Redis那些卡壳的地方,咱们这次真要好好整一整,突破瓶颈别再犹豫

Redis这玩意儿用起来爽,但真到较劲的时候,几个地方特容易让人卡壳,咱们今天就得把这些疙瘩给捋顺了。
首先就是内存这事儿,它是个无底洞,你以为往里塞数据就行,结果动不动就告警,最憋屈的不是内存不够,而是内存碎片,你删了一堆数据,腾出了地方,但新来的数据块儿太大,那些零散的空位用不上,看着有内存,实际上用不了,书上(《Redis设计与实现》)也说了,这跟Redis的内存分配机制有关,解决办法嘛,一是重启,简单粗暴但管用;二是Redis 4.0以后,可以用MEMORY PURGE主动清理(但效果看系统);最治本的,是得看看你业务的数据是不是大小差太远了,尽量让数据规格整齐点。
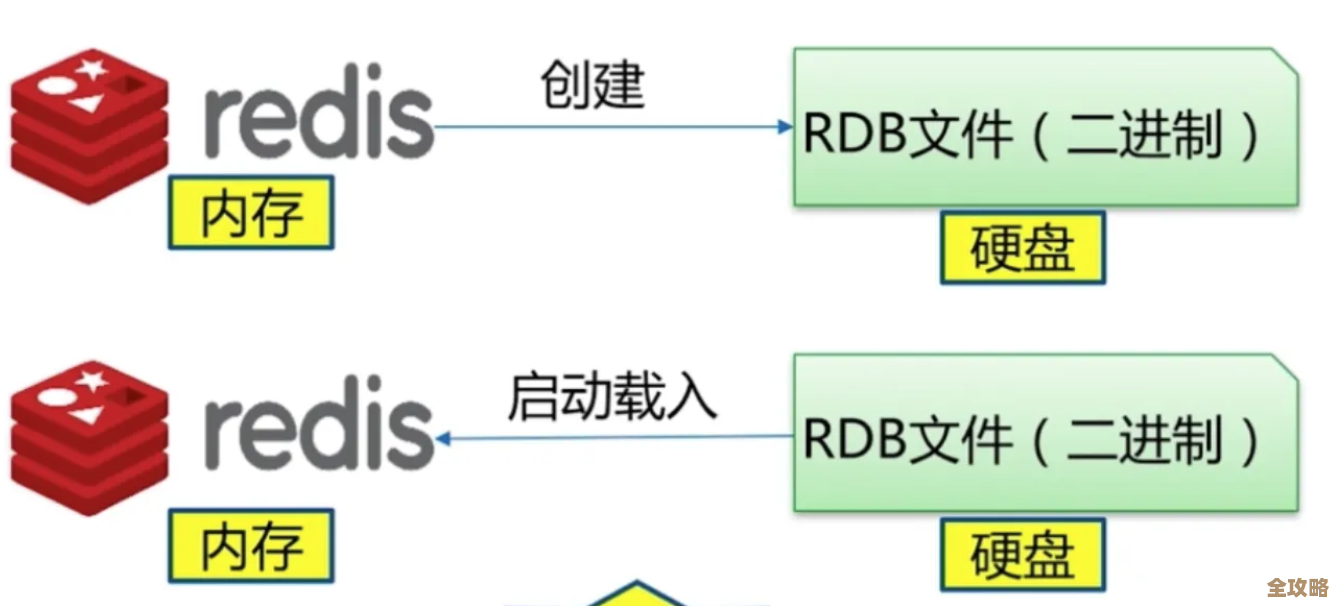
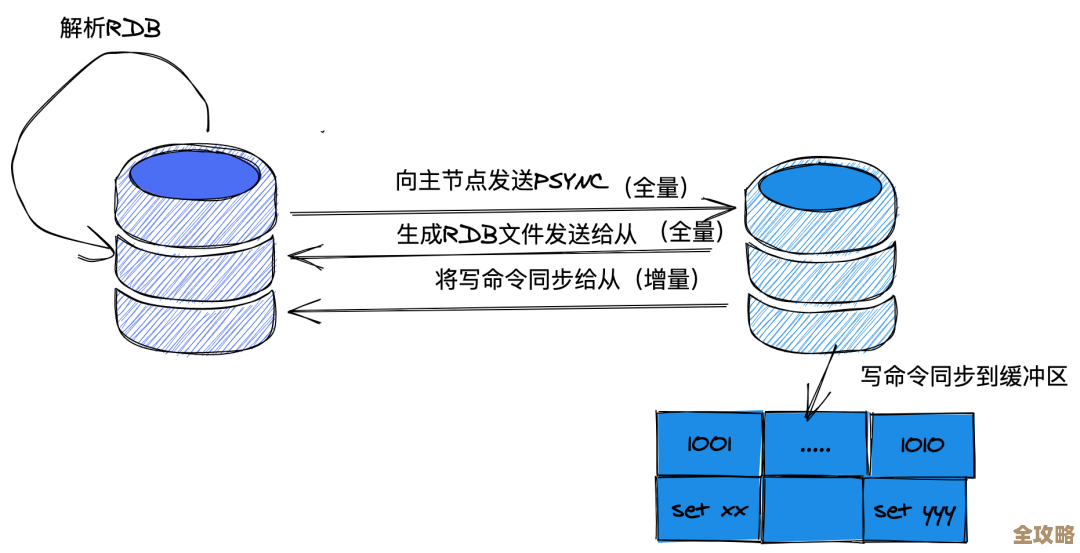
接着是持久化的纠结,用RDB吧,定时拍个快照,万一两次快照之间宕机,这段时间的数据就丢了,用AOF吧,日志文件会越来越大,重写的时候也耗资源,最稳妥的是两者都用,但这对磁盘和性能都有要求,很多人卡在“到底选哪个”或者“怎么配参数”上,其实没有完美方案,就是个权衡,要性能就RDB,要安全就AOF,既要又要就混合持久化(Redis 4.0以后),但代价是复杂度和硬件成本,你得根据业务能承受的数据丢失程度来定。

