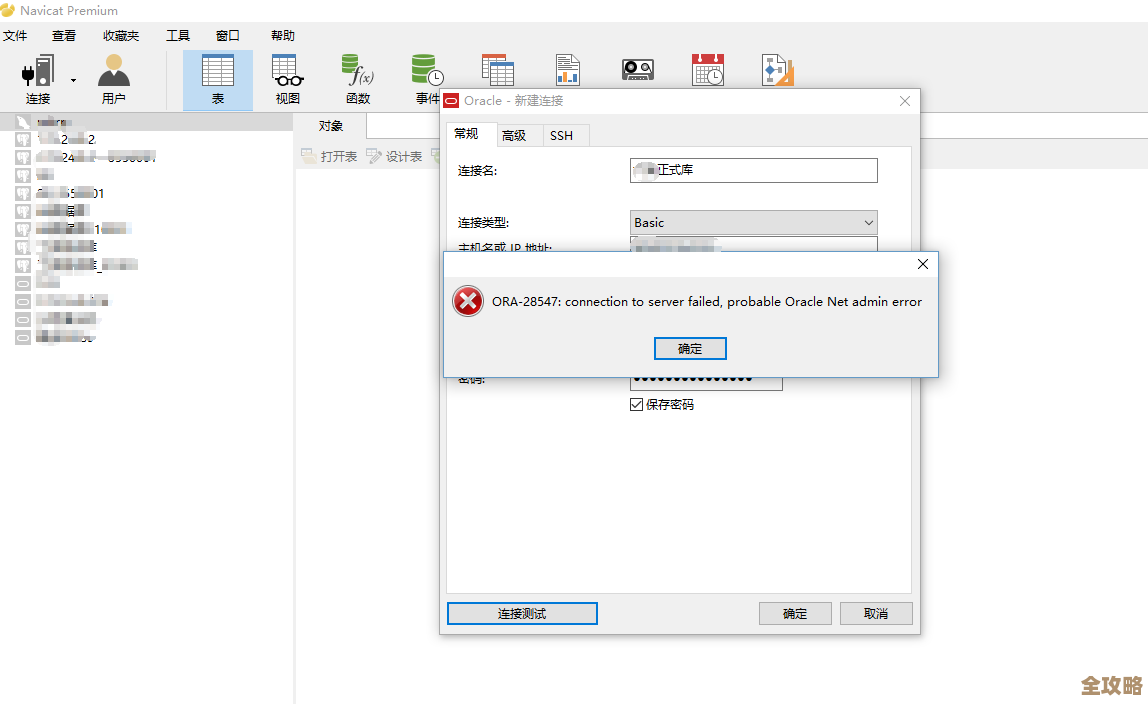
ORA-55506错误导致事务异常,远程帮忙修复故障全过程解析

那天下午,我接到一位朋友的紧急电话,他负责维护公司的一个核心业务系统,系统突然出现了严重问题,用户在尝试办理某个关键业务流程时,界面一直卡住,最后提示操作失败,他们检查后台的数据库日志,发现了一个之前从未见过的错误代码:ORA-55506,这个错误让他和团队束手无策,因为常规的数据库排查手段似乎都失效了,业务已经完全中断,压力巨大,我决定通过远程连接的方式,协助他一起排查和解决这个棘手的问题。
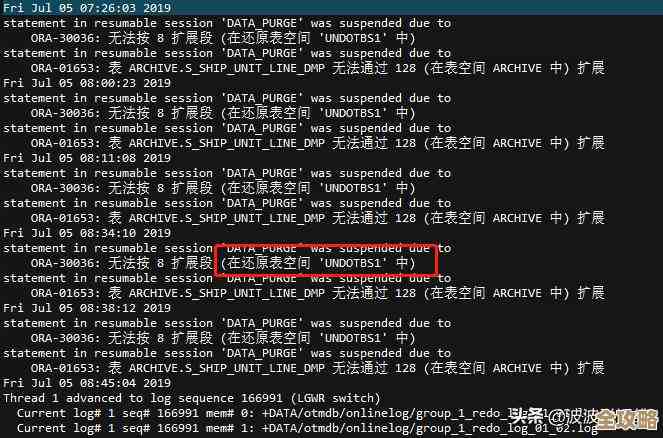
连接上他们的数据库服务器后,我首先让他复现了一下导致问题的操作,我让他打开数据库的告警日志文件(alert log),根据他的描述和我的经验,ORA-55506错误通常与Oracle数据库中的一种高级功能——“闪回事务查询”(Flashback Transaction Query)相关,这个功能本意是用来追溯和诊断历史事务的,但在特定情况下,它自身可能会引发问题,果然,在告警日志中,我们除了看到ORA-55506的错误记录外,还伴随着一些关于“回滚段”(一种用来存储事务修改前旧数据的地方)无法扩展或状态异常的提示。
根据Oracle官方文档和一些技术社区(如Oracle Support官方知识库和OTN社区)的案例讨论,ORA-55506错误的根本原因往往是:当系统尝试为闪回事务查询功能分配必要的存储空间(特别是在撤销表空间或特定的回滚段中)时,由于某种原因失败了,常见诱因包括:撤销表空间不足、存在非常长的大型事务阻塞了清理过程、或者是数据库的相关内部参数设置不当。
基于这个思路,我们开始了逐步排查,第一步,我让他查询了当前数据库的撤销表空间使用情况,果然,发现撤销表空间的空闲空间已经所剩无几,并且存在大量处于“NEEDS RECOVERY”(需要恢复)状态的数据段,这表明系统正在因为空间紧张而挣扎,无法正常处理新事务所需的“撤销数据”的存储。
