淘宝数据库设计图其实就是要兼顾功能和效率,不能偏废哪个,不然用起来肯定不顺手

关于淘宝数据库设计需要兼顾功能与效率这一点,多位淘宝技术负责人曾在不同场合进行过阐述,淘宝创始人之一、前首席架构师陈吉平在早期技术分享中就提到,淘宝的数据库设计如果只追求功能强大,而忽略了实际运行效率,那么系统在用户量激增时就会“卡死”;反过来,如果一味追求效率,比如把数据字段拆得过于零碎,或者为了速度而过度牺牲数据的一致性,那么很多复杂的业务功能,比如商品的多维度搜索、交易状态的实时追踪、个性化的推荐,就根本无法实现,他强调,设计时必须“两只手都要硬”。
根据淘宝技术团队在《淘宝技术这十年》等公开资料中的回顾,淘宝在发展过程中对此有深刻的教训,在淘宝早期,业务功能优先,数据库设计相对自由,但随着数据量暴涨,许多查询变得极慢,页面加载时间过长,用户体验很差,这迫使团队进行艰难的改造,商品信息数据库,最初可能为了功能全面,在一个大表里存放了所有信息,包括标题、描述、属性、图片链接等等,当商品数量达到亿级,卖家频繁修改商品信息,买家进行各种条件筛选时,这个表就成了瓶颈,后来,他们不得不对数据进行拆分和分层设计,将核心的、频繁访问的信息(如价格、库存)与描述性、变动较少的信息分开存储,这就是在功能完备性(需要存储所有信息)和读写效率(快速访问核心信息)之间做出的典型平衡。
另一个例子是用户交易记录,淘宝副总裁、负责平台技术的某位高管(在阿里技术峰会上的演讲)曾以“订单查询”为例说明:用户希望查询自己多年来的所有订单,这是一个合理的功能需求,但如果把一位用户的所有订单记录都简单地按时间顺序存在一起,当这个用户是十年老客户、订单量上万时,每次查询加载全部记录都会非常慢,数据库设计上可能采用“分库分表”的策略,按时间和用户ID进行拆分,可能建立专门的汇总表或索引,用于快速呈现订单概览,而详细商品信息则在点击后再去查询,这样,既保证了“查询所有订单”的功能存在,又保证了常用操作页面的加载效率。
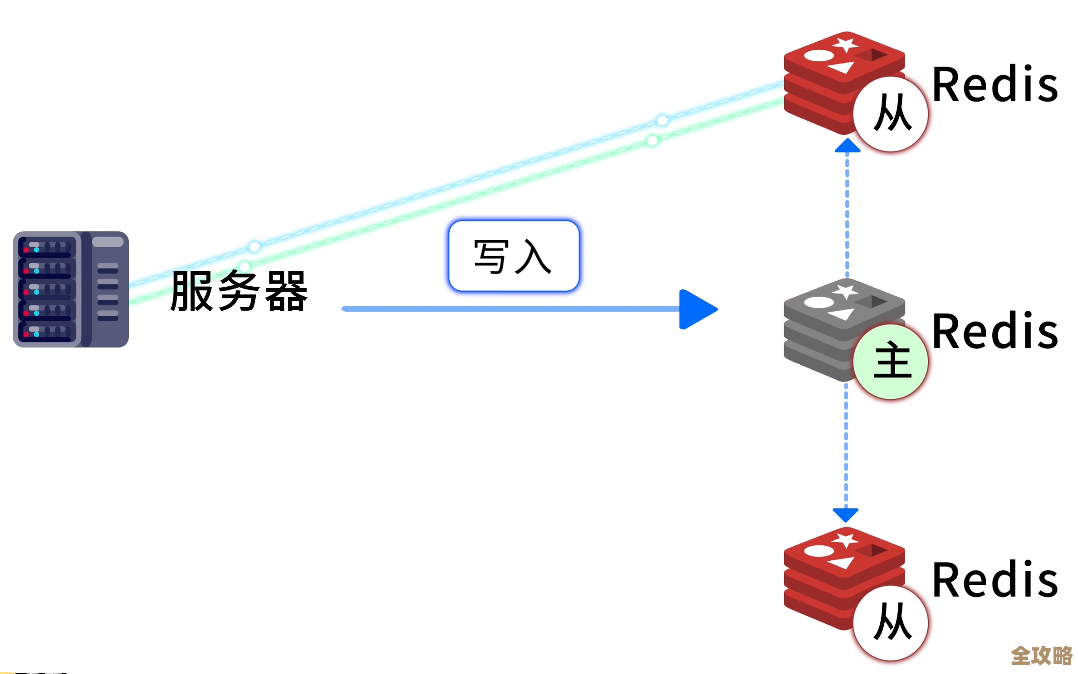
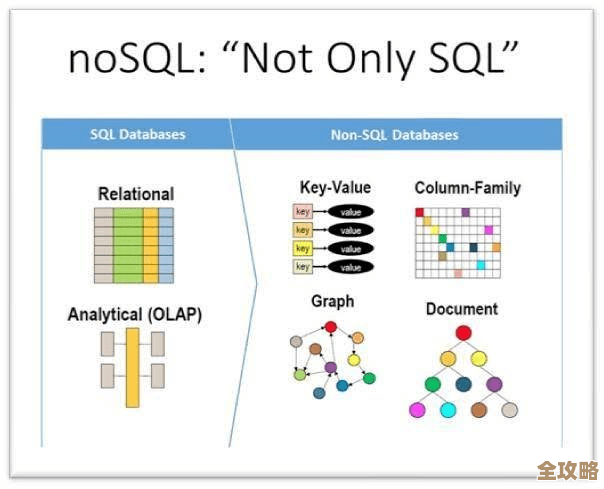
在用户个性化推荐这个功能上,兼顾二者显得更为关键,据阿里云数据库团队的一篇技术博客分析,推荐系统需要分析用户海量的行为数据(浏览、收藏、购买),这要求数据库能高效地写入和存储这些流水数据(效率要求),同时又要能支持复杂的实时分析计算,从中快速提取模式(功能要求),如果数据库设计只考虑存储效率,采用压缩很紧但难以查询的结构,分析功能就跟不上;如果为了分析灵活而设计得过于松散,海量数据又会压垮系统,淘宝的实践中,往往采用混合架构,将不同类型的数据库组合使用,比如用高效能的OLTP数据库处理交易,用分析型的OLAP数据库处理海量行为分析,让合适的工具做合适的事,从整体上实现功能与效率的平衡。
从淘宝公开的技术演进历史看,其数据库设计始终是在功能与效率的“拉锯战”中前进的,每一次业务创新(如双十一大促、直播带货)都会带来新的功能需求,对数据库形成功能上的挑战;而用户规模和数据的爆炸式增长,则持续施加着效率压力,一个好的设计,就是在设计之初就预判到未来的扩展性,在数据表结构、索引策略、存储与计算分离等方面做出灵活的安排,确保新功能可以相对顺利地加入,同时又不让系统速度随着数据增长而显著下降,用他们内部常说的一句话来概括,既要让业务跑得快(功能丰富),又要让系统撑得住(效率稳定)”,任何一方的偏废,都会导致最终的系统“用起来不顺手”,要么是开发新功能举步维艰,要么是用户体验难以忍受的卡顿。

本文由钊智敏于2026-01-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/85466.html