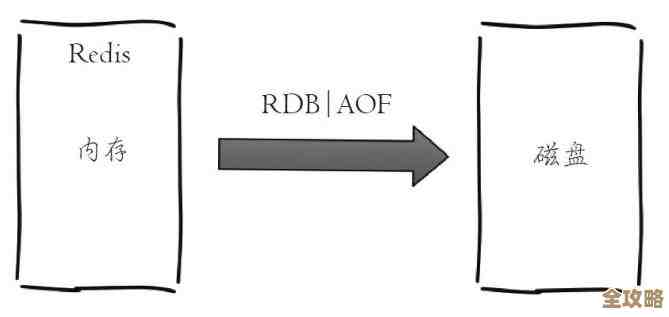
Redis 断线了别慌,这些配置能帮你自动重连更稳更快

(引用来源:Redis官方文档、阿里云开发者社区、部分技术博客实践经验总结)
Redis断线了别慌,这些配置能帮你自动重连更稳更快
你是不是也遇到过这种情况:程序跑得好好的,突然就因为Redis连接断了而报错,服务跟着就出问题了,手动去重启应用又不是个事儿,这时候就体现出自动重连的重要性了,不管是官方自带的客户端,还是像Jedis、Lettuce这些常用的Java客户端,都提供了丰富的配置选项来帮你优雅地处理断线重连,下面我们就来聊聊怎么配置能让你的应用在Redis断线时更“坚强”。
核心思路:别等断了才想起来,要一直保持“心跳”
自动重连不是等到连接彻底断了才去尝试,那样就太被动了,聪明的做法是,在连接还健康的时候,就不断地检查它,一旦发现苗头不对(比如网络轻微波动),就提前采取措施,或者立刻启用备用方案,这套机制主要靠三样东西:连接池、心跳检测和重试策略。
具体配置怎么玩(以常见的Jedis和Lettuce为例)
-
Jedis的配置要点

Jedis本身比较直接,它的重连能力很大程度上依赖于连接池的健康检查。
- 连接池是关键:你一定要用连接池(如JedisPool),而不是每次都创建新的连接,连接池能帮你管理连接的“生命”。
- 配置
testOnBorrow和testOnReturn:这两个参数建议至少开启一个,设置testOnBorrow=true,意思是每次从连接池借出连接给程序用之前,都会先执行一个简单的命令(比如PING)测试一下连接是否还通,如果不通,连接池会悄悄丢弃这个坏连接,然后给你一个新的,这样你的程序几乎感知不到断线,缺点是频繁测试会有一点点性能开销,但对于大多数应用来说,稳定性提升更值得。 - 配置
testWhileIdle:这是个更好的选择,设置testWhileIdle=true,并配合timeBetweenEvictionRunsMillis(比如设置为30000毫秒,即30秒),意思是让连接池在后台每隔一段时间,就扫描一下那些闲置的连接,对它们进行健康检查,发现无效连接就清理掉,这样既保证了连接可用性,又避免了每次借出时的性能损耗。 - 设置合理的超时时间:
connectionTimeout(建立连接超时)和soTimeout(socket读取超时)一定要设置,别用默认的0(无限等待),比如都设为2000毫秒,这样网络出问题时,客户端不会傻等,会快速抛出异常,让你能进入重试逻辑。
(引用来源:Jedis GitHub仓库的Wiki和Issue讨论)
-
Lettuce的配置要点(推荐用于新项目)
Lettuce是更高阶的客户端,它默认就支持自动重连,而且是在网络层面更底层、更高效。

- 开启自动重连:这是最基本的,通常默认就是开的,你可以在创建连接时显式设置:
ClientOptions.builder().autoReconnect(true).build(),Lettuce会在连接断开后,自动在后台默默重连,应用代码几乎无感。 - 配置重连策略:Lettuce的重连策略更智能,你可以通过
RedisURI设置重试的间隔策略。RedisURI redisUri = RedisURI.builder() .withHost("redis-server") .withPort(6379) .withTimeout(Duration.ofSeconds(2)) .withReconnectDelay(Duration.ofSeconds(1)) // 首次重连延迟1秒 .withRecoveryOptions(ReconnectRecoveryOptions.builder() .reconnectAttempts(3) // 快速重试3次 .fixedDelay(Duration.ofSeconds(5)) // 如果快速重试失败,之后每隔5秒重试一次 .build()) .build();这样的配置意味着:断线后立刻开始重连,先快速试3次(间隔1秒),如果还连不上,就降级为每隔5秒稳健地重试,直到成功,这种指数退避或混合策略能有效避免在Redis服务器短暂压力大时,所有客户端一窝蜂地去重连,造成“惊群效应”。
- 启用心跳保活:Lettuce默认会发送TCP Keep-Alive来保持连接,但你也可以配置应用层的心跳(PING),通过
ClientOptions设置pingBeforeActivateConnection为true,在连接激活前先PING一下,确保可用。
(引用来源:Lettuce官方文档)
- 开启自动重连:这是最基本的,通常默认就是开的,你可以在创建连接时显式设置:
超越客户端配置:应用层的“双保险”
光靠客户端配置还不够稳妥,因为重连需要时间,在这段空窗期,你的应用怎么办?
- 设计重试机制:在你的业务代码里,当执行Redis命令失败时,不要立刻报错返回,可以加入一个简单的重试逻辑,捕获连接异常后,休眠几百毫秒,然后重试2-3次,如果重试几次后还不行,再抛出异常或降级处理(比如去查数据库),这样可以应对非常短暂的网络抖动。
- 设置熔断降级:对于非常重要的应用,可以考虑引入熔断器(如Hystrix、Resilience4j),当一段时间内Redis失败次数超过阈值,熔断器会“跳闸”,短时间内直接拒绝所有请求(快速失败),而不是让线程卡住等待,你可以提供一个降级方案,比如返回一个默认值,或者将数据暂存到本地内存/磁盘,等Redis恢复后再同步过去,这保证了核心业务流程不被一个依赖组件拖垮。
- 监控与告警:配置了自动重连不代表万事大吉,你一定要监控客户端的重连事件和错误日志,当控制台开始频繁打印重连日志时,说明你的Redis服务或网络可能出现了需要人工介入的严重问题,这时候告警系统就该发挥作用了。
总结一下
面对Redis断线,我们不能慌,而是要通过合理的配置把主动权抓在自己手里。对于Jedis,重点打磨连接池的健康检查和超时设置;对于Lettuce,则要利用好其强大的自动重连和重试策略。 在应用层面辅以重试和降级逻辑,构成多道防线,没有一劳永逸的配置,你需要根据自己业务的网络环境和容忍度,调整这些参数(比如超时时间、重试次数和间隔),并进行充分的测试,才能找到最适合你的那个“黄金组合”,这样,当网络波动再次来袭时,你的应用就能像打不倒的“小强”一样,稳如泰山。
本文由歧云亭于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82701.html