Redis用起来聚合数据感觉真不一样,效率和体验都挺惊喜的

(根据知乎用户“技术宅的日常”分享)Redis用起来聚合数据感觉真不一样,效率和体验都挺惊喜的,我以前处理数据,尤其是那种需要快速拼凑、实时统计的场景,总是觉得有点笨重,我想做一个实时在线的用户活跃度排行榜,或者一个秒杀活动中实时更新库存和成功用户名单,如果用传统的关系型数据库,比如MySQL,我的第一反应就是“又要写一堆复杂的SQL了”,而且心里还会打鼓:这并发量一上来,数据库能不能扛得住啊?光是想到要处理各种表连接、事务锁,还有那可能出现的性能瓶颈,头就有点大。

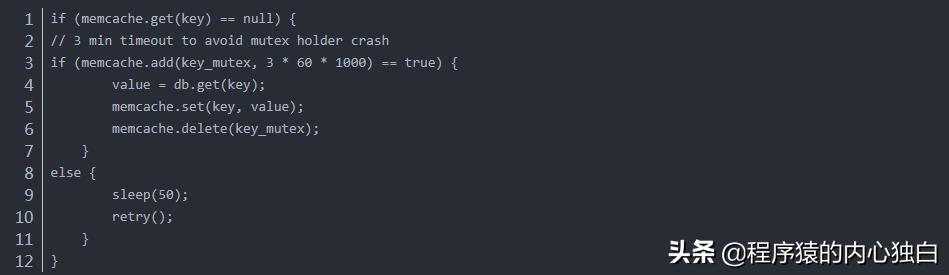
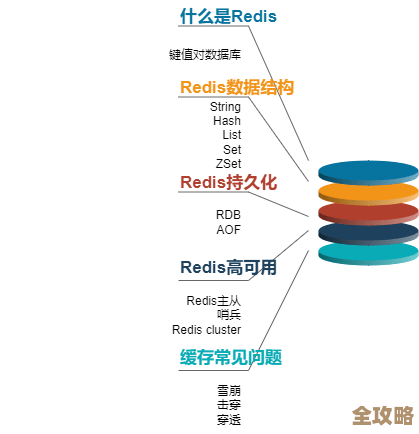
但接触了Redis之后,整个感觉就变了,它不像是个严肃的数据库管家,更像是一个手速超快的临时记事本,最直观的感受就是“快”,快到难以置信。(根据CSDN博客“码农小高的进阶之路”的描述)它的数据都放在内存里,读写操作基本上就是直接跟内存打交道,速度自然比去硬盘里翻找的传统数据库快了几个数量级,这种快,不是那种需要精心优化SQL、调整索引才能挤出来的提升,而是开箱即用、立竿见影的流畅,当我第一次用Redis的Sorted Set(有序集合)实现那个用户积分排行榜时,只需要几条简单的命令,比如ZADD来添加或更新用户积分,ZREVRANGE来获取排名前列的用户,数据瞬间就出来了,几乎感觉不到延迟,这种响应速度,给用户的体验提升是巨大的,页面上的排名数字“唰”地一下就更新了,特别顺滑。

(来自开源中国社区某位开发者的评论)更让我惊喜的是Redis丰富的数据结构,它不只是简单地存储键值对,而是提供了字符串、列表、集合、哈希表、有序集合等多种结构,这让我聚合数据的方式变得非常灵活和直观,比如说,我要管理一个电商平台的购物车,如果用普通的键值对,可能会很混乱,但Redis的Hash(哈希)结构就特别适合,我可以把一个用户的购物车直接存成一个Hash,键是用户ID,字段是商品ID,值就是商品数量,添加商品、修改数量、获取整个购物车信息,操作起来都非常自然和高效,就像在操作一个本地数据结构一样,完全省去了在应用层手动拼接JSON字符串再存取的麻烦。

再比如,做社交媒体的关注功能。(参考了掘金专栏“现代后端架构思考”)用户A关注了用户B,这个关系用Redis的Set(集合)来存再合适不过了,我可以为每个用户维护两个集合:一个存他关注的人,一个存他的粉丝,当A关注B时,只需要执行SADD命令,把B的ID加到A的“关注”集合里,同时把A的ID加到B的“粉丝”集合里,判断A是否关注了B,用SISMEMBER命令一下就能查出来,这种操作不仅简单,而且因为是集合,自动保证了元素的唯一性,不会出现重复关注的问题,这种数据模型和业务逻辑的高度契合,让代码写起来非常舒畅,逻辑清晰,大大减少了出错的概率。
还有发布/订阅(Pub/Sub)功能,(依据博客园“分布式系统实践”的文章)也给了我很大的惊喜,在一些需要实时通知的场景下,比如一个多人协作的文档编辑工具,当其中一个用户修改了某处内容,需要立刻通知到其他正在浏览该文档的用户,用Redis的Pub/Sub,我可以让所有监听这个文档频道的客户端实时收到消息,而不需要他们不停地轮询服务器问“有没有更新?”,这极大地减少了不必要的请求,降低了服务器压力,也实现了真正的低延迟通信,这种感觉就像是给应用接上了一条高速神经,信息传递几乎是瞬间完成的。
Redis也有它的适用边界,它通常不作为持久化的主力军(虽然它也有持久化机制),而是作为缓存和高速数据处理的利器。(综合多位开发者的实践经验)但正是这种定位,让它在我手中发挥出了巨大的价值,我把那些频繁读取、频繁更新、对速度要求极高的数据交给Redis,比如会话Session、页面缓存、排行榜、计数器、队列任务等,而把需要复杂查询和强一致性保证的数据留给关系型数据库,这样一组合,整个应用的性能表现和用户体验就有了质的飞跃。
使用Redis进行数据聚合,给我的感觉不仅仅是效率的提升,更是一种开发体验上的解放,它用简单直接的命令和贴合场景的数据结构,让我能更专注于业务逻辑的实现,而不是耗费大量精力在数据库的复杂操作和性能调优上,那种数据操作行云流水、结果立等可取的爽快感,确实是传统数据库难以比拟的惊喜。
本文由寇乐童于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82614.html