Redis运维那些事儿,怎么搭个靠谱框架顺利管理才不崩盘

主要综合自多位一线运维工程师的实践经验分享,以及《Redis开发与运维》等书籍中的运维理念)
Redis这东西,现在基本上是个互联网公司都在用,速度是快,但真要让它老老实实、安安稳稳地干活,不给你关键时刻掉链子,那可不是简单启动个服务就完事儿了,你得有个周全的框架管着它,就跟养孩子似的,不能光给饭吃,还得关心它健康、教它规矩、防着它学坏,下面就来聊聊怎么搭这个“靠谱”的框架。
第一件事:先把“家底”摸清楚,做好规划。

你不能等到服务器快撑爆了才手忙脚乱,一开始就要想好:
- 这台Redis主要干啥用? 是当缓存,还是当数据库?如果是缓存,数据丢了可能还能从数据库再捞回来,配置策略就可以大胆一点;如果是当数据库用,存了关键数据,那可靠性就是第一位,容不得半点闪失,这个定位决定了你后面所有运维策略的基调。
- 它大概要承担多大的量? 你得预估一下未来一段时间的数据量有多大,每秒的读写请求有多少(QPS),这决定了你需要多大的内存、多强的CPU,别拍脑袋决定,最好根据业务历史数据做个估算,并留出足够的富余量,比如预留30%以上的 buffer,不然业务量一上来,内存瞬间告警,你就得半夜爬起来扩容了。
第二件事:高可用是“保命符”,不能省。
单点的Redis服务器就是颗定时炸弹,机器硬件坏了、网络断了、甚至只是重启一下,服务就全停了,必须搞高可用,最常用的方案就是主从复制加哨兵(Sentinel)模式。

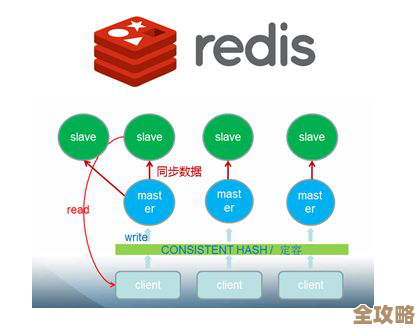
- 主从复制:弄一个主节点(Master)负责写,然后挂几个从节点(Slave)实时同步主节点的数据,这样读请求可以分散到从节点上,减轻主节点压力,这叫读写分离。
- 哨兵模式:光有主从还不够,万一主节点宕机了,得有人能自动发现这个情况,并且从从节点里选出一个新的主节点,让业务能无缝切换过去,哨兵就是干这个“监控和自动故障转移”的活儿,哨兵自己也得部署至少三个节点,防止它自己成为单点。 这套组合拳打下来,就算一台机器挂了,业务也能在很短时间内自动恢复,这才是“不崩盘”的基石,很多云服务商提供的“主从版”或“集群版”Redis,底层也是类似的原理。
第三件事:日常“体检”和“监控”不能停。
你不能等用户投诉说页面卡了,才发现Redis出问题了,必须建立完善的监控体系,就像给Redis装上7x24小时的心电图。
- 关键指标要盯紧:内存使用率(绝对不能让它跑到100%)、连接数(太多连接会拖垮服务)、CPU使用率、网络流量、以及每秒操作命令数,这些指标都要设置合理的报警阈值,比如内存使用超过80%就发短信提醒你。
- 慢查询日志要定期看:Redis会记录执行时间比较长的命令,你得像看病例一样定期检查这些慢查询,是不是有哪个业务代码写了条超级复杂的查询,或者一次获取了几十万个key?这种操作就是性能杀手,发现一个就得优化一个。
- 定期做“健康检查”:可以用
redis-cli自带的--bigkeys命令找找有没有特别大的key,大key会影响网络传输和数据处理效率,也可以用info命令全面查看Redis的内部状态。
第四件事:制定好“规矩”,防止乱来。

没有规矩不成方圆,Redis也得有使用规范,不然开发同学随手一写就可能埋个坑。
- Key的命名要有规范:比如用冒号分隔,
业务:模块:ID这样,清晰明了,也方便后期管理。 - 禁止使用危险命令:比如
KEYS *,在生产环境用这个命令查询所有key,如果数据量巨大,Redis会直接卡住,跟假死一样,应该用SCAN命令来替代,最好直接在Redis配置里把这些危险命令给禁掉(rename-command)。 - 设置合理的内存淘汰策略:如果Redis是当缓存用,内存满了之后,得告诉它怎么淘汰旧数据,常用的
allkeys-lru策略就挺好,淘汰最近最少使用的key,千万别设成noeviction(不淘汰),那样写请求会直接报错。
第五件事:备份和演练,留好“后悔药”。
就算有高可用,也怕一些极端情况,比如程序员误删了核心数据,而且这个删除命令还同步到了所有从节点,这时候就需要备份来恢复了。
- 定期做持久化备份:RDB快照和AOF日志都要配置好,RDB像是拍一张数据全景照,恢复快;AOF像是记录所有操作日记,数据更完整,可以两者结合使用,备份文件不能放在Redis服务器本地,得传到别的安全地方(比如对象存储)。
- 定期演练恢复流程:光备份不行,你得真的找个测试环境,定期用备份文件恢复一下数据,确保这招在真需要的时候管用,不然等出了事,可能发现备份文件是坏的,或者恢复步骤都忘了,那才叫绝望。
管理Redis不是一锤子买卖,而是一个持续的、系统性的工程,从规划、搭建、监控、规范到容灾,每个环节都得考虑到,形成一个闭环,才能让这个性能猛兽乖乖听话,为业务保驾护航,而不是动不动就“崩盘”给你看。
本文由雪和泽于2026-01-13发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79750.html