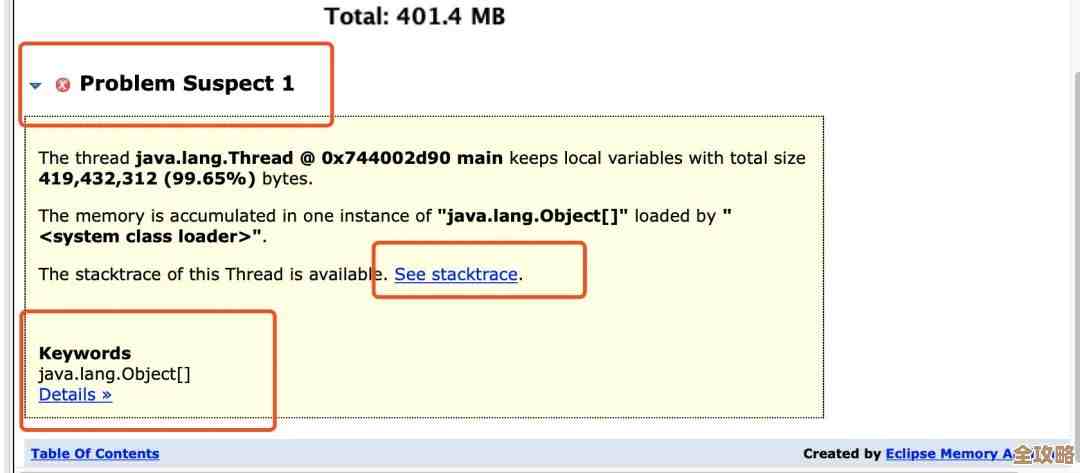
多数据源数据库连接怎么搞,方法和细节一步步说清楚

要搞清楚“多数据源连接”是什么意思,简单说,就是一个应用程序需要同时跟好几个不同的数据库打交道,这些数据库可能是同一种类型的,比如都是MySQL;也可能是完全不同的,比如一个是MySQL,另一个是SQL Server,甚至还可能连接一个Excel文件或者网上某个API接口的数据。
根据一篇名为《Spring Boot多数据源配置的两种方案》的文章,实现多数据源的核心思路其实不复杂,分开管理”,你不能像平时那样,让程序只认一个数据库连接,你得告诉程序的不同部分:“你,去用A数据库;你,去用B数据库。”
下面我一步步说清楚具体怎么做,主要讲两种最常用的方法。
基于配置的静态分离(最常用)
这种方法适合那种分工明确的情况,比如一些读数据的功能专门用一个数据库(这个数据库可能是个只提供查询的副本,速度快),一些写数据的功能用另一个主数据库。

