ORA-41683报错锁规则失败,远程帮忙修复故障怎么弄才行

ORA-41683报错是一个在Oracle数据库,特别是与Oracle GoldenGate复制技术相关的环境中可能遇到的错误,这个错误信息的完整描述通常是“Lock rule failure”,翻译过来就是“锁规则失败”,它意味着GoldenGate进程(通常是抽取进程Extract)在尝试获取源数据库表中某行数据的锁时,未能成功,从而导致进程中止。
要理解这个问题,我们得先知道GoldenGate是怎么工作的,GoldenGate的核心是实时捕获数据库的数据变更(增、删、改),为了实现这一点,它的抽取进程在读取数据库的重做日志(一种记录所有数据库变化的文件)以捕获变更数据时,为了保证数据在读取瞬间的一致性,它有时需要去源数据库上模拟一个查询,并尝试获取相关数据行上一个轻量级的锁,这个锁的目的不是阻止别人修改,而是为了确保GoldenGate“看”到的这行数据是一个一致的版本,而不是一个正在被其他事务修改到一半的、不完整的状态。
ORA-41683报错就发生在这个环节,当GoldenGate尝试获取这个“一致性锁”时,由于某些原因,这个请求失败了,失败的原因可能多种多样,但核心都围绕着“锁”的竞争或不可用。
根据Oracle官方支持文档(来源:Oracle Support Doc ID 1302537.1, 1419366.1)以及相关的故障处理指南,导致ORA-41683的常见原因主要有以下几类:
-
源数据库中存在激烈的锁竞争:这是最常见的原因,如果源数据库上正有长时间运行、未提交的事务(比如大批量的数据更新操作)一直占有着目标数据行上的锁,那么GoldenGate进程在尝试获取它需要的锁时,就可能因为等不到资源而超时失败,想象一下,你要用一间房间(数据行),但里面有人(另一个事务)一直锁着门不出来,你等得太久,只好放弃(GoldenGate报错)。
-
GoldenGate参数配置不当:GoldenGate有很多参数来控制其行为,其中一些与锁相关的参数设置不合理,也可能导致此问题。
LOCKTIMEOUT参数:这个参数定义了抽取进程等待锁的最长时间(单位秒),如果设置得太短(比如默认的30秒),在数据库稍有繁忙时,就可能因为等不及而超时。TRANSACTIONTIMEOUT参数:这个参数设定GoldenGate等待一个事务完成的最长时间,如果一个事务运行时间超过此设定,GoldenGate可能会采取行动(如跳过该事务),过程中也可能引发锁问题。
-
数据库层面的问题:
- 延迟块清除(Delayed Block Cleanout):当一个事务提交后,它所占用的锁资源会被释放,但某些数据块头部的事务信息可能不会立即被清理,当GoldenGate去读取这些块时,它会尝试进行“块清除”,这个过程也可能需要获取锁,如果遇到问题,会间接导致41683错误。
- 索引组织表(IOT)或特定表类型:某些特殊的表类型,如索引组织表,在GoldenGate处理时可能需要不同的锁机制,更容易触发此类错误。
远程帮忙修复故障的思路和步骤
当远程协助处理这个问题时,由于无法直接接触服务器,修复过程主要依赖于通过远程桌面、SSH连接或数据库客户端工具进行诊断和操作,以下是通用的排查和解决步骤:
第一步:立即行动,检查当前状态
- 查看GoldenGate状态:首先使用GoldenGate命令行接口(GGSCI),执行
INFO ALL命令,确认报错的是哪个进程(通常是EXTRACT进程),并记下其状态(ABENDED)和对应的序列号(Seqno)。 - 检查报告文件:使用
VIEW REPORT <进程名>命令,仔细查看该进程的报告文件,在错误发生时间点附近,除了ORA-41683错误本身,通常还会有更详细的上下文信息,比如是在处理哪个表、哪个SQL语句时失败的,这能为我们提供最重要的线索。
第二步:分析根本原因 根据报告文件中的信息,结合对源数据库的检查来判断原因。
- 检查源数据库锁情况:连接到源数据库,查询动态性能视图(如
V$LOCK,V$SESSION,DBA_BLOCKERS等),寻找是否有长时间阻塞其他会话的锁存在,重点观察阻塞会话正在执行的SQL、已经等待了多久,如果发现是某个特定事务导致的,可以尝试与应用程序团队沟通,看是否能尽快提交或回滚该事务。 - 检查长时间未提交的事务:查询类似
V$TRANSACTION的视图,看看是否有存活时间非常长的事务,这些事务是锁竞争的温床。
第三步:采取针对性解决措施 根据原因分析结果,选择以下一种或多种方法:
-
调整GoldenGate参数(最常用且有效的办法):
- 增加
LOCKTIMEOUT值:如果判断是锁等待时间不足,可以适当增加这个值,将默认的30秒增加到300秒甚至更长,在GGSCI中,使用ALTER <进程名>, LOCKTIMEOUT 300来在线修改。 - 调整
TRANSACTIONTIMEOUT参数:如果报告文件提示与长事务有关,可以适当调整此参数,但需谨慎,因为设置过长会影响资源占用,设置过短可能导致事务被意外跳过。 - 使用
BR接口:对于非常繁忙、锁竞争激烈的系统,可以考虑在抽取进程参数文件中使用BR(Bounded Recovery)接口,BR接口是GoldenGate的一个高级功能,它能更好地管理长事务和检查点,有时能间接缓解锁问题,但这需要更复杂的配置,需参考官方文档。
- 增加
-
处理数据库层面的问题:
- 解决延迟块清除:如果怀疑是延迟块清除导致,可以尝试在源数据库上对问题表执行全表扫描查询(如
SELECT COUNT(*) FROM 表名),这会触发块清除,但这只是临时措施,治标不治本。 - 优化源数据库性能:根本之道是优化源数据库的应用SQL和业务逻辑,减少长事务和锁竞争,让大批量更新操作分批提交,避免在业务高峰时段运行等。
- 解决延迟块清除:如果怀疑是延迟块清除导致,可以尝试在源数据库上对问题表执行全表扫描查询(如
-
重启GoldenGate进程:
- 在修改了参数或确认源数据库锁已被释放后,可以尝试重启报错的GoldenGate进程,先使用
STOP <进程名>停止进程,再使用START <进程名>启动,重启后,立即使用VIEW REPORT <进程名>观察进程是否能够顺利通过之前报错的位置。
- 在修改了参数或确认源数据库锁已被释放后,可以尝试重启报错的GoldenGate进程,先使用
第四步:监控与预防
- 问题解决后,需要持续监控GoldenGate进程的状态和延迟(
INFO <进程名>查看Lag指标),确保运行平稳。 - 如果参数调整有效,需要将修改永久化,即更新到该进程的参数文件(.prm文件)中,以免GoldenGate管理器重启后配置丢失。
- 建立对源数据库长事务和锁竞争的常态化监控机制,防患于未然。
重要提示:以上操作,尤其是修改数据库参数或GoldenGate核心参数,都存在一定风险,在正式环境进行操作前,务必在测试环境进行验证,并做好全面的备份,如果问题复杂或自身经验不足,强烈建议联系Oracle官方技术支持,他们可以通过分析日志文件提供更精确的解决方案。

