数据库里哪些表占空间大?教你快速查找和解决办法

当我们发现数据库服务器的磁盘空间越来越紧张,或者应用突然变慢时,第一反应往往是:是不是哪个数据表“吃”掉了太多空间?快速找到这些“空间大户”是解决问题的第一步,下面就来详细说说怎么找,以及找到后怎么办,这个方法的核心思想,就像整理一个杂乱无章的房间,你得先知道是哪个柜子或者哪个箱子最占地方,才能有针对性地进行清理或扩容。
第一部分:如何快速查找占用空间大的表
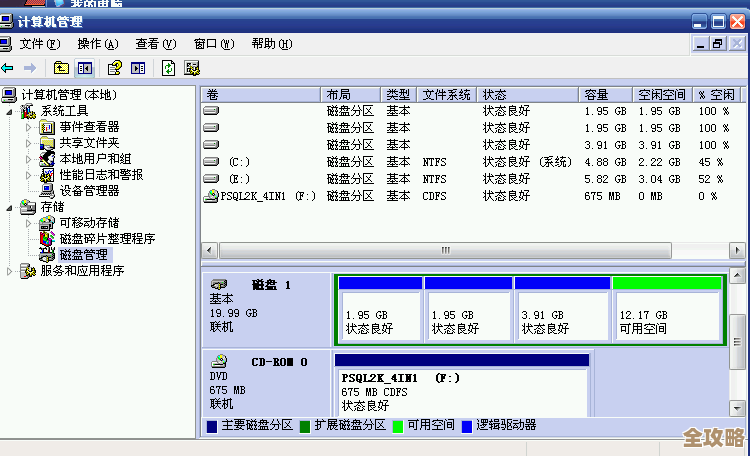
不同的数据库管理系统有各自的方法来查询这些信息,但它们的基本原理是相似的:查询系统自带的元数据表或信息视图,这些视图里记录了每个表的行数、数据占用的空间、索引占用的空间等详细信息。
-
对于MySQL(特别是InnoDB引擎): 我们可以查询
information_schema数据库中的TABLES表,这个表就像一个花名册,记录了所有表的基本情况,关键字段有:TABLE_NAME:表的名字。TABLE_ROWS:表的估算行数。DATA_LENGTH:数据部分占用的空间大小(单位是字节)。INDEX_LENGTH:索引部分占用的空间大小。 一个常用的查询语句是这样的(来源:MySQL官方文档关于INFORMATION_SCHEMA.TABLES的说明):SELECT TABLE_NAME AS `表名`, TABLE_ROWS AS `行数`, ROUND(DATA_LENGTH / 1024 / 1024, 2) AS `数据大小(MB)`, ROUND(INDEX_LENGTH / 1024 / 1024, 2) AS `索引大小(MB)`, ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS `总大小(MB)` FROM information_schema.TABLES WHERE TABLE_SCHEMA = '你的数据库名' ORDER BY (DATA_LENGTH + INDEX_LENGTH) DESC LIMIT 10;
执行这个查询后,你会得到一个列表,按照表的总占用空间从大到小排序,一眼就能看出前10名是哪些表。
-
对于SQL Server: 可以使用一个名为
sp_spaceused的系统存储过程,你可以不带参数运行它来查看当前整个数据库的空间使用情况,也可以指定表名来查看某个特定表的空间使用(来源:Microsoft Learn官方文档关于sp_spaceused的说明)。
-- 查看某个特定表的情况 EXEC sp_spaceused '你的表名';
如果想查看所有表的情况,可以借助其他系统视图(如
sys.tables和sys.partitions)进行关联查询,思路和MySQL类似。 -
对于PostgreSQL: 可以查询
pg_class系统表,并结合pg_namespace等视图,一个常见的查询是(来源:PostgreSQL Wiki关于磁盘用量的页面):SELECT schemaname AS `模式名`, relname AS `表名`, pg_size_pretty(pg_total_relation_size(relid)) AS `总大小`, pg_size_pretty(pg_relation_size(relid)) AS `数据大小`, pg_size_pretty(pg_total_relation_size(relid) - pg_relation_size(relid)) AS `索引大小` FROM pg_catalog.pg_statio_user_tables ORDER BY pg_total_relation_size(relid) DESC LIMIT 10;
