ORA-31101报错锁资源失败问题分析及远程快速修复方法分享

ORA-31101报错是Oracle数据库管理中一个比较棘手的问题,它直接翻译过来的意思是“无法分配内存,可能是由于锁资源不够”,这个错误通常发生在数据库系统尝试为新的会话或操作分配必要的锁资源时,但系统的锁资源池(主要是共享池的一部分)已经耗尽,导致分配失败,用户在执行某些操作,比如执行一个复杂的SQL语句、创建索引或者进行大规模数据导入时,可能会突然遇到这个错误,导致操作中断。
问题发生的根本原因分析
根据Oracle官方文档和大量DBA(数据库管理员)的实践经验,ORA-31101错误的根源可以归结为以下几个方面:
-
共享池(Shared Pool)内存不足:这是最核心的原因,Oracle使用共享池来缓存SQL语句、PL/SQL代码、数据字典信息以及各种控制结构,其中就包括“锁”(Enqueue)资源,当共享池的可用空间被大量占用,存在大量未共享的SQL语句(即所谓的“硬解析”过多)、存在内存泄漏、或者缓存了过大的PL/SQL包时,留给锁资源的内存自然就不够了。
-
会话数或活跃事务数激增:当数据库同时存在大量并发会话,并且这些会话都在执行需要获取锁的操作(如DML语句:INSERT, UPDATE, DELETE)时,系统需要同时维护的锁数量会急剧上升,如果这个数量超过了共享池中为锁资源预留的空间上限,就会触发ORA-31101错误,这种情况在高并发应用系统或者有批量作业运行时尤其常见。
-
存在长时间未提交的事务:这是一个非常关键的因素,如果一个事务开启了很久但一直没有提交(COMMIT)或回滚(ROLLBACK),那么它所占用的所有锁资源(包括行锁、表锁等)会一直被持有,无法释放,后续需要访问相同数据资源的事务就会进入等待队列,并可能因为新的锁资源无法分配而报错,这就像停车场被几辆“僵尸车”长期霸占,导致其他车无法停放。
-
数据库参数设置不合理:与锁资源相关的初始化参数,特别是
ENQUEUE_RESOURCES,虽然在较新版本的Oracle中其管理已经自动化,但在某些特定版本或配置下,如果设置得过低,也可能成为瓶颈,在现代Oracle版本中,更常见的问题还是出在共享池的整体大小(SHARED_POOL_SIZE)上。
远程快速修复方法分享
当用户远程报告ORA-31101错误时,DBA需要快速响应,目标是迅速释放被占用的锁资源,恢复系统正常操作,以下是一套行之有效的排查和修复步骤:
第一步:紧急情况下的快速缓解
立即检查当前数据库中是否存在阻塞链或长时间运行的事务,可以通过查询动态性能视图来实现。

