数据库设计里头那些关系模式,三种主要类型怎么个回事儿简单聊聊


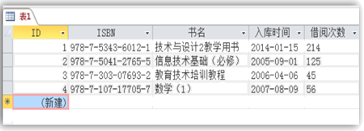
想象一下,你要给自己家的小卖部做个库存管理系统,你最先想到的可能是弄一张大表,把所有的信息都记下来:商品名字、进货价格、卖出价格、供应商名字、供应商电话、进货日期……等等,这种把所有鸡蛋都放在一个篮子里的做法,其实就是第一种类型,叫做“单一关系模式”,它简单直接,刚开始东西少的时候,用起来特别顺手,你想查什么,就在这一张表里找就行了,但它的麻烦很快就来了,同一个供应商“XX食品厂”供给了你十种商品,那你就要在这张表里重复记录十次“XX食品厂”的名字、电话和地址,万一这个食品厂搬家了,电话号码换了,你就得把这十条记录一个一个找出来修改,一不小心就可能漏掉某个,导致数据不一致,出错的概率非常大,这种重复劳动和数据冗余,就是单一关系模式最大的痛点。

那怎么办呢?很自然的想法就是“分家”,我们把牵扯到供应商的信息单独拎出来,做成一张新的表格,比如就叫“供应商表”,这张表里给每个供应商一个独一无二的编号(比如001是XX食品厂,002是YY饮料公司),然后记录下它的名字、电话、地址,回过头来,在我们原来的“商品表”里,我们就不再需要重复写供应商的全套信息了,只需要留下那个供应商的编号就行了,你看,这样一来,商品和供应商之间就通过这个编号产生了联系,这种“分家”之后的状态,就是最常用、最标准的一种关系模式类型,在这种模式下,一个商品只对应一个供应商(假设你一种商品只从一家进货),但一个供应商可以对应多个商品(XX食品厂既给你供酱油,也给你供醋),这种“一家对多家”的关系,就是数据库里最基础的构建块,绝大多数设计都是基于这个思路来的。
但世界上的事情不总是这么简单,关系会变得更复杂一点,我们再举个学校的例子,想象一下“学生”和“课程”这两样东西,一个学生,比如小明,可以选修多门课程:数学、语文、英语,反过来,一门课程,比如数学,也可以被多个学生选修:小明、小红、小刚都能选,这下好了,你发现没办法简单地说谁属于谁了,你把课程编号放在学生表里?一个学生对应多个课程编号,一个格子放不下(这违反了数据库的基本规则),你把学号放在课程表里?一门课程对应多个学号,同样一个格子也放不下。
那这种情况怎么处理?这就引出了第三种类型,解决办法是再创建一张全新的、专门用来“拉关系”的表,我们可以叫它“选课记录表”或者“成绩表”,这张表里不需要太多内容,主要就是两列:一列是学号(指向是哪个学生),一列是课程编号(指向是哪门课),然后再可以加上一些额外的信息,比如这门课的成绩、选修的学期等,这样,每一条记录就代表了一个学生选修了一门课程的事实,通过这张中间表,我们就把“学生”和“课程”这原本多对多的复杂关系,拆解成了两个简单的一对多关系:一个学生可以有多条选课记录(一对多),一门课程也可以有多条选课记录(一对多),这种通过中间表来解决复杂联姻的方式,就是处理“多家对多家”关系的标准做法。
所以总结一下,数据库设计里琢磨关系模式,其实就是根据现实情况,决定怎么“摆摊”,东西少、关系简单,摆一个大摊(单一关系模式)也行,但管理起来乱,通常的做法是分门别类地摆摊,让一个摊主管着好几个商品(一对多),这是最核心的模式,遇到两个摊子上的东西互相之间你中有我、我中有你的复杂情况,就干脆再开一个专门的“中介摊位”(多对多),让它们通过这个中介来建立联系,这个过程,本质上就是在数据冗余(省空间但易出错)和关系清晰(占空间但易管理)之间找一个最适合你当前业务的平衡点。

本文由瞿欣合于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/84019.html