Redis怎么能更快读写数据,效率提升那些事儿你知道吗?

关于Redis怎么能更快读写数据,效率提升那些事儿,其实可以从几个贴近我们日常使用习惯的角度来理解,这就像打理一个仓库,东西乱放、钥匙不好找,存取速度自然就慢;但如果规划得当,用起来就飞快。

最基础也最重要的一点,就是给你的Redis“上把好锁”,但又不是真的锁死它,这里说的是持久化策略的选择,Redis有两种主要方式把内存数据存到硬盘上,防止断电丢失:一种叫RDB,像是给仓库拍张快照,定期执行,速度快但可能会丢失最近几分钟的数据;另一种叫AOF,像是记流水账,每次操作都记录下来,更安全但文件大,恢复慢,根据“Redis设计与实现”这本书里的建议,想要读写更快,尤其是在数据安全可承受一定风险的情况下,可以优先考虑RDB,或者将AOF的刷盘策略设置为每秒一次(默认),而不是每次操作都刷盘,这样能极大减少磁盘I/O的压力,让CPU更专注于处理读写请求,速度自然就上去了,但记住,这相当于用一点点数据丢失的风险换取了性能。

要懂得“断舍离”,也就是合理设置数据过期时间,很多数据其实是有生命周期的,比如用户的登录凭证、临时的验证码、热点新闻的缓存等,如果这些数据永不过期,Redis的内存很快就会被无效数据占满,一旦内存满了,Redis的读写性能会急剧下降,因为它要开始费力地清理旧数据,根据Redis官方文档的说明,主动为数据设置一个TTL(生存时间),让Redis自动清理,可以保持内存的清爽,这就像定期清理仓库的过期库存,腾出空间给新货,整个仓库的运转效率才会高。

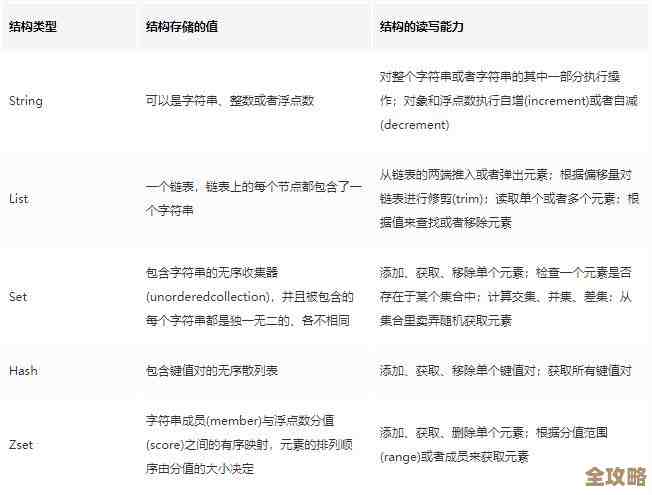
第三,别让Redis“单打独斗”,要善用数据结构这把瑞士军刀,Redis不是只能存简单的字符串(String),存储一个用户的个人信息,如果用多个String键来存姓名、年龄、城市,那么查询时要多次网络往返,但如果用一个哈希(Hash)结构来存,一次操作就能取回或设置所有字段,大大减少了网络通信次数,再比如,要存储好友列表、粉丝集合,用集合(Set)就能高效地进行交集、并集运算,根据“Redis实战”这本书的案例,选择最适合业务场景的数据结构,能从根源上减少不必要的命令执行次数,这是提升效率的关键一步。
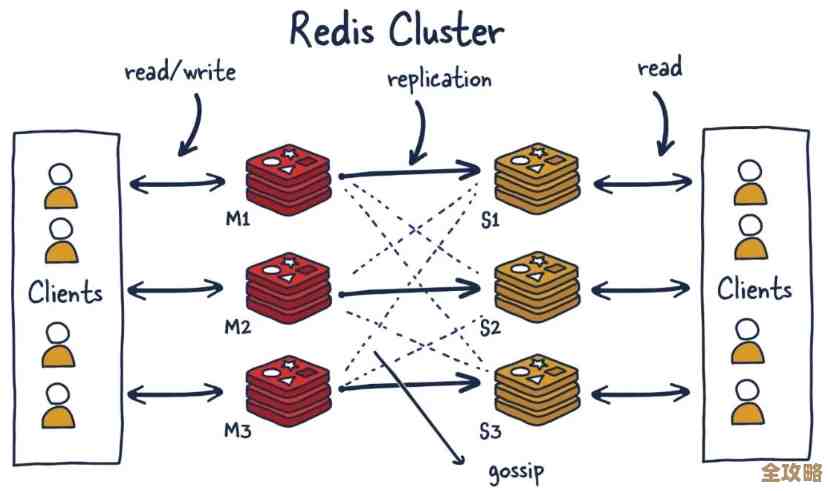
第四,当数据量真的很大时,要考虑“分而治之”,也就是搭建分片集群,单个Redis实例的能力总有上限,分片就是把数据分散到多个Redis实例上,每个实例只负责一部分数据,这样,读写压力也被分摊了,整体吞吐量就上去了,这好比一个仓库忙不过来,就多建几个分仓,每个分仓处理特定区域的货物,根据Redis官方的集群教程,通过分片可以近乎线性地提升Redis的存储容量和处理能力,这会增加架构的复杂性,需要根据实际业务增长来决定是否采用。
一些“细节决定成败”的使用技巧也很重要。
- 使用管道(Pipeline):如果需要连续执行多个命令,可以把它们打包一次性发送给Redis,而不是一个个等回复,这极大地减少了网络往返的时间延迟,根据性能测试对比,管道技术在小批量操作时能带来数倍的性能提升。
- 避免使用Keys命令:这个命令会遍历所有键来匹配模式,在数据量大的时候会严重阻塞其他请求,就像让仓库管理员停下所有工作去盘点整个库存,应该使用Scan命令来渐进式地遍历。
- 控制单个键的大小:虽然Redis能处理很大的键(比如一个很大的List或Hash),但操作它可能会比较耗时,而且可能引发内存分配问题,如果可能,将大对象拆分成多个小对象会更稳妥。
让Redis更快,不是一个神秘的黑科技,而是需要我们在数据持久化、生命周期管理、数据结构选择、架构扩展以及日常使用的细节上多下功夫,做出最适合自己业务场景的明智选择,这些方法结合起来,就能让Redis这把“快刀”更加锋利。
本文由歧云亭于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71157.html