深入掌握Redis高可用架构,带你一起成为专业高手,玩转稳定又高效的系统设计

(根据“Redis高可用架构”相关技术文档与社区实践整理)
要真正玩转一个稳定又高效的Redis系统,光知道几个基本命令是远远不够的,你得像搭积木一样,把Redis的各种高可用组件组合起来,形成一个即使某块积木掉了,整个系统也不会垮掉的坚固城堡,今天我们就来聊聊怎么搭建这个城堡。
最基础也最常见的方案是主从复制,这个很好理解,就是找一个Redis实例当“老大”(主节点),其他几个实例当“小弟”(从节点)。“老大”负责接收所有的写操作,然后把这些操作像广播一样,同步给所有“小弟”。“小弟”们只负责读操作,这样一来,读的压力就被分散了,系统的读性能能提高不少,数据在多个节点上都有备份,安全性也高了,这个模式有个致命的弱点:万一“老大”宕机了,整个系统就瘫痪了,因为没人能接收写命令了,光有主从复制还不够高可用。

为了解决主节点宕机的问题,我们就需要引入哨兵(Sentinel) 机制,你可以把哨兵想象成一群忠诚的卫兵,它们不存储数据,唯一的任务就是7x24小时地盯着主节点和它的从节点们看,哨兵们之间也会互相通信,它们的主要工作有三个:监控(不断检查主从节点是否还活着)、提醒(当发现主节点挂了,就通知系统管理员或其他程序)、自动故障转移(这是最关键的功能,当主节点被确认为真的挂了,哨兵们会集体投票,从剩下的从节点中选出一个新的“老大”,然后让其他“小弟”都去跟随这个新老大,并把客户端的请求也引导到新主节点上)。
有了主从复制+哨兵,我们的Redis系统已经相当健壮了,即使主节点突然宕机,也能在几十秒内自动恢复服务,业务几乎感知不到,这个架构还是有两个潜在问题:一是所有的写操作还是集中在一个主节点上,如果写请求量巨大,单个主节点可能会成为瓶颈;二是每个节点都保存了全量数据,如果数据量特别大,比如几百个GB,那么单个机器的内存可能放不下,而且数据恢复起来也很慢。

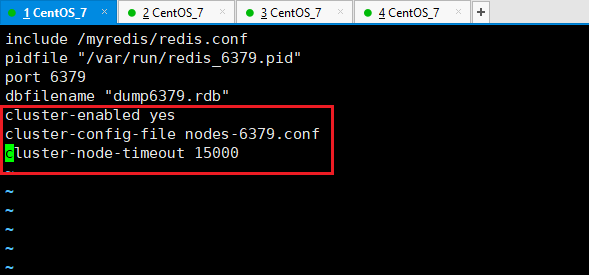
这时候,我们就需要祭出终极武器——Redis Cluster(Redis集群),集群模式是Redis官方提供的真正的分布式解决方案,它核心的思想是 “分片” ,想象一下,你有一个超大的书架(全量数据),一个人搬不动,现在你找了六个人(六个Redis节点),把书架上的书分成16384份(这叫做哈希槽),然后平均分给这六个人保管,当你需要存一个数据时,集群会计算这个数据属于哪个“槽”,然后把它存到负责这个槽的节点上,同样,取数据的时候也是先找槽,再找对应的节点。
Redis集群天然就具备了高可用能力,它把节点分成主节点和从节点,每个主节点都有一到多个从节点做备份,数据会自动在不同的分片(主节点)间分布,当某个主节点宕机时,它对应的从节点会自动升级为主节点,继续提供服务,这样一来,它既解决了单节点写性能瓶颈的问题(因为写请求被分摊到多个主节点上了),又解决了单机内存容量限制的问题(因为数据被分片存储了),还内置了高可用机制,可谓一举多得。
集群模式也不是银弹,它更复杂,客户端需要支持集群协议,一些跨多个key的操作可能会受到限制(因为这几个key可能分布在不同的节点上),选择哪种架构,要根据你实际的业务场景来定:如果数据量不大,读写压力也一般,主从+哨兵可能就足够了;如果面临海量数据和高并发,那么就必须考虑集群模式了。
无论用哪种架构,一些良好的实践都是共通的:比如给Redis设置合理的最大内存限制和淘汰策略,防止内存爆满;做好持久化配置(RDB快照和AOF日志),保证数据安全;对系统进行持续的监控和报警,做到问题早发现、早处理,真正玩转Redis高可用,就是在理解这些核心原理的基础上,根据实际情况灵活运用和不断调优的过程。
本文由盈壮于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77379.html