Redis查询那些事儿,快速定位指定数据怎么整才快又准

主要参考自Redis官方文档、多位技术博主如“程序员小灰”、“阿里云开发者”等社区文章,以及《Redis设计与实现》一书中的核心思想)
Redis查询的核心就一个字:快,但想又快又准地找到你想要的那条数据,可不是只会用GET和SET那么简单,这就像在一个巨大的、没有分类的仓库里找东西,如果你不知道方法,只能一个个箱子翻,累死也找不到,下面就来聊聊怎么给这个仓库装上“智能导航”。
第一件事:忘掉“查询”,直接访问”
和MySQL这种关系型数据库最大的不同是,Redis几乎没有像SELECT * FROM table WHERE field = value这样的复杂查询语句,它的设计哲学是:通过Key(键)直接定位到Value(值)。“快速定位”的第一步,也是最重要的一步,就是设计一个好Key。
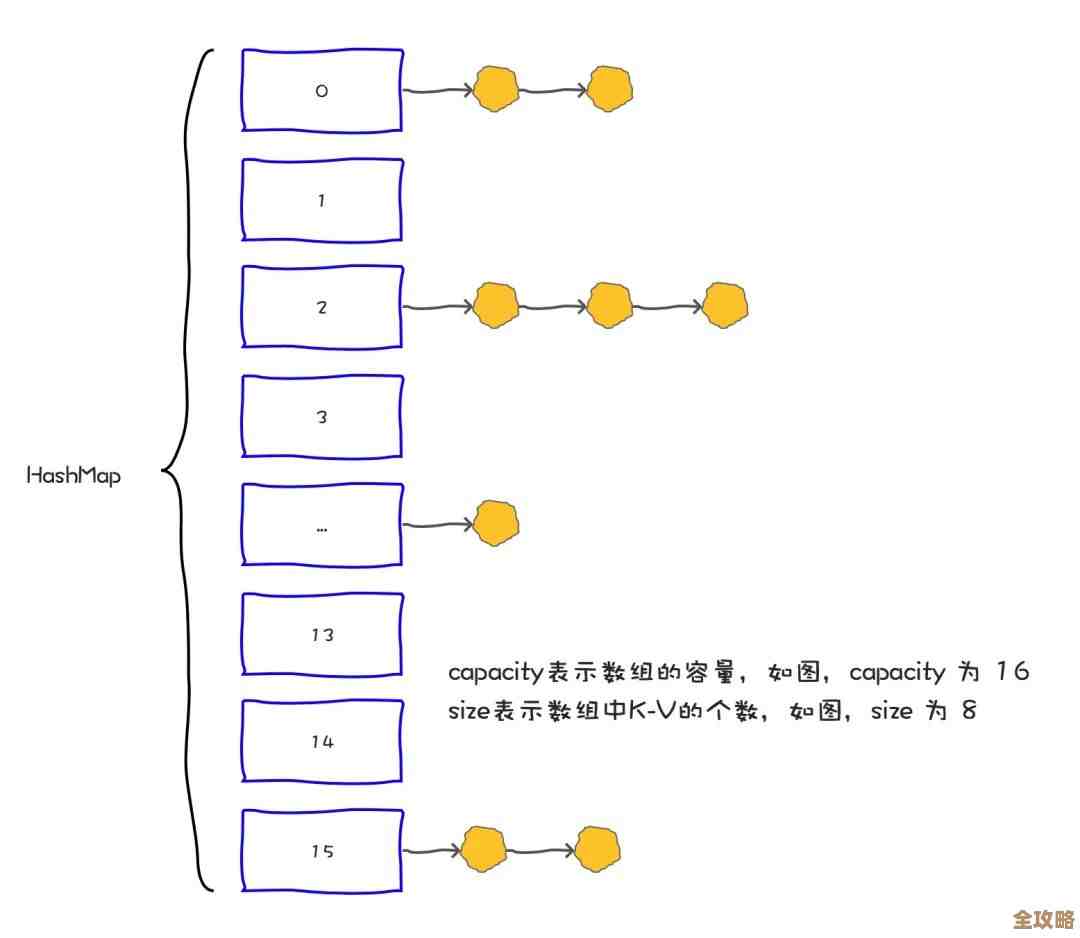
这个Key不能随便起,比如你要存一个用户信息,用户ID是123,你别存个user这样的Key,那全系统就这一份,肯定冲突,也别存太啰嗦的,比如systema:moduleb:functionc:userid:123,虽然清晰但太长,浪费内存,一个好的Key应该像user:123这样,简短且有层次感。用户类型:用户ID,一看就知道这是什么数据,而且同类数据有共同的模式user:*,为后面要用到的模式匹配扫描打下基础。
第二件事:学会用合适的数据结构,别什么都用String
很多人把Redis当做一个简单的键值对缓存,所有数据都用String类型存,比如把用户的对象用JSON序列化成字符串存进去,这没问题,但有时候不够高效。
举个例子,比如你要存一个用户的个人信息,包括姓名、年龄、城市,用String存成一个JSON字符串,SET user:123 '{"name":"张三","age":30,"city":"北京"}',取的时候整个拿出来,没问题。
但如果你经常需要单独修改用户的年龄,或者只获取用户的城市呢?用String你就得把整个JSON字符串取出来,在程序里解析成对象,修改年龄,再序列化成JSON,最后写回Redis,这一来一回,网络传输和数据处理的成本就高了。
这时候,Hash(哈希) 结构就派上用场了,你可以这样存:
HSET user:123 name "张三" age 30 city "北京"你可以用HGET user:123 age直接获取年龄,用HINCRBY user:123 age 1直接给年龄加1。操作直接在内完成,不用传输和解析整个对象,又快又省流量,根据你最常见的访问模式来选择数据结构,是“准”和“快”的关键。
第三件事:当真的需要“找”东西时,用好SCAN和模式匹配
有时候需求就是很复杂,比如老板说:“把所有来自北京的、年龄大于25岁的用户给我找出来”,这在Redis里是个难题,因为它不支持二级索引(像MySQL里给city和age字段建索引那样)。
