表单数据库查询那些事儿,怎么才能又快又准地找到想要的数据呢?

根据常见的数据库查询优化经验、软件开发社区如Stack Overflow的常见问题解答、以及《SQL必知必会》等入门书籍中的基础概念综合整理)
表单数据库查询那些事儿,怎么才能又快又准地找到想要的数据呢?
咱们平时用各种软件,比如电商网站查订单、公司系统里找客户信息,背后基本都是数据库在干活,你点一下“搜索”,其实就是向数据库发了一条查询指令,有时候感觉卡顿,半天不出结果,或者查出来的数据不对,多半是查询这条“路”没走好,今天就来聊聊,怎么能让这条路又快又准。
第一,想查得准,先得说清楚——编写精准的查询条件

这就像你去图书馆找书,如果你只跟管理员说“我想找一本好看的小说”,那管理员可能会给你抱来一大堆,你得花时间慢慢挑,但如果你说“我想找一本余华写的、关于福贵的小说”,管理员就能直接指向《活着》这本书。
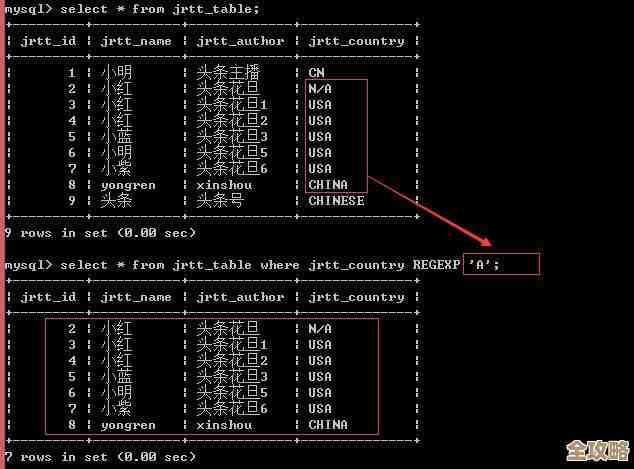
数据库查询也是一个道理,很多人查不准,是因为查询条件太模糊,你想查所有姓“张”的客户,如果你的条件是“姓名”字段“包含”‘张’,那么名字里带‘张’字的(张伟”、“李张氏”)都会被找出来,但如果你要的是“姓张”,条件就应该是“姓名”字段“以‘张’开头”,这就是“精准”的含义。
另一个常见的“不准”是忽略了数据的关联性,比如你想查某个订单的详细信息,订单表里只有客户ID,客户名字在另一张客户表里,如果你只查订单表,就只能看到一串数字ID,看不懂是谁,这时候就需要用“连接查询”,把两张表通过客户ID这个桥梁关联起来,这样结果里才能既有订单号,又有客户姓名,搞清楚数据是怎么分布的,表与表之间怎么关联,是查准数据的基础。(这部分思路参考了数据库关系模型的基本概念)

第二,想查得快,得给数据库建“高速路”和“索引”——利用索引优化
为什么有时候查得慢?想象一下,一本厚厚的电话簿,如果没有按姓氏拼音排序,你要找一个“王五”,就得从第一页开始一页一页翻,这叫“全表扫描”,速度当然慢,但现实中的电话簿都是排好序的,你直接翻到“W”开头的部分,很快就能找到,这个“排序”就相当于数据库里的“索引”。
索引是数据库里一种特殊的结构,它就像一本书的目录,如果你经常要按“客户姓名”来查,就可以给“姓名”这个字段创建一个索引,这样当你再查“姓名=‘张三’”时,数据库就不用扫描整个表了,而是直接去索引里定位,速度会快上几十倍甚至几百倍。

索引不是万能的,也不能乱建,索引本身也要占用存储空间,当你往表里增加、修改或删除数据时,数据库还需要额外的时间来更新索引,建索引的原则是:针对最常用、最关键的查询条件来建,你几乎从不按“年龄”查客户,那就没必要给年龄字段建索引,索引要建在区分度高的字段上,性别”字段,只有“男”、“女”等少数几个值,建索引的效果就不如对“身份证号”这种唯一值很多的字段建索引来得明显。(这个比喻和原则在多种数据库入门指南中均有提及)
第三,别让数据库“干重活”——避免低效操作
有些查询语句写得不好,会让数据库做很多不必要的“重活”,自然就慢了。
- *别用`SELECT SELECT
的意思是“把所有字段的数据都给我”,但很多时候,你可能只需要客户的姓名和电话,如果表里有几十个字段,还包括很长的备注文本,SELECT会让数据库搬运大量你不需要的数据,浪费网络带宽和计算资源,正确的做法是**需要什么字段,就写什么字段**,比如SELECT 姓名, 电话`。 - 少用模糊查询开头带通配符:比如查询条件写成
LIKE ‘%张三’,这表示要查找以“张三”结尾的姓名,由于索引通常是从头开始匹配的,这种写法会让索引失效,数据库又得去做全表扫描,如果可能,尽量用LIKE ‘张三%’(查找以“张三”开头的),这样索引还能帮上忙。 - 注意关联查询和子查询:当需要连接多张表时,要确保连接条件上是有索引的,复杂的子查询(一个查询嵌套在另一个查询里)有时性能会很差,可以考虑能不能改成连接查询,或者看看数据库有没有更高级的优化方式。(这些是SQL性能调优中的常见注意事项)
快和准的背后是理解
说到底,要想又快又准地查询数据,关键在于理解:理解你的业务需求(到底要什么),理解你的数据结构(数据存在哪,怎么关联),以及理解数据库的基本工作原理(它怎么“思考”和“找数据”),平时多观察查询语句的执行时间,对于特别慢的查询,可以尝试用数据库提供的工具看看它的“执行计划”,它能告诉你数据库准备怎么一步步完成你的指令,哪里是瓶颈,慢慢地,你就能找到感觉,成为查询高手了。
本文由钊智敏于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/78784.html