-
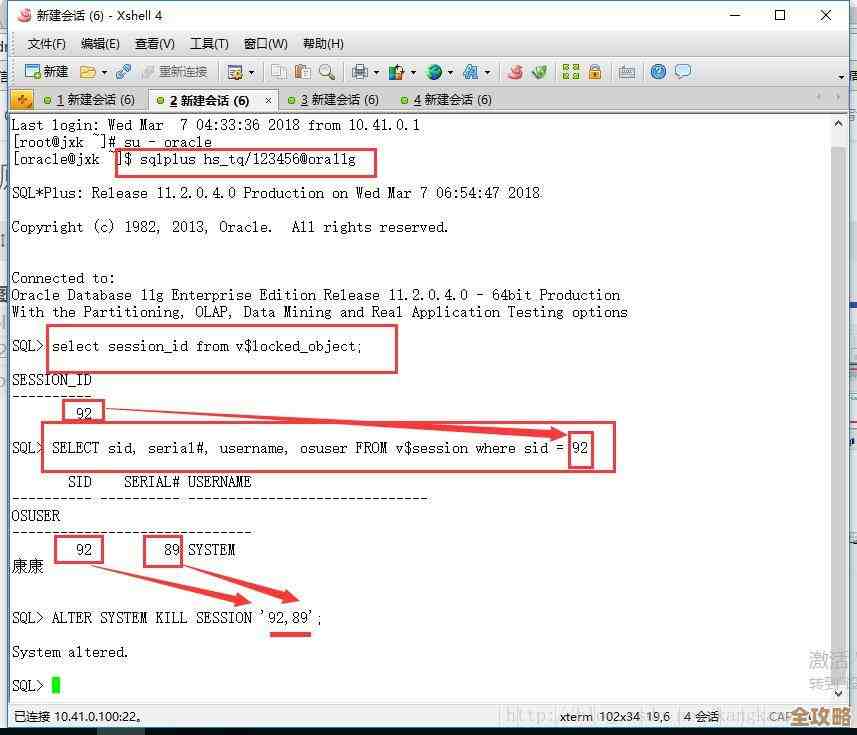
查找长时间未提交的事务:
SELECT s.sid, s.serial#, s.username, s.program, s.machine, t.start_time FROM v$session s, v$transaction t WHERE s.saddr = t.ses_addr ORDER BY t.start_time;
这个查询会列出所有当前活跃的事务,按开始时间排序,重点关注那些
START_TIME非常早(比如几小时甚至几天前)的会话,这些就是潜在的“罪魁祸首”。 -
识别具体的锁等待和阻塞关系:
SELECT l1.sid AS blocking_sid, s1.username AS blocking_user, s1.program AS blocking_program, l2.sid AS waiting_sid, s2.username AS waiting_user, s2.program AS waiting_program, l1.type AS lock_type FROM v$lock l1, v$lock l2, v$session s1, v$session s2 WHERE l1.id1 = l2.id1 AND l1.id2 = l2.id2 AND l1.request = 0 AND l2.lmode = 0 AND l1.sid = s1.sid AND l2.sid = s2.sid;这个查询能清晰地显示出谁(blocking_sid)阻塞了谁(waiting_sid)。
第二步:采取行动释放资源
在确认了问题源头后,最直接的解决方法是终止阻塞其他会话的异常会话。

- 强制终止会话:
使用上面查询到的
SID和SERIAL#值,执行以下命令:ALTER SYSTEM KILL SESSION 'sid,serial#';
如果
SID是123,SERIAL#是45678,则命令为:ALTER SYSTEM KILL SESSION '123,45678';。 执行后,该会话会被标记为终止状态,其占用的锁资源会在进程被数据库清理后释放,有时可能需要额外在操作系统层面杀掉对应的服务器进程。
第三步:根本性解决与预防
快速解决后,必须进行深入分析,防止问题复发。
-
检查并优化共享池:查看共享池的使用情况。
SELECT * FROM v$sgastat WHERE pool = 'shared pool';
关注
free memory是否持续处于很低的水位,如果共享池确实太小,可以考虑适当增大SHARED_POOL_SIZE参数,但更重要的是优化应用,减少硬解析。 -
应用层面优化:
- 鼓励及时提交事务:督促开发人员确保应用程序中的事务要短小精悍,操作完成后立即提交,避免长时间持有锁。
- 使用绑定变量:检查应用是否使用了绑定变量,这可以极大减少硬解析,从而降低共享池的消耗,可以通过查询
v$sql视图查看相似SQL的数量来判断。 - 优化SQL和索引:低效的SQL和缺失的索引可能导致全表扫描,会增加锁的持有范围和时长。
-
监控与预警:建立对数据库锁数量、活跃事务数、共享池空闲内存的监控告警,一旦指标出现异常趋势,就能在问题爆发前介入处理。
处理ORA-31101错误,远程快速修复的核心是“找准并干掉坏掉的事务”,而长治久安的策略则是“优化应用和数据库配置,确保锁资源不会被过度或长期占用”。
本文由颜泰平于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/79126.html