Redis缓存真的是单纯内存吗?其实它远比你想的复杂多了

我记得第一次接触Redis的时候,前辈告诉我它就是个大内存,把常用的数据放进去,读得快,我当时也这么以为了很久,觉得它就是个速度快点的简单键值对储物柜,但后来真正用多了,踩过坑,才明白Redis这个名字里的“远程字典服务器”远不止“内存”这么简单,它内部的设计,其实是一套为了极致速度而构建的精妙系统,远比我们想的要复杂。
虽然数据最终是存在内存里,但Redis处理这些数据的方式就很讲究,它不是随便把数据往内存里一扔就完事了,根据阿里云开发者社区的一篇文章提到,Redis使用了多种高效的数据结构来存储不同类型的值,我们常用的字符串(String),Redis并不是傻乎乎地只用C语言里传统的字符串,它会根据值的长度和类型,智能地选择不同的编码方式,像很短的字符串,它会用一种叫embstr的方式存储,这样能和键名一起分配内存,减少碎片,访问也更直接,而普通的字符串就用一种叫SDS(简单动态字符串)的结构,这种结构比C原生的字符串更安全、更高效,能记录长度信息,避免了缓冲区溢出等问题。
再比如,我们以为的列表(List),在数据量小的时候,Redis并不是直接使用链表,而是用一种叫ziplist(压缩列表)的结构,把所有的元素紧凑地挨着存放,这样做的好处是,因为内存是连续分配的,能极大地减少内存占用,并且利用CPU缓存的局部性原理,访问速度非常快,只有当列表元素超过一定数量或单个元素过大时,它才会转换成真正的双向链表结构,以保证插入删除的效率,这种“看人下菜碟”的智能编码机制,背后是开发者对性能和内存的极致权衡。
说到内存,Redis真的只是把数据放在内存里就高枕无忧了吗?绝对不是,如果服务器突然断电,内存里的数据不就全没了吗?这可是个大问题,Redis设计了两种主要的持久化机制,把内存里的数据写到硬盘上,防止数据丢失,一种叫RDB(快照),就像给数据库拍张照片,在某个时间点把完整的数据集保存成一个文件,另一种叫AOF(追加日志文件),它不拍照片,而是像个记账先生,把每一个写操作命令都记录下来,这样即使服务器宕机,重启后重新执行一遍这些命令,就能恢复数据,根据腾讯云社区的一篇文章解释,AOF文件还会定期重写,压缩掉中间冗余的命令,防止文件无限膨胀,你看,为了数据的可靠性,Redis在背后默默地做了这么多硬盘I/O操作,这已经超出了“单纯内存”的范畴。
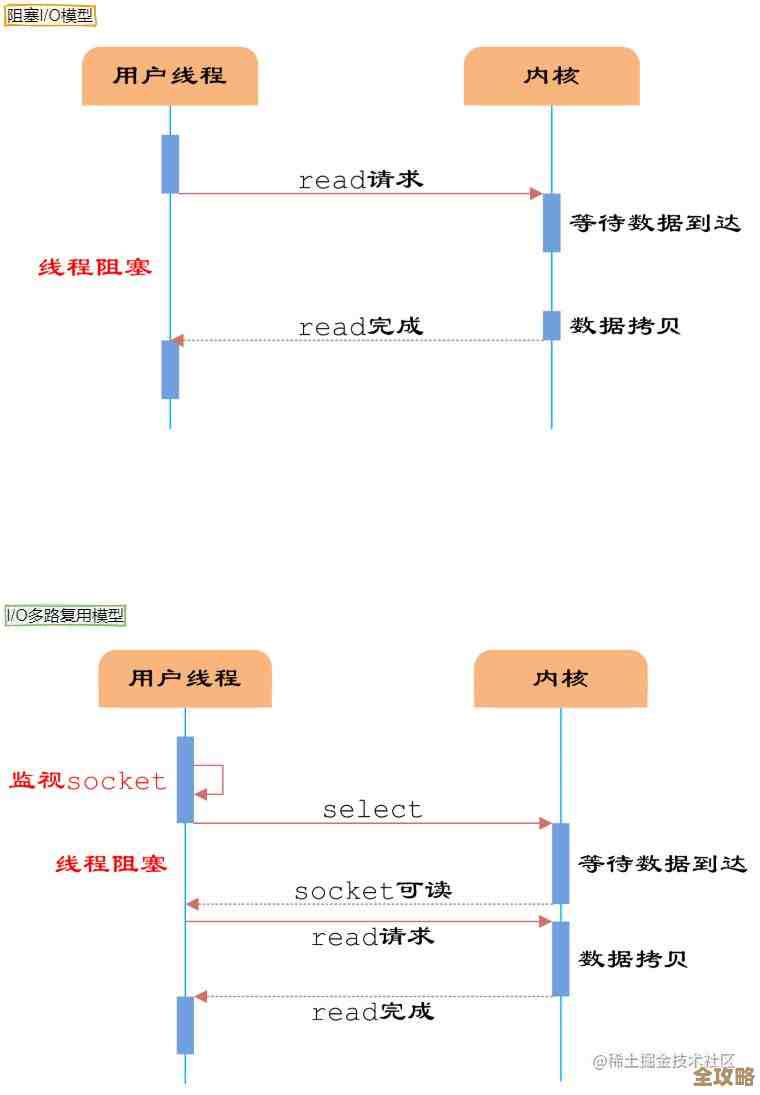
还有一点容易被忽略的是网络I/O,Redis是单线程处理命令的,这个很多人都知道,但它为什么能用一个线程扛住每秒十万甚至百万的请求呢?除了内存操作快,更重要的是它使用了高效的I/O多路复用模型,简单说,就是用一个线程监控很多个网络连接,哪个连接有数据来了就处理哪个,避免了为每个连接创建线程的开销和上下文切换的成本,这意味着,Redis的“快”,不仅仅是内存读写的快,更是网络通信模型设计上的高效,大量的时间其实花在了网络数据传输上,而Redis把这个过程优化到了极致。
当我们把Redis用在分布式环境中时,它又展现出了另一面的复杂性,比如主从复制,主节点要把自己的数据变化实时同步给多个从节点,这个过程要保证数据的一致性,又要兼顾性能,还有集群模式,数据如何分片到不同的Redis实例上,客户端如何知道要去哪个实例上找数据,这些都不是简单的内存操作能概括的,背后是一整套复杂的分布式系统协议和算法。
回过头来看,Redis的核心确实是基于内存,这奠定了它速度的基石,但它的“复杂”在于,为了将内存这个优势发挥到极致,并弥补内存易失性的短板,它在数据结构编码、持久化、网络I/O和分布式架构上都做了极其精巧和复杂的设计,它不仅仅是一个被动的存储容器,更是一个主动的、智能的数据管理系统,下次再提到Redis,我们脑海里不应该只是一个“快”字,而应该浮现出它背后那一整套为了快和稳而辛勤工作的复杂机制,它远不止是内存,它是一个精心打造的、以内存为核心的性能艺术品。

本文由称怜于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84625.html