第三是集群的麻烦,主从复制延迟,这是老难题了,主节点刚写完,从节点可能还没同步过去,客户端这时候去读从节点,就读到个旧数据,业务上就可能出乱子,还有,用Cluster模式吧,数据是分片了,但跨节点操作就不支持了,像那些涉及多个key的集合操作,除非这些key都在同一个哈希槽里,不然直接报错,迁移和扩容也得很小心,弄不好就影响服务。
第四,“大Key”和“热Key”,这两个是性能杀手。大Key(比如一个List里头存了几十万条)一删除,Redis会卡住半天,因为它是单线程的,别的命令都得等着,网络也容易堵。热Key(某个key被疯狂访问)更隐蔽,所有请求都打到一个节点上,这个节点CPU飙高,可能就拖垮整个服务,对付大Key,得拆,比如把一个大List拆成多个小的,对付热Key,可以本地缓存,或者用Redis的集群模式,通过给key加随机后缀之类的方法,把访问分散到不同节点上。

第五,缓存和数据库的一致性问题,这是最让人头疼的,先更新数据库还是先删缓存?怎么删?搞不好就脏数据,经典的“先更新数据库,再删除缓存”也不是百分百可靠,但出问题概率小,更稳妥的办法是搞个“延迟双删”,或者用监听数据库binlog的机制来同步删缓存,但这就复杂了,很多团队卡在这,要么忍受极短时间的不一致,要么就得下功夫设计复杂的同步机制。
别小看连接池和超时设置,连接数不够,请求就排队,看起来像Redis慢,超时时间设短了,网络稍微一波动就超时;设长了,一旦有慢查询,连接很快被占满,服务就雪崩,这些地方配得不合适,整天都是些莫名其妙的毛刺。
说到底,Redis快是快,但它不是个“傻快”的盒子,这些卡壳的地方,往往是因为咱们把它用得太“黑盒”了,觉得set/get完事,真想突破瓶颈,就得把它那些脾气——单线程、内存管理、持久化取舍、集群限制——都摸透,根据自己业务的实际情况,该拆数据的拆数据,该改架构的改架构,该加监控的加监控,别犹豫,该动手整就得整。
本文由邝冷亦于2026-01-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/85501.html