MySQL多表查询老是重复?试试GROUP BY来搞定复杂结果吧

“MySQL多表查询老是重复?试试GROUP BY来搞定复杂结果吧”
你有没有遇到过这种情况?当你兴冲冲地把几个表用JOIN连接起来,想一次性获取所有需要的数据时,却发现查出来的结果行数多得离谱,而且很多数据看起来是重复的,你想查一个订单以及它包含的所有商品信息,结果一个订单号反复出现了好几次,每次只对应一个不同的商品,这可不是MySQL在跟你开玩笑,而是多表查询中一个非常常见且正常的现象,今天我们就来聊聊为什么会出现这种“重复”,以及如何用GROUP BY这个利器来整理这些复杂的结果,让它变得清晰有用。
为什么会出现“重复”的数据?
要理解这个问题,我们得先明白多表查询(尤其是JOIN)是怎么工作的,想象一下两个表格:一个是“订单表”,每一行代表一个唯一的订单;另一个是“订单明细表”,每一行代表订单中的一个具体商品,一个订单(比如订单号A001)在“订单表”里只有一条记录,但它可能在“订单明细表”里对应着三条记录(比如买了手机、耳机和保护壳)。
当你用订单号把这两个表连接起来时,MySQL会怎么做呢?它会进行一种叫做“笛卡尔积”的操作,虽然听起来有点专业,但理解起来很简单:它会将“订单表”里订单号A001的这一行,与“订单明细表”里所有订单号为A001的行逐一配对,结果就是,原本在“订单表”里独一无二的订单A001,在查询结果中变成了三条记录!每条记录都包含了订单的共同信息(如订单日期、客户ID),但商品信息却各不相同。
这些看似“重复”的数据,其实并不是错误,而是真实关系的一种反映,它告诉我们“一个订单对应着多个商品”这个事实,问题在于,很多时候我们并不需要以这种“扁平化”的格式来看数据,我们可能更希望每个订单只显示一行,然后以某种形式汇总它下面的商品信息,这时候,GROUP BY就派上用场了。
GROUP BY是如何“收拾残局”的?
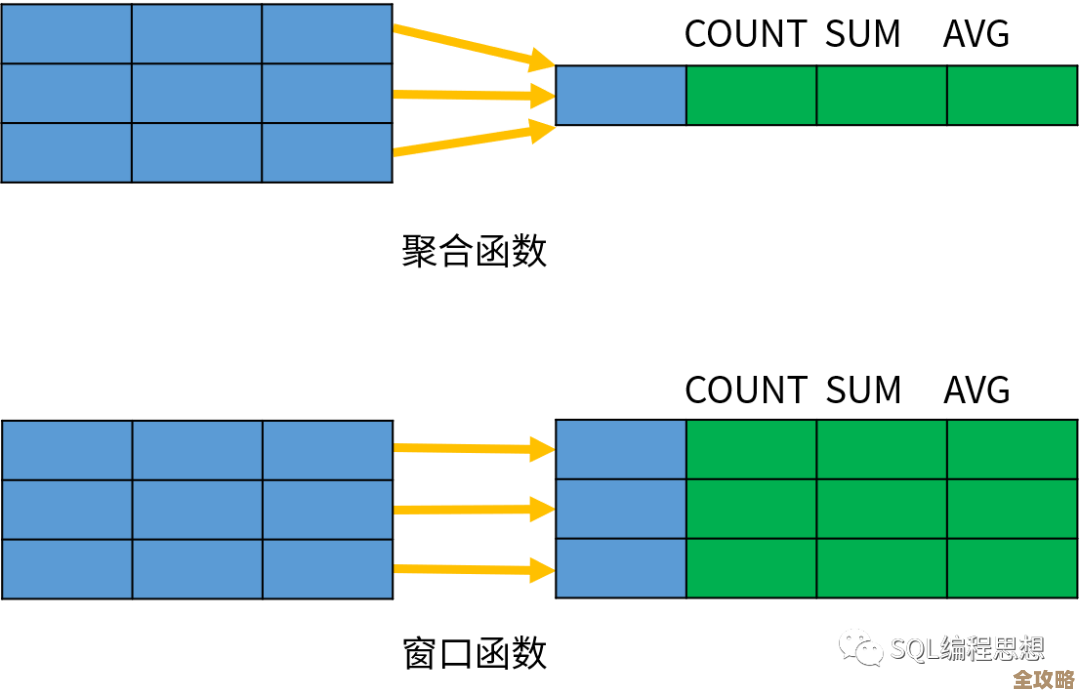
GROUP BY,顾名思义,分组”的意思,它的核心思想是:把那些具有相同值的行归为一组,然后针对这一组数据进行汇总计算或信息提取,它就像是一个高效的整理师,把散乱一地的同类物品分门别类地放好。
继续用上面的例子,当我们直接JOIN查询得到那个包含三条A001订单记录的结果集后,我们在查询语句的最后加上GROUP BY orders.order_id,这句话就是在给MySQL下指令:“嘿,请把所有order_id相同的行都给我聚合成一组。”
一旦数据被分组,我们就可以对组内的数据进行“聚合函数”操作了,常用的聚合函数有:
- COUNT(): 数一数这个组里有多少行,比如
COUNT(order_items.product_id)就能告诉我们这个订单包含了几种商品。 - SUM(): 对组内某一列的数值进行求和,比如
SUM(order_items.quantity)可以计算订单总商品数量,SUM(order_items.quantity * order_items.unit_price)可以计算订单总金额。 - GROUP_CONCAT(): 这是一个非常实用的函数,它能把组内某一列的所有值拼接成一个字符串,比如