本文由瞿欣合于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/81194.html
相关文章
-
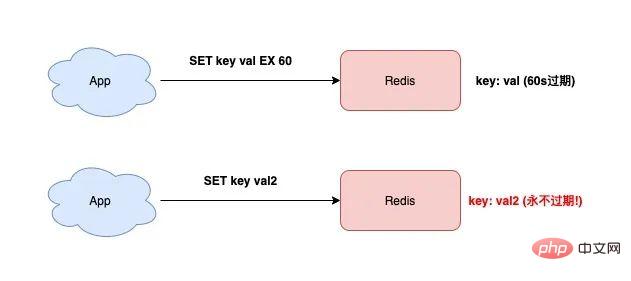
分布式Redis面试那些坑和难题,怎么突破才不慌乱讲解指南
-

深入聊聊Redis混合持久化那些事儿,感觉挺复杂但又特别关键
-

区块链本来去中心化,现在会不会慢慢变得像传统系统那样集中?
-
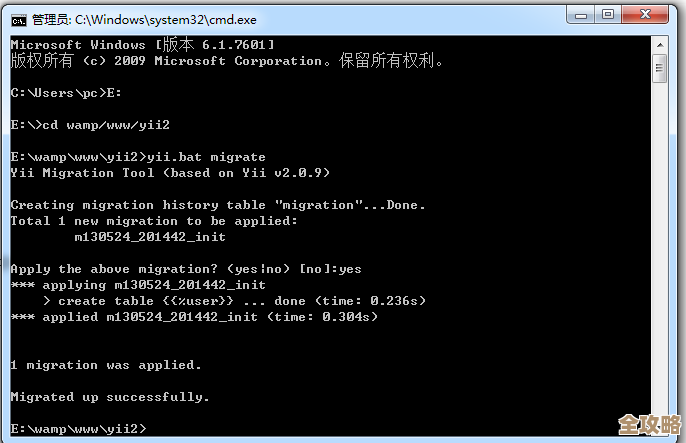
yii2切换数据库其实没那么难,一键搞定多库操作也能轻松实现
-
重要提醒数据库SP1安全更新和密钥用法你得知道的那些事儿
-
SQLServer报错5231,死锁导致对象NAME锁定失败跳过处理问题分析与应对
-
Capistrano曾是部署利器,但随着Docker和Kubernetes的兴起,自动化和容器化带来的灵活性让它逐渐被边缘化了,这就是为什么现在大家更青睐新技术而不是老方法
-
中国公有云市场最新数据出炉,腾讯云表现依旧稳健紧随第一名之后



