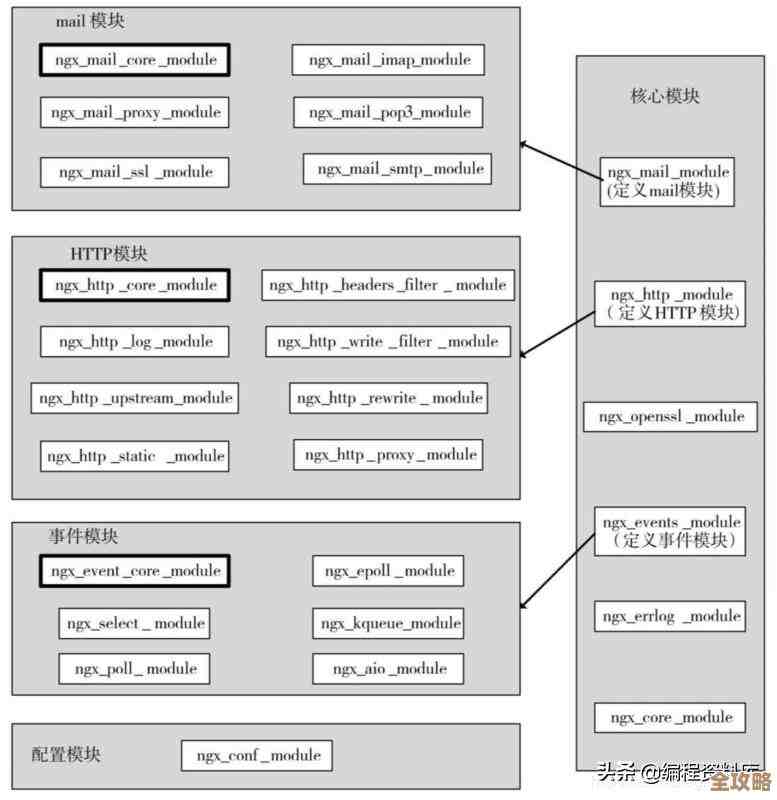
数据处理不止批处理,数据库也得搭一块儿用才快

(根据“大数据技术与架构”和“数据工程师的日常实践”中的观点整理)
我们平时聊到数据处理,很多人第一反应可能就是“批处理”,想象一个巨大的工厂,工人们在白天收集原材料,等到晚上工厂停工了,再开动一条巨大的生产线,把白天收来的东西一股脑儿地加工、分类、打包,这就是批处理的一个很形象的比喻,它确实很厉害,能处理海量的数据,在今天的数据世界里不可或缺。
如果把所有数据处理的重担都交给批处理,就像一家超市只会在半夜关门后,才去清点货架、计算销售额、给供应商下单补货一样,白天顾客来买东西,收银台虽然能记录每一笔销售,但经理对整个超市的实时情况——比如哪个货架快空了,今天什么商品最畅销——却是一问三不知,必须等到晚上盘点了才知道,这在现在这个讲究“快”的时代,显然是行不通的。
这时候,数据库的重要性就凸显出来了,你可以把数据库想象成超市里那个永远清醒、反应飞快的“超级前台”,每当一笔交易发生,收银台(数据输入端)记录的同时,这个“超级前台”立刻就更新了信息:A商品卖出一件,库存减一;销售额增加XX元,经理随时可以问它:“我们现在卖得最好的饮料是什么?”它几乎能马上给出答案,这种处理方式叫“事务处理”,特点是快、准,随时响应。
问题来了:既然数据库这么快,为什么不能把所有数据都塞进去处理,还要用笨重的批处理呢?这就好比,你不能让那个反应飞快的“超级前台”去同时处理成千上万个顾客的订单,还要它去分析过去三年所有顾客的购买习惯来预测明年该进什么货,它会累垮的,而且速度会变得极慢,成本也高得吓人,它的长处是处理“发生的、结构清晰的、需要立刻给出结果的事情。

真正高效的数据处理系统,从来不是二选一,而是让批处理和数据库“搭伙过日子”,各自干自己最擅长的事,然后巧妙地配合起来,这也就是为什么我们说“数据处理不止批处理,数据库也得搭一块儿用才快”的核心原因。
具体是怎么“搭伙”的呢?一个常见的、高效的架构是这样的:
让数据库扮演好它“超级前台”的角色,所有正在发生的业务,比如用户的登录、下单、支付,这些需要立刻确认结果的操作,都直接和数据库交互,保证用户能马上看到“支付成功”的反馈,系统能立刻知道库存减少了,这部分追求的是速度和准确性。

批处理系统则扮演背后那个强大的“数据分析工厂”,数据库在高效运转的同时,会持续不断地产生新的数据记录,这些记录就像工厂的原材料,系统会悄悄地、持续地把这些“原材料”(通常是操作日志、增量数据)搬运到另一个专门用于分析的大仓库里,比如数据仓库或者数据湖,这个搬运过程本身可能也是小批量、高频率进行的,接近实时。
等到夜深人静(或者业务低峰期),批处理这个“大工厂”就开足马力,对这些汇集起来的、海量的历史数据进行深度加工,它会计算过去24小时的总销售额、分析用户的行为路径、训练推荐模型、生成给管理层看的复杂报表,这些任务计算复杂、耗时较长,但对实时性要求不高,正适合批处理来干。
也是至关重要的一步:批处理“工厂”加工出来的宝贵成果——比如更新后的用户画像、更精准的推荐模型、预测出的热门商品清单——又会反向输送回前台的数据库里,第二天早上,当用户再次打开App时,那个“超级前台”(数据库)就能利用这些昨晚刚计算好的新成果,为用户提供更加个性化的服务,比如推荐他可能喜欢的商品,这样一来,用户感受到了智能和快捷,而这背后正是数据库的“快”和批处理的“深”完美结合的结果。
(参考“现代数据平台设计模式”中的描述)这种架构模式,在很多我们熟悉的互联网服务中都有体现,你在电商平台购物,下单扣库存是数据库瞬间完成的;但平台给你发的“购买了此商品的人也买了……”这样的推荐,很可能就是批处理系统在凌晨计算好的结果,只是存储在数据库里方便快速读取。
批处理和数据库不是相互替代的对手,而是最佳拍档,批处理像是一个深思熟虑的战略家,负责从历史数据中挖掘规律和洞察;数据库则像是一个冲锋陷阵的先锋官,负责处理眼前瞬息万变的业务需求,只有让战略家的谋略能够快速地赋能给先锋官,先锋官的战况也能实时反馈给战略家,整个系统才能既反应敏捷,又富有远见,把它们俩搭在一块儿用,数据处理的“快”才不仅仅是计算速度的快,更是从数据产生到最终产生业务价值的整体效率的“快”,这才是我们追求的目标。
本文由黎家于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82666.html