通过以上方法,你就能快速、准确地定位到数据库中的“空间消耗大户”。
第二部分:找到问题表后的解决办法

知道了是哪些表占用了大量空间,接下来就是如何“瘦身”或管理了,解决办法主要分为两大类:立即释放空间和优化未来增长。
清理无用数据(给数据库“减肥”) 这是最直接的解决办法,很多时候,表大是因为积压了大量的历史数据或无效数据。
- 识别并删除历史数据:检查那些大表,是否存在可以删除的旧数据,日志表可能只保留最近3个月的数据就够了,订单表可能只需要保留已完成交易的一定年限的数据,使用
DELETE语句进行删除。- 重要提示:直接使用
DELETE删除大量数据可能会产生巨大的事务日志,影响性能,甚至可能撑爆日志文件,对于海量数据删除,建议分批删除(比如一次删1000行,循环进行)。
- 重要提示:直接使用
- 清空表:如果整个表的数据都可以不要了(比如临时表或缓存表),使用
TRUNCATE TABLE命令会比DELETE更高效,因为它不会记录逐行删除的日志,并且会重置表的计数器。
优化数据存储(让数据库“更结实”) 在删除数据后,你可能会发现磁盘空间并没有立即释放,这是因为数据库为了性能,只是标记了这些空间为“可重用”,并没有还给操作系统,这时需要进行一些优化操作。
- 重建索引:频繁的增删改操作会导致索引产生很多碎片,就像磁盘碎片一样,使得索引占用的空间不紧凑,查询效率也会降低,对表进行索引重建可以消除碎片,回收空间,并提升查询速度,在MySQL中可以使用
OPTIMIZE TABLE 表名;(对于InnoDB表,它等价于重建表+重建索引),在SQL Server中可以使用ALTER INDEX ALL ON 表名 REBUILD;。 - 归档历史数据:如果数据有重要的历史价值不能删除,但又不参与日常业务查询,归档是最好的选择,所谓归档,就是把不常用的冷数据从主业务表中移出来,存到另一个结构相同的归档表里,或者甚至导出成文件存到更便宜的存储设备上,这样既减轻了主表的体积和压力,又保留了数据。
调整数据库设计(从根源上“控制体重”) 如果某些表天生就是会快速增长的类型(比如日志表、事件表),那么需要从设计上考虑如何管理其空间增长。
- 实施分表策略:这是应对超大型表的终极武器,分表可以分为两种:
- 水平分表:按照某个规则(比如时间)将一张大表的数据拆分到多张结构相同的物理表中,日志表可以按月或按年进行拆分,变成
logs_202401,logs_202402... 这样,查询最新数据时效率很高,清理旧数据时直接删除或归档整个旧表即可,非常高效。 - 分区表:这是数据库系统提供的更高级的功能,在逻辑上是一张表,但物理上数据存储在不同的分区里,其管理便利性和查询优化能力比手动分表更强,但设置更复杂。
- 水平分表:按照某个规则(比如时间)将一张大表的数据拆分到多张结构相同的物理表中,日志表可以按月或按年进行拆分,变成
- 审查数据类型:在创建表时,是否使用了过大的数据类型?比如用
BIGINT存储只需要INT的ID,用VARCHAR(MAX)存储长度不会超过100的字段,在表设计初期选择最合适的数据类型,可以节省大量空间。
总结一下
当遇到数据库空间不足的问题时,不要慌张,利用数据库系统提供的工具(如MySQL的information_schema)快速定位占用空间最大的几张表,分析这些表数据量大的原因:是积累了太多可删除的历史数据?还是索引碎片过多?或者是表本身增长过快?根据分析结果,采取针对性的措施,无论是清理数据、优化索引,还是从长远考虑进行分表设计,都能有效地解决空间问题,让数据库恢复轻盈和高效。
本文由雪和泽于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84176.html