怎么办?笨办法是KEYS user:*,这个命令会列出所有以user:开头的key。但绝对不要在线上生产环境用KEYS命令! 因为它会一次性遍历整个数据库的所有key,如果key的数量有几百上千万,这个命令会直接卡住Redis服务器,导致其他所有请求超时,相当于一次小型故障。
正确的姿势是使用SCAN命令。SCAN是一个游标迭代器,它每次只返回一小部分key,然后给你一个游标,你下次带着这个游标再请求,它再给你下一部分,这样就像分批扫描,虽然总工作量一样,但每次只占用一点点资源,不会阻塞服务器,你可以用SCAN命令结合模式匹配,比如SCAN 0 MATCH user:*,来安全地找出所有用户key。
但光找到key还不够,上面的需求还要判断用户的条件(北京、年龄>25),这就需要你在客户端程序里做了:用SCAN拿到一批key,然后用HGETALL或HMGET批量获取这些key对应的Hash值(也就是用户信息),最后在程序里过滤出满足条件的用户,这个过程可能有点慢,但它是唯一可行的、安全的方案。
第四件事:终极武器——自己维护“索引”
对于那种查询非常频繁的组合条件,比如按城市查用户,上面的SCAN+过滤方式还是太慢,这时候就要用到“空间换时间”的思想:自己手动建立索引。
你可以专门用一个Set(集合)来存某个城市的所有用户ID。
SADD city:北京 123 456 789这样,当你需要查询所有北京的用户时,直接SMEMBERS city:北京,瞬间就能拿到所有用户ID的列表,然后再用这些ID去HMGET批量获取用户详情,速度飞快。
你甚至可以建立更复杂的索引,比如用Sorted Set(有序集合)来存“年龄索引”,把年龄作为分数,用户ID作为成员,这样,查询“年龄大于25岁的用户”就可以用ZRANGEBYSCORE age_index 25 +INF,也非常快。
维护索引有代价:每次新增、修改用户信息时,你不仅要更新主数据user:123,还要同步更新所有相关的索引集合(比如用户改了城市,就要从旧城市集合移除,加入新城市集合),这增加了代码的复杂性,但换来了极致的查询速度,这就是典型的权衡。
想在Redis里又快又准地找数据,核心思路是:
- 设计好Key:让Key本身有含义,易于管理和匹配。
- 选对数据结构:根据访问模式选择String、Hash、List、Set、ZSet,让操作更直接。
- 慎用
KEYS,多用SCAN:需要扫描时,用SCAN命令避免服务阻塞。 - 敢于建索引:对高频复杂查询,手动维护索引集合,用空间换时间。
Redis的“快”是建立在你的“巧用”之上的,把它当成一把锋利的手术刀,而不是一把锤子,才能精准地解决性能瓶颈。

本文由帖慧艳于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84141.html