怎么才能让Redis缓存的数据量飙升性能又不掉,聊聊那些实用技巧和注意点

想让Redis缓存的数据量变大,同时还能保持飞快的速度,这事儿就像是在一个小仓库里既要塞进海量的货物,又要保证随时能快速找到并取出任何一件,搞不好就会变得又慢又卡,下面就来聊聊具体怎么操作,有哪些坑得避开,主要参考了Redis官方文档的一些设计理念,以及一些大型互联网公司的实战经验总结。
第一招:别把Redis当垃圾场,关键在于精简数据
很多人一上来就拼命往Redis里塞数据,却忘了最重要的一点:Redis是纯内存数据库,内存比硬盘金贵得多,第一条核心技巧就是别存没必要的东西。
- 只存热数据:Redis不是数据库的备份,你应该只把那些被频繁访问的“热数据”放进来,网站首页的商品信息、热门文章的详情,这些访问量巨大的数据才值得缓存,那些一年也看不了几次的冷数据,就别占地方了。
- 改造数据模型,让它更“瘦”:直接缓存从数据库里拿出来的完整对象(比如一个包含几十个字段的JSON字符串),往往很浪费,你应该根据前端的实际需要,进行裁剪,一个用户对象,列表页可能只需要id、头像、昵称三个字段,那你就只缓存这三个字段,而不是把用户的邮箱、地址、个人简介全存上,这叫按需缓存,根据《Redis实战》中的建议,精细化的数据结构设计能极大节省空间。
- 使用更高效的数据结构:Redis提供了多种数据结构,选对了能省下大量内存,存储用户的点赞状态(用户ID -> 是否点赞),用String类型一个个存就很亏,改用Set(集合)或者更节省空间的HyperLogLog(用于统计基数)可能会是更好的选择,又比如,存储短小的字符串,Redis内部有优化机制,但如果你存的value非常大,就要考虑拆分或压缩了。
第二招:给数据设置“保质期”和“淘汰规则”
内存是有限的,数据不能只进不出,你必须明确告诉Redis,当内存快满的时候,该怎么办。
- 一定要设置TTL(生存时间):除非是极少数需要永久存储的配置信息,否则给你缓存的每一个键都合理地设置一个过期时间,这能保证无效的、过时的数据能被自动清理掉,防止缓存被“撑爆”,这个时间设置多长,要根据业务来定,比如热门商品缓存1小时,一些配置信息可以缓存1天。
- 配置合理的淘汰策略:这是保证性能不掉的关键!在Redis配置文件里,有个叫
maxmemory-policy的设置,千万别用默认的noeviction(不淘汰),这会导致内存满了之后所有写请求都失败,常用的策略有:allkeys-lru:尝试淘汰所有键中最近最少使用的,这是最通用的选择,能确保最热的数据留在内存里。volatile-lru:只淘汰设置了过期时间的键中最近最少使用的,如果你能严格区分永久数据和临时数据,这个策略也不错。allkeys-random或volatile-random:随机淘汰,开销最小,但可能把热点数据淘汰掉,一般不太推荐。
第三招:水平扩展,一个Redis不够就上多个
当单台Redis服务器的内存确实无法满足你的数据量时,就要考虑分布式方案了,也就是把数据分到多个Redis实例上。
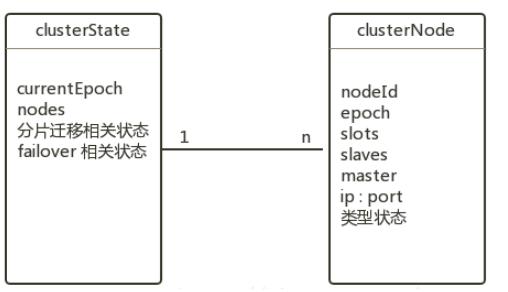
- Redis Cluster(集群模式):这是官方推荐的方案,它会把数据自动分片(sharding)到多个节点上,每个节点只存一部分数据,这样,数据量再大,只要增加节点就行了,它还具备高可用性,部分节点挂了不影响整体服务,这是应对超大数据量和保证高可用的终极武器,根据Redis官方文档,集群模式是处理海量数据集的标准方式。
- 客户端分片:在老版本或简单场景下,有些应用会在代码层面实现分片逻辑,比如根据用户ID的哈希值,决定把这个用户的数据存到哪台Redis上,但这种方式需要自己维护,增加了客户端的复杂性,而且扩容、缩容很麻烦,现在一般不建议使用了。
第四招:警惕那些看不见的性能杀手
数据量不大,但操作不当也会导致性能急剧下降。
- 避免“大Key”:单个String类型的value值过大(比如几百KB甚至几MB),在读取、删除、序列化/反序列化时都会非常耗时,会阻塞Redis的单线程,导致其他请求排队,解决方案是把大Key拆分成多个小Key,或者使用Hash等数据结构分段存储。
- 避免“热Key”:某个Key在瞬间被巨量的请求访问,可能会导致单个Redis实例CPU负载过高,解决方案是为热Key做副本,在应用层做本地缓存,或者使用Redis Cluster将请求分散。
- 避免复杂度过高的操作:比如一次性获取一个有几万成员的Set的所有值(
SMEMBERS命令),或者对一个大Hash进行HGETALL,这些操作会长时间占用Redis进程,应该使用SSCAN、HSCAN这样的游标命令分批遍历。 - 关注持久化带来的影响:无论是RDB快照还是AOF日志,在数据量巨大时,持久化过程都可能对性能产生影响,需要根据业务对数据丢失的容忍度,合理配置持久化策略,在从库上做持久化,减轻主库压力。
想让Redis在数据量飙升时依然坚挺,核心思路就三点:一是“省”, 通过精简数据模型和选择高效数据结构,把好钢用在刀刃上;二是“管”, 用TTL和淘汰策略做好数据生命周期管理,让缓存活水流动起来;三是“扩”, 当单机极限到来时,果断采用集群方案水平扩展,时刻警惕大Key、热Key这些细节问题,把这些技巧都用上,你的Redis缓存就能在承载海量数据的同时,继续保持风驰电掣的速度。

本文由水靖荷于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/82489.html