Redis集群防雪崩那些事儿,咋整才不掉链子又稳得住

开始)
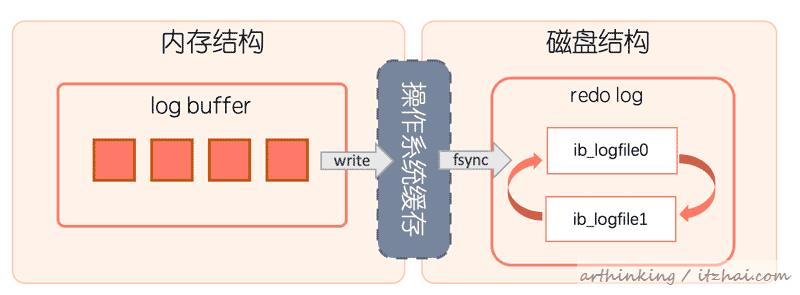
咱们今天就来唠唠Redis集群防雪崩这个事儿,你想想,Redis就像是你系统里的一个超级快的临时大仓库,所有热乎乎的数据都先放这儿,应用要用的时候直接来取,速度快得很,但万一这个仓库出了点岔子,比如扛不住压力瘫了,或者网络抽风了,后面那些等数据的应用可就全堵在门口了,一下子全涌到后面那个更慢的数据库老家去,数据库哪见过这阵仗啊,分分钟也得被压垮,整个系统就跟多米诺骨牌一样,哗啦啦全躺下,这就是雪崩,可不是闹着玩的,咱们得提前整几道防线,让它既不掉链子,又稳得住。
第一招,别让缓存同时过期,给过期时间加个随机数。 这是最基础也是最关键的一步,你想啊,如果一大批缓存在同一个时间点“啪”一下全都失效了,那所有相关的请求就会在同一时刻都找不到数据,然后齐刷刷地去数据库查,这可不就是给数据库来个突然袭击嘛,那咋整呢?很简单,在设置缓存过期时间的时候,别都用一样的数值,本来默认过期时间是1小时,那你就可以在这个基础上,加个几分钟的随机值,比如实际过期时间变成1小时加上一个0到10分钟的随机数,这样一搞,这批缓存的失效时间就自然错开了,避免了在某个时间点集体失效带来的洪峰压力,这就好比安排员工休息,别都挤在中午12点一起去吃饭, stagger一下,食堂才不会挤爆。
第二招,搞个互斥锁,防止一堆请求同时去查数据库。 有时候哪怕过期时间错开了,也可能出现这种情况:某个热点key刚好失效了,这时候突然来了成千上万个请求要这个key的数据,第一个请求发现缓存没了,它得去数据库查;但就在它去查还没回来的这个空档,后面的请求也发现缓存是空的,它们可能也以为要自己去查数据库,这一下子就可能冒出好多条查询数据库的请求,对付这种情况,可以用个“锁”的机制,当第一个请求发现缓存失效后,它不去立刻查数据库,而是先在Redis里设置一个特殊的、有很短过期时间的锁标记(比如SETNX命令可以实现),设置成功了,说明它是第一个,那它就去安心查数据库,然后把结果塞回缓存,在这期间,其他请求过来,发现缓存没有,但那个锁标记存在,就知道已经有兄弟去查了,它们就乖乖地等一小会儿(比如休眠几十毫秒),然后重新去缓存里读取数据,这时候大概率第一个请求已经把数据写回来了,这样就保证了对于同一个key,只有一个请求会去查数据库,避免了数据库被重复查询压垮,这就像只有一个代表去仓库拿东西,其他人等着就行,别一窝蜂全挤进去。
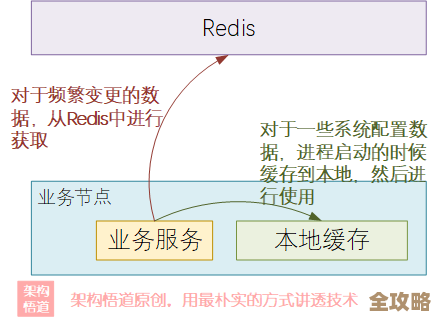
第三招,给缓存做个预热,提前把数据塞进去。 对于那些我们能预料到会突然变热的数据,比如大促活动刚开始时的热门商品信息,或者重大新闻发布后的内容,最好在访问洪峰到来之前,就提前把这些数据加载到Redis缓存里,并且设置好合理的过期时间,这样等用户请求真的涌进来的时候,数据已经在缓存里备好了,直接就能返回,数据库那边就轻松多了,这就好比你知道明天要开大会,今天下午就把会议室布置好,茶水准备好,别等明天人都来了才手忙脚乱。
第四招,做好持久层兜底,给数据库也加层保护。 咱们得承认,再好的防护也可能有意外,万一Redis集群真的完全宕机了,或者网络分区了,所有请求还是会落到数据库上,这时候,数据库自己也得有点抗压能力,可以考虑给数据库的查询也加上限流措施,用Hystrix、Sentinel这类工具,对访问数据库的请求进行流量控制,设置一个阈值,超过这个阈值的请求就直接快速返回一个友好的错误提示(系统繁忙,请稍后再试”),而不是让它们无限制地压向数据库,这样才能保住数据库不崩,给修复Redis争取时间,这叫弃车保帅,虽然部分用户体验暂时受影响,但保证了系统整体不瘫痪。
第五招,保证Redis集群自身的高可用。 打铁还需自身硬,最好的防雪崩就是不让雪崩发生,所以Redis集群的架构要健壮,现在主流的方式是采用Redis Cluster或者基于哨兵(Sentinel)的主从复制模式,简单说,就是数据有多个副本,分布在不同的机器上,万一主节点挂了,哨兵或者集群自己能很快地检测到,并自动把一个从节点提升为新的主节点,继续提供服务,这样单台机器的故障就不会导致整个缓存服务不可用,要做好监控,实时关注Redis的内存使用率、CPU负载、网络流量、慢查询等关键指标,发现异常能及时处理。
第六招,考虑给缓存设置不同的失效等级,甚至永不过期。 对于一些极其关键、访问频率又非常高的基础数据,可以考虑让它们永不过期,或者设置一个非常长的过期时间(比如一天),然后通过程序逻辑,在数据有更新的时候,主动去刷新缓存,对于不那么关键的数据,可以设置较短的过期时间,这样分级管理,能把风险进一步分散。
还有个事后诸葛亮的招,叫降级策略。 就是在系统压力巨大,感觉快要顶不住的时候,主动关闭一些非核心的、耗资源的缓存功能,暂时关闭一些复杂的、需要实时计算的排行榜数据的缓存更新,转而返回一个稍微旧一点的版本,或者直接返回一个默认值,优先保证核心的交易链路能通,这相当于在洪水太大的时候,主动开个分洪区,保住主城区。
防雪崩不是靠一招鲜,而是要靠一套组合拳,从缓存的设置策略(过期时间、互斥锁),到事前准备(预热),再到集群架构(高可用),最后到下游保护(数据库限流)和应急方案(降级),层层设防,才能让你的系统在关键时刻不掉链子,稳如泰山。 结束)

本文由称怜于2026-01-08发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/77014.html