Cluster):官方提供的分布式方案,将数据分片存储在多个节点上,每个节点存储一部分数据,通过 gossip 协议进行通信和故障检测,可以水平扩展,能承受更大的数据量和并发量。
实战技巧和注意事项 (这些是来自一些面试官的经验分享和最佳实践总结)
- Key的设计:遵循可读性、简洁性、统一性原则,
业务名:对象名:id:[属性],user:info:123,order:list:20231001。 - 避免大Key:一个key对应的value非常大(比如一个List存了100万条数据),会导致操作缓慢、网络阻塞,需要拆分或使用其他数据结构。
- 避免热Key:某个key被超高并发访问,可能导致单个服务器压力过大,解决方法:复制多份key,
key:01,key:02,客户端随机访问。 - 内存淘汰策略:当内存不足时,Redis会根据配置的策略(如LRU-最近最少使用)删除一些key,保证服务可用,需要根据业务场景合理配置。
本文由瞿欣合于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71629.html