第二步,我们需要找出是哪个具体的事务或会话导致了这个问题,我让他执行了一个查询,用于查看当前长时间运行的事务和它们使用的撤销块数量,很快,我们锁定了一个已经持续运行了数小时的会话,这个会话关联着一个由某个批处理程序发起的复杂查询操作,该操作涉及的数据量非常大,正是这个长时间运行的事务,占用了大量的撤销空间资源,并且阻碍了系统正常回收旧的、不再需要的撤销数据,最终触发了ORA-55506错误。
原因找到了,解决方案就相对清晰了,我们面临两个选择:一是紧急扩容撤销表空间,这只是临时缓解,如果那个长事务不结束,空间很快又会被耗尽;二是终止那个罪魁祸首的会话,从根本上释放资源,由于业务已经中断,需要快速恢复,我们选择了第二种方案,在征得业务方同意后(因为这个操作会导致该会话正在执行的任务失败),我指导他使用数据库管理命令,强制终止了那个长时间运行的会话。
会话终止后,我们观察到撤销表空间的压力迅速下降,系统开始自动清理那些被标记为“需要恢复”的段,紧接着,我让朋友再次尝试执行之前失败的那个业务流程,这一次,操作顺利完成了,没有再报错,系统功能恢复正常。
问题虽然解决了,但为了防止未来再次发生,我们还做了一些后续工作,我建议他:第一,优化那个批处理程序的逻辑,避免在业务高峰时段执行这种可能长时间占用大量资源的重型查询;第二,适当增大撤销表空间的初始大小,并设置自动扩展属性,为系统留出更多缓冲余地;第三,建立监控机制,定期检查长时间运行的事务和撤销表空间的使用率,做到提前预警。
整个远程协助过程持续了大约一个半小时,从接到求助电话时的紧张,到一步步分析日志、定位根源、实施解决方案,最终看到系统恢复正常的如释重负,这个过程再次印证了系统化排查思路的重要性,ORA-55506这个看似生僻的错误,其背后往往隐藏着资源管理或应用设计上的问题,不能简单地当作一个孤立的错误代码来处理,通过这次事件,我的朋友也对数据库底层的事务和撤销机制有了更深刻的理解。

本文由太叔访天于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/81389.html