Redis连接池用着序列化慢?来聊聊那些优化的小技巧和实践经验

很多人刚开始用Redis的时候,会觉得速度已经很快了,但集成到自己的大项目里,尤其是在高并发场景下,偶尔会感觉“卡卡的”,没有想象中那么快,这时候,问题很可能不是出在Redis服务器本身,而是出在客户端,特别是连接池的使用和序列化方式上,今天我们就来聊聊一些实实在在的优化小技巧和经验。
咱们得搞清楚连接池是干嘛的,为啥用不好会慢。
你可以把Redis连接池想象成一个“出租车候客点”,如果没有连接池,每次你的程序需要和Redis说话(比如存一个数据),都得现场去叫一辆出租车(创建连接),说完话出租车就开走了(关闭连接),高并发的时候,就像上下班高峰期,成千上万的人同时叫车,马路上全是找车和下车的人,交通肯定堵死了,创建和关闭TCP连接是非常消耗CPU和网络资源的过程。
连接池就是解决这个问题的,它预先维护了一堆空闲的连接(出租车在候客点排队),你的程序需要时,直接从池子里借一个用,用完了还回去,避免了频繁的创建和销毁,如果池子配置不当,反而会成为瓶颈。
- 池子太小:就像候客点只有5辆出租车,但高峰期有100个人要打车,大部分人只能干等着,导致请求排队,感觉就很慢。
- 池子太大:如果维护了上千个空闲连接,Redis服务器需要消耗大量内存来维护这些连接上下文,可能把服务器资源耗光,拖慢整体性能。
优化连接池的关键是找到“黄金尺寸”。 这个没有标准答案,得根据你的业务压力来测试,一般建议是,池的大小设置成你的应用服务器最大线程数的1到2倍就差不多,比如你的Web服务器线程池最大200线程,那Redis连接池设置成200到400之间可能比较合适,你需要不断地压测,观察Redis服务器的CPU、内存以及客户端的请求延迟,来调整这个数值。

聊完了连接池,另一个性能“隐形杀手”就是序列化。
你的程序里的数据,无论是字符串、对象还是列表,在网络上传输前,必须转换成二进制数据,这个过程就是序列化,从Redis读回来的二进制数据,要转换回程序能识别的格式,就是反序列化,这个过程如果效率低下,会比网络通信本身还要耗时。
很多人为了省事,直接使用编程语言自带的默认序列化方式,比如Java的JDK序列化,这种方式虽然方便,但产生的数据体积大,速度也慢,是性能的“大敌”。