GROUP_CONCAT(order_items.product_name SEPARATOR ', '),就能把“手机,耳机,保护壳”这样的信息合并到A001订单的同一行里显示。
原本冗长重复的三行数据,经过GROUP BY的魔法,就变成了一行清晰、包含汇总信息的的数据: | 订单号 | 客户ID | 订单日期 | 商品种类数 | 商品列表 | 订单总金额 | | :--- | :--- | :--- | :--- | :--- | :--- | | A001 | 123 | 2023-10-27 | 3 | 手机,耳机,保护壳 | 5288.00 |
这样看起来是不是清爽多了?我们既得到了订单的主信息,又以一种紧凑的方式获取了其下属的所有明细的概况。
使用GROUP BY需要注意的几个坑
虽然GROUP BY很强大,但用的时候也得小心,不然很容易出错。
-
SELECT后面的非聚合列:当你使用了GROUP BY后,SELECT后面能直接出现的列有两种:一种是放在GROUP BY子句后面作为分组依据的列(比如上面的
order_id),另一种就是使用聚合函数(如COUNT,SUM)处理过的列,如果你SELECT了一个既没用于分组、也没用聚合函数处理的列(比如customer_name),而同一个订单组内这个客户名理论上应该是相同的,但MySQL的某些模式(如ONLY_FULL_GROUP_BY)会禁止这种行为,因为它无法确定你到底想输出组内的哪一个值(尽管它们看起来一样),为了代码的严谨性,最好保证SELECT的每一列都符合规则。 -
对分组后的结果进行筛选:HAVING子句:我们熟悉的WHERE子句是在分组前对数据进行过滤的,而如果我们想对分组后的结果进行筛选,只显示商品种类超过2个的订单”,该怎么办?这时候就不能用WHERE了,因为“商品种类数”是分组后才计算出来的概念,正确的做法是使用HAVING子句。
HAVING COUNT(order_items.product_id) > 2这条语句就会在分组计算完成后,只保留那些满足条件的组。 -
多字段分组:分组的标准不止一个,你想统计每个班级(class_id)里男女生(gender)的人数,这时候你就可以使用
GROUP BY class_id, gender,MySQL会先按班级分组,然后在每个班级内部再按性别进行细分,最终得出每个班级下男性和女性的独立计数。
总结一下
当你进行多表查询,特别是有一对多关系时,出现数据行数增多和“重复”是正常现象,这恰恰是关系型数据库正确工作的表现,GROUP BY并不是用来消除“错误重复”的,而是用来将这种展开的、重复的关系型数据,按照你的业务需求重新聚合和汇总的强大工具,它通过分组和聚合函数,将细节数据提炼成有意义的摘要信息,非常适合用于生成报表、统计概览等场景,下次再被复杂的查询结果困扰时,不妨想想GROUP BY,它很可能就是帮你理清头绪的那把钥匙。 综合参考了常见的SQL编程实践、MySQL官方文档关于聚合函数的说明以及多个技术社区如Stack Overflow上关于GROUP BY用法的讨论。)

本文由度秀梅于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/83696.html