-
第一步:准备环境和依赖 假设你用的是Java和Spring Boot框架,你需要在你的项目配置文件(比如
application.yml或application.properties)里,不再是写一套数据库连接信息,而是写好几套,你会给每一套连接信息起个名字,比如叫做datasource.primary和datasource.secondary,这里面要分别写好各自的数据库地址、用户名、密码等等。 -
第二步:创建多个数据源配置类 这是最关键的一步,你不能让Spring Boot自动帮你配置一个默认的数据源了,你得自己动手“造”出两个(或多个)数据源对象。
- 你会创建两个独立的配置类,比如叫
PrimaryDataSourceConfig和SecondaryDataSourceConfig。 - 在第一个配置类里,你通过
@Bean注解创建一个数据源对象(比如DataSource),并且用@ConfigurationProperties注解告诉Spring,这个数据源的配置信息是从配置文件里的datasource.primary那部分读取的,这样,你就得到了一个连接主数据库的数据源。 - 同样地,在第二个配置类里,你再创建另一个数据源对象,让它去读取
datasource.secondary的配置。 - 为了不让Spring搞混,你还需要用
@Primary注解来标记其中一个数据源,告诉Spring:“如果没特别说明,默认就用这个。” 通常会把写操作多的那个主数据源设为默认。
- 你会创建两个独立的配置类,比如叫
-
第三步:配置不同的数据库会话工厂和事务管理器 光有数据源还不够,因为程序操作数据库还需要“会话工厂”(SqlSessionFactory)和“事务管理器”(TransactionManager)这些东西,你需要为每个数据源都单独配置一套,在各自的配置类里,分别创建属于自己数据源的会话工厂和事务管理器,同样,要给它们起好名字(通过
@Bean的name属性),并且把默认的那个标记为@Primary。 -
第四步:在使用时指定数据源 基础设施都搭好了,当你要写一个访问数据库的代码(比如一个Mapper接口)时,你就要明确告诉它,它应该绑定到哪个数据源对应的会话工厂上去,你可以用注解(比如MyBatis-Plus的
@DS注解)直接在代码上标明“这个Mapper用secondary数据源”,这样,当程序运行到这个Mapper的方法时,它就会自动去连接你指定的第二个数据库了。
这种方法的好处是结构清晰,每个数据源干嘛的都定好了,不容易乱,缺点就是不够灵活,如果后面要加新的数据源,又得去写新的配置类。
动态数据源切换(更灵活)
这种方法适合更复杂的场景,比如根据当前登录的用户身份决定连哪个数据库,或者根据一些业务规则动态切换。
根据另一篇关于《SpringBoot 多数据源动态切换》的讨论,这种方法的核心是建立一个“数据源路由”,听起来高级,其实就像个调度中心。

-
第一步:抽象出一个目标数据源 你需要定义一个类,让它能够根据某种“线索”(通常是一个存在ThreadLocal里的key,dataSource_key”)来决定当前这个请求到底应该使用哪个具体的数据源,这个类就是“路由”的核心。
-
第二步:继承一个抽象的路由类 在Spring里,有一个现成的
AbstractRoutingDataSource类,你创建一个新类(比如叫DynamicDataSource)来继承它,你只需要重写一个关键方法,就是determineCurrentLookupKey(),在这个方法里,你写上逻辑:“去ThreadLocal里把那个‘dataSource_key’取出来,返回它。” 这个key就是你之前给每个数据源起的名字,primary"或"secondary"。 -
第三步:把所有数据源交给路由管理 你需要把你准备好的所有具体的数据源(比如primaryDataSource和secondaryDataSource)像一个地图(Map)一样,注入到这个动态数据源路由里,Map的key就是数据源的名字("primary", "secondary"),value就是对应的数据源对象,你把这个动态数据源路由对象本身设置为Spring容器里唯一的数据源(
@Primary)。 -
第四步:在需要的地方切换数据源 整个程序表面上只有一个数据源(就是那个路由),但这个路由会“看人下菜碟”,你需要在业务代码中,执行数据库操作之前,通过一个自定义的注解或者一个工具方法,把代表目标数据源的key(secondary")设置到当前线程的ThreadLocal变量里,执行完后,再清理掉这个key,这样,路由在接到请求时,就能根据这个key找到正确的数据源进行连接了。
这种方法非常灵活,可以在运行时动态切换,但缺点是复杂度高,要处理好多线程环境下key的清理问题,不然容易造成数据源混乱(比如A用户的请求用了B用户设置的数据源)。
需要注意的细节和坑
- 事务问题:尤其是在动态数据源方案里,如果切换数据源的时机不在事务开始之前,可能会出问题,事务一旦开启,通常就绑定了一个数据源,中途很难再换,所以切换操作要提前。
- 连接池:每个数据源最好都配置自己的连接池(如HikariCP),并设置合理的参数,避免连接不够用或者泄漏。
- 资源清理:动态数据源方案中,那个用来做路由线索的ThreadLocal变量,用完后一定要记得清除(
remove),否则可能会引起内存泄漏或后续请求的数据错乱。
搞多数据源,要么用第一种“分家”的方法,简单直接;要么用第二种“路由”的方法,灵活强大,选哪种就看你的业务需求是不是经常变化,无论哪种,核心思想都是把水搅浑,让程序能清楚地知道在什么时候该找哪个数据库说话。
本文由帖慧艳于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84111.html