加快程序运行用Redis循环试试看,感觉能提升效率不少吧

用户提到“加快程序运行用Redis循环试试看,感觉能提升效率不少吧”,这个想法其实挺有意思的,但里面有个关键点需要特别注意:Redis本身并不是靠“循环”来提升效率的,恰恰相反,在大多数高性能场景下,我们要想方设法避免在Redis里进行复杂的循环操作,用户可能把“使用Redis”和“用循环逻辑处理”这两个概念混在一起了,我来试着把这里面的门道拆开讲讲,就用最直白的大白话。
你想啊,Redis是个什么东西?它本质上是个放在内存里的超级快的小本本,程序要查什么数据,不用慢吞吞地去硬盘里翻数据库,直接问这个小本本要,它唰一下就能给你答案,所以它快的根本原因,是内存读写速度远超硬盘,以及它设计得非常精简,一件事一件事处理得飞快。

那“循环”又是什么呢?循环是你写程序时的逻辑,比如让你从一本厚厚的花名册里找出所有姓“张”的人,你一页一页地翻,一个人一个人地看,这个过程就是循环,如果你让Redis来做这个“循环”查找,问题就来了,Redis是个单线程的伙计,它一次只能专心致志地处理一个命令,如果你的循环很复杂,比如要遍历Redis里所有的键(key),找一个符合某种模式的数据,这个命令(KEYS *)一旦执行,Redis就得停下手里所有其他的活,专心帮你找,如果数据量特别大,这个查找过程可能会卡住好几秒甚至更久,在这段时间里,其他所有想来问问题的程序都得在后面乖乖排队等着,整个系统就好像“卡住”了一样,这哪是提升效率啊,这简直是制造交通堵塞。
正确的思路不是让Redis去“循环”,而是在把数据存进Redis的时候,就动脑筋设计好,让它根本不需要循环就能直接拿到结果,这就好比你不是等需要找所有姓张的人时再去翻花名册,而是提前就专门做了一个“张姓人员索引页”,需要的时候,直接翻到这一页,名字全在上面了。

举个例子吧,假设你运营一个论坛,有个很常见的需求是“显示用户的最新10条帖子”,最笨的办法是,每当有人要看这个页面,程序就去硬盘数据库里,循环遍历这个用户发的所有帖子,按时间排序,再取出最新的10条,用户一多,数据库肯定累得够呛,页面打开就慢。
用Redis该怎么“加快”呢?我们绝不循环,我们可以在用户每发表一篇新帖子时,就顺手做一件事:把这篇帖子的ID,塞进一个只属于这个用户的“帖子列表”里(Redis里叫List数据结构),而且我们总是塞到列表的最前面,这样,这个列表自然就是按发表时间从新到旧排好的,当需要显示最新10条帖子时,程序就直接向Redis发一个命令:“喂,把某个用户的那个帖子列表,从头开始给我10个元素。” Redis根本不用思考,也不用循环,瞬间就能给你结果,这个过程快如闪电,因为这就是一次直接的内存访问。

你看,我们通过提前准备数据、利用Redis现成的数据结构,把那个耗时的“循环查找+排序”的过程给消灭了,真正的效率提升来自于这里,来自于精心的设计,而不是让Redis去干它不擅长的循环苦力活。
再比如排行榜功能,游戏里要实时显示玩家的前十名,如果靠循环所有玩家数据来排序,每次有人查排行榜都得算一次,太慢了,用Redis的“有序集合”(ZSET)数据结构,每个玩家的分数实时更新进去,Redis自己就在内部维护好顺序了,你要前十名?一个命令 ZREVRANGE leaderboard 0 9 秒秒钟就返回了,这背后是Redis高效的数据结构在支撑,完全看不到循环的影子。
用户的想法方向是对的,用Redis确实能极大提升程序速度,但核心秘诀不是“循环”,而是“避免循环”,要把费时的计算和整理工作,分散到平时数据产生的时候(比如用户发帖、玩家得分时),通过一次次的简单操作,把结果“预计算”好,存成Redis里能直接拿取的样子,真正查询的时候,就变成一次简单的“按键索取”,这就像做饭,请客的时候你再手忙脚乱地切菜炒菜肯定慢,但如果你提前把菜都洗好切好配好,客人来了下锅一炒就上桌,那效率自然就高了。
下次想用Redis提速时,别琢磨怎么让它循环,多琢磨琢磨:“我能不能换个方式存数据,让它一步就能拿到我想要的东西?” 这才是把Redis这把快刀用在刀刃上。
本文由符海莹于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/83666.html
相关文章
-

