数据库里那些重复数据咋找又怎么清理才靠谱呢?

主要综合自日常数据库管理与数据清洗的实践经验,并参考了像“SQL必知必会”这类基础数据库书籍中关于数据去重的通用思路,以及像“码农翻身”等技术博客中提到的实际案例教训。)
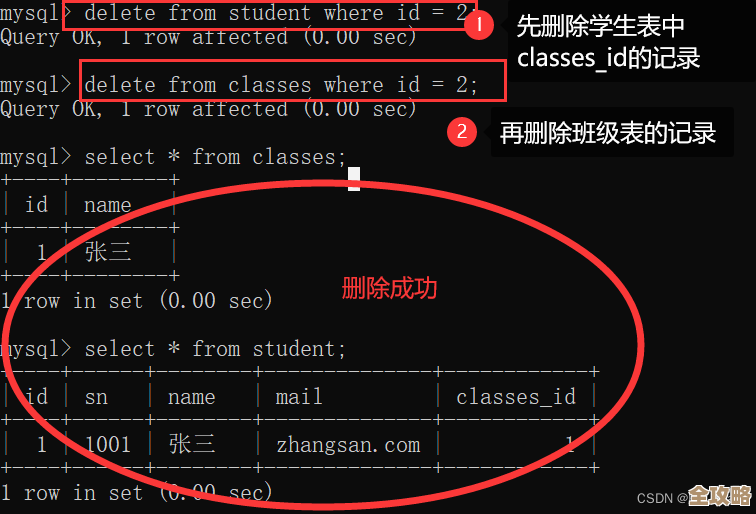
咱们得把话说前头:处理重复数据这事儿,没有一劳永逸的“万能钥匙”,方法完全取决于你的数据长啥样、重复是咋定义的,以及你的业务是干啥的,瞎搞一通,很容易把正确数据给删了,那可就捅大娄子了,核心就八个字:先找后判,再谨慎清理。
第一步:咋找重复数据?—— 把“李鬼”们都揪出来
找重复数据,不能光靠眼睛看,尤其是数据量大的时候,最常用的工具就是SQL查询语句。
-
最基本的找法:用
GROUP BY和HAVING这招最直接,你有一张用户表,你觉得“姓名”和“手机号”一样的就是重复数据,你就可以写个查询:SELECT 姓名, 手机号, COUNT(*) FROM 用户表 GROUP BY 姓名, 手机号 HAVING COUNT(*) > 1;这句话的意思就是:把表里所有记录按照“姓名”和“手机号”分组,然后数一数每个组里有多少条记录,只把那些记录数大于1的组(也就是有重复的)显示出来,这样你就知道到底有哪些重复项了。 -
复杂点的找法:考虑“模糊重复” 有时候重复没那么明显。“北京朝阳区”和“北京市朝阳区”算不算重复?“张三丰”和“张三豐”(繁体字)算不算重复?这时候,光靠精确匹配就不行了。
- 处理空格和大小写:可以用SQL的函数先把数据“清洗”一下再比较,比如用
TRIM()去掉首尾空格,用UPPER()或LOWER()统一成大写或小写。 - 处理相似文本:对于公司名、地址这类,可能需要用到模糊匹配,比如计算两个字符串的相似度(Levenshtein距离等),但这通常需要数据库支持扩展函数,比较复杂,有时候不如导出来用Python或Excel处理方便。
- 处理空格和大小写:可以用SQL的函数先把数据“清洗”一下再比较,比如用
-
看完整记录:用窗口函数 光知道哪些字段重复了还不够,你得看到完整的重复记录是啥样,这时候可以用
ROW_NUMBER()这样的窗口函数。SELECT *, ROW_NUMBER() OVER(PARTITION BY 姓名, 手机号 ORDER BY 创建时间) as row_num FROM 用户表;这个查询会给每条记录加一个编号(row_num),在相同的姓名和手机号分组内,按创建时间排序,第一条是1,第二条是2,以此类推,这样,你一眼就能看出哪些是重复的(row_num > 1的),并且能看到每条重复记录的详细信息,方便后续判断。
第二步:咋判断留谁删谁?—— 这可是个技术活,更是责任活
找到重复数据后,千万别急着按“删除键”,你得先判断哪条数据是“对的”,或者决定怎么合并。
-
确定“黄金记录”的标准:啥叫最准确、最完整的数据?常见标准有:
- 时间最早/最晚:比如保留最先注册的记录,或者保留最近更新过的记录。
- 信息最全:保留非空字段最多的那条记录。
- 来源最权威:如果数据来自不同渠道,保留你认为最可靠的那个渠道的数据。
- 业务状态:比如保留状态是“已激活”的用户,删除“未激活”的。
-
一定要和业务部门沟通:这是最最最重要的一步!你是个技术执行者,但业务部门才是数据的主人,两个看起来一样的客户记录,可能销售同事知道其中一个已经成了大客户,有特殊的备注信息,如果你凭技术规则把重要的那条删了,麻烦就大了,把重复数据的样本拿出来,和相关同事一起定清理规则。
第三步:咋清理才靠谱?—— 胆大心细,留好后路
判断规则定好了,终于可以动手清理了,但必须像拆弹一样小心。
-
永远先备份!:在执行任何删除操作之前,务必把整张表或者至少是把筛选出来的重复数据导出备份到一个安全的地方,SQL里可以这样:
CREATE TABLE 用户表_备份 AS SELECT * FROM 用户表;万一删错了,还能有后悔药吃。 -
分批处理:如果重复数据量特别大,不要一次性全部删除,可以分批次进行,比如一次处理1000条,减少对数据库的压力和风险。
-
具体的删除方法:
- 删除明显的重复:如果你确定所有重复项都是多余的,只留一条(比如用上面窗口函数中row_num=1的那条),可以写删除语句,但这类语句写法比较绕,容易出错,一定要先在测试环境练习,并用
SELECT语句验证无误后,再换成DELETE执行。 - 合并数据:更常见的情况是,重复的记录里各有部分正确信息,比如A记录邮箱是对的但地址是空的,B记录地址是对的但邮箱是空的,这时候理想的处理不是简单删除,而是合并,可以创建一个新的“黄金记录”,从各条重复记录中取最准、最全的字段值,然后删除掉所有旧的重复记录,再插入这条新记录,这个过程可能比较手动,或者需要写复杂的脚本来实现。
- 删除明显的重复:如果你确定所有重复项都是多余的,只留一条(比如用上面窗口函数中row_num=1的那条),可以写删除语句,但这类语句写法比较绕,容易出错,一定要先在测试环境练习,并用
-
清理后要验证:清理完成后,再次运行第一步的查找重复数据的查询,确认重复项已经消失了,抽查一些数据,确保没有误伤。
最后总结一下: 处理数据库重复数据,核心是流程和谨慎。找要全面,考虑各种重复情况;判要明智,多和业务沟通;删要稳妥,备份先行,操作谨慎,把它当成一个小的项目管理来做,而不是一个简单的技术操作,这样才能真正“靠谱”地把数据库打扫干净。

本文由瞿欣合于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/83540.html