优化序列化,核心思路就两条:选更快的算法,生成更小的数据。
-
选择高效的序列化协议:别再使用默认的序列化方式了,现在有很多优秀的第三方序列化库,它们在速度和数据大小上做了极致优化,在Java世界里,Protocol Buffers、Kryo、FST、Jackson(用于JSON)等都是非常好的选择,根据一些公开的基准测试(来源:Github上各类序列化库的Benchmark项目),这些库的性能通常远超JDK自带的序列化,序列化后的数据体积可能只有JDK的一半甚至更小,数据小了,网络传输就快,Redis存储也节省空间。
-
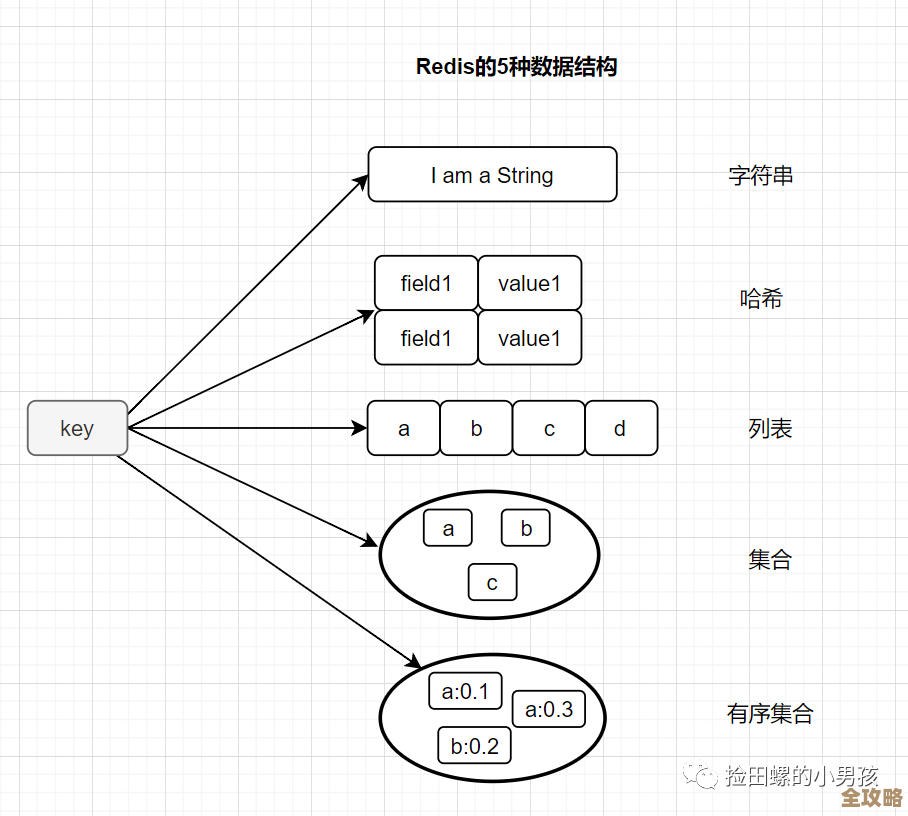
选择合适的数据结构:这一点经常被忽略,但它和序列化息息相关,Redis支持多种数据结构,比如String、Hash、List、Set等,如果你把一个复杂的Java对象整个序列化成JSON字符串,然后存成一个String键值对,那么每次修改对象中的一个小字段,都必须把整个对象读出来(反序列化),修改,再整个写回去(序列化),这非常浪费。
- 最佳实践:如果对象字段很多且经常需要单独修改,应该使用Redis的Hash结构来存储,把对象的每个字段存成Hash的一个field-value对,这样,你可以直接使用
HSET命令修改单个字段,避免了整个对象的序列化和反序列化开销,速度提升非常明显。
- 最佳实践:如果对象字段很多且经常需要单独修改,应该使用Redis的Hash结构来存储,把对象的每个字段存成Hash的一个field-value对,这样,你可以直接使用
还有一些结合性的实践经验:
- 管道(Pipeline)技术:当你需要连续执行多个Redis命令时(比如一个循环里插入了100条数据),使用管道可以把多个命令打包,一次性地发送给Redis服务器,服务器处理完后再一次性返回结果,这极大地减少了网络往返次数(RTT),在高延迟网络环境下效果尤其显著,这相当于把100次单独的“打车往返”变成了一辆“大巴车一次性运送”,效率自然高,但要注意,管道内的命令数量也不宜过多,避免单次传输数据量太大。
- 监控与诊断:光靠猜是不行的,务必开启Redis的慢查询日志(slowlog),它能帮你记录执行时间超过指定阈值的命令,当你感觉慢的时候,去查一下慢日志,很可能会发现罪魁祸首是某个复杂度为O(N)的键查询,或者一个巨大的对象序列化操作,监控连接池的各项指标,如活跃连接数、空闲连接数、等待获取连接的线程数等,能帮你判断连接池是否成了瓶颈。
想让Redis真正“飞”起来,不能只指望服务器配置,从客户端入手,配好连接池这个“调度中心”,选对序列化这把“翻译官”,再灵活运用管道这种“批量处理”技巧,并辅以持续的监控,才能最大限度地榨干Redis的性能潜力,这些优化点看似微小,但在百万、千万级别的请求量下,每一点改进带来的收益都是非常可观的。
本文由太叔访天于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/83455.html