MySQL报错MY-010613,ER_NDB_FLUSHING_TABLE_INFO问题,远程帮忙修复故障处理
-
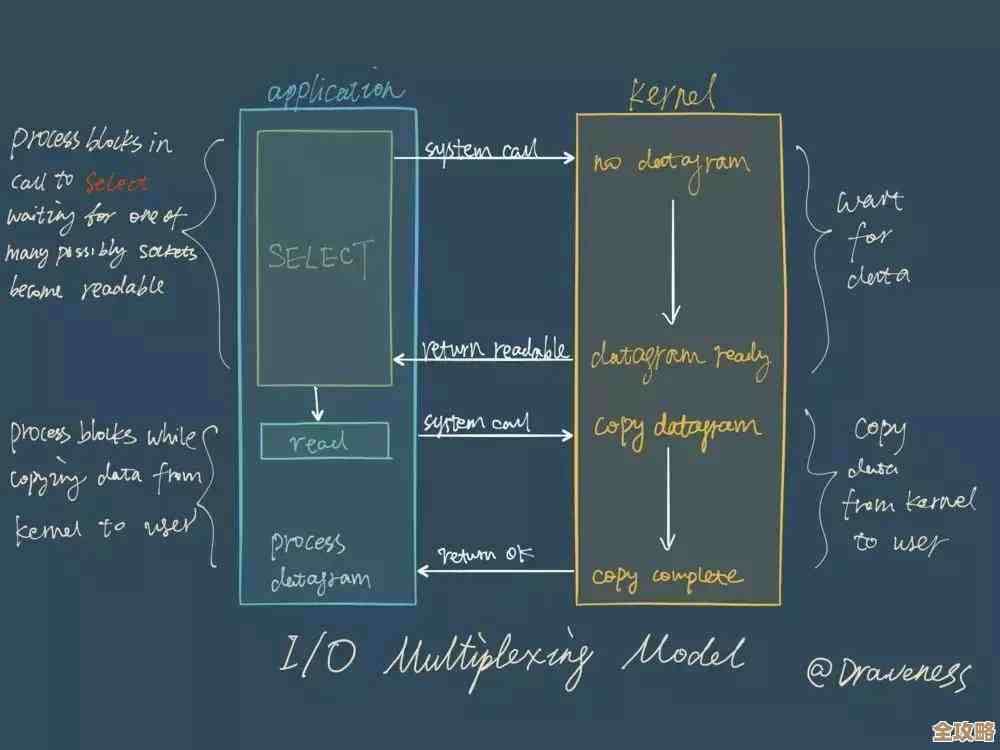
Redis里头搞非阻塞队列,这方法听起来挺新鲜也挺实用的,怎么实现的呢?
-

Redis运维那些事儿,怎么高效又专业地管好数据管理方案
-
MySQL多表查询老是重复?试试GROUP BY来搞定复杂结果吧
-
怎么省钱买服务器虚拟化许可证又不踩坑,选哪个划算还得看这些因素
-

ORA-12042报错咋整,单进程模式下改不了job_queue_processes远程帮忙修复
-
iOS数据库出错了怎么办,异常处理那些事儿怎么搞比较靠谱
-

用Redis来管控物联网接口访问,感觉挺实用也挺灵活的,能不能更快点响应呢



