大型数据库软件的基本介绍和实际应用探讨与分享

当我们谈论“大型数据库软件”时,我们指的并不是一个存放文件的简单柜子,而更像是一个庞大、高效、且极其智能的数字化仓库管理中心,它的核心任务是安全、快速、准确地处理海量数据,并支持成千上万的用户同时进行复杂的操作,想象一下,像淘宝在“双十一”期间要处理数亿人的浏览、下单和支付;或者像银行系统,需要每分每秒处理全球数百万笔转账交易,确保每一分钱都准确无误,这些场景的背后,都离不开大型数据库软件的强力支撑。
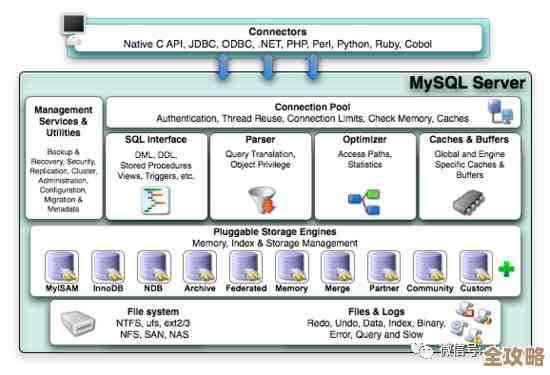
这些软件之所以能胜任如此艰巨的任务,主要依赖于几个关键的设计思想,首先是“关系型”结构,这是最经典和主流的一种,它把数据组织成一张张规整的表格,比如一张表存用户信息(姓名、ID),另一张表存订单信息(订单号、商品、用户ID),表格之间通过像“用户ID”这样的关键信息关联起来,这样既能避免数据重复存储,又能灵活地组合查询,市面上知名的Oracle Database、MySQL、Microsoft SQL Server以及PostgreSQL等,都属于关系型数据库的代表,它们使用一种叫做SQL的标准化语言进行操作,用户可以用接近自然语言的指令,SELECT * FROM 用户表 WHERE 年龄 > 20”,来精确地获取所需数据,根据权威科技出版社O'Reilly在《数据库系统概念》中的阐述,这种关系模型因其坚实的数学理论基础和数据一致性保证,在过去几十年里成为了企业级应用的基石。
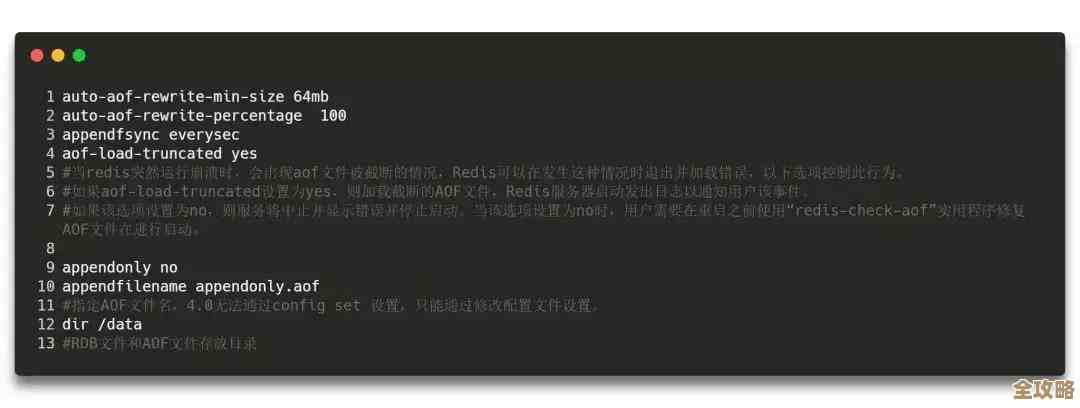
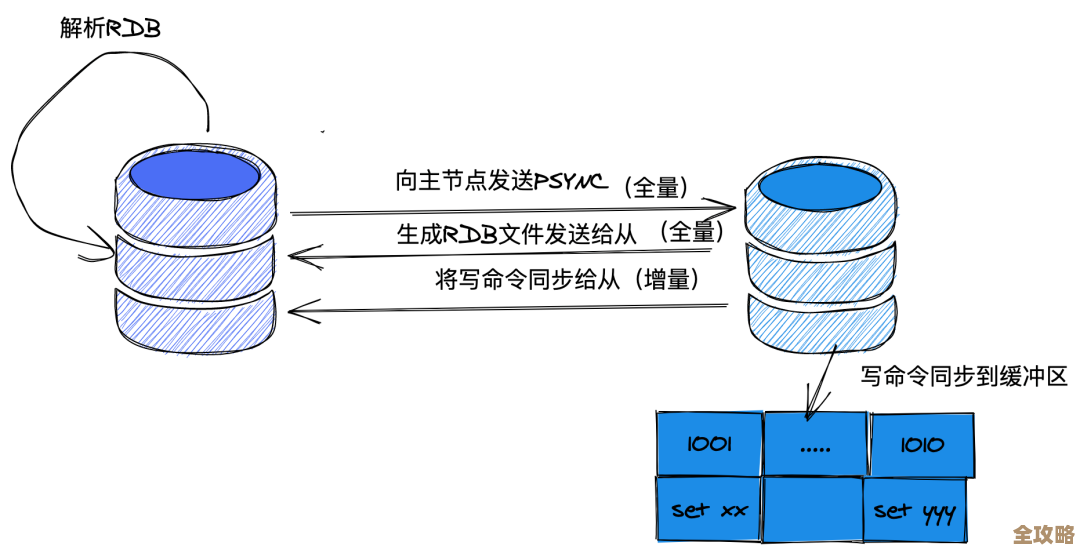
随着互联网的爆发式发展,尤其是社交媒体、物联网和移动应用的兴起,数据的形态和规模发生了巨大变化,数据不再仅仅是规整的表格,它可能是社交网络上用户发布的动态、视频评论,也可能是传感器发回的实时流水记录,这些数据往往数量极其庞大,而且结构灵活多变,这时,另一大类数据库——“非关系型数据库”(NoSQL)应运而生,它们为了应对海量数据和高并发访问,有时会在数据一致性上做出一些妥协,转而追求更高的可扩展性和可用性,MongoDB使用类似JSON的文档格式来存储数据,非常灵活;Redis将数据存放在内存中,速度极快,常用于缓存;Cassandra则擅长在大量服务器之间分布式地存储数据,根据MongoDB大学官方培训材料的观点,非关系型数据库的优势在于能够更好地适应现代应用对可扩展性和敏捷开发的需求。
在实际应用中,企业通常会根据具体的业务场景来选择甚至组合使用不同类型的数据库,这被称为“多模数据库”或“混合架构”,一个常见的例子是,一个电商平台的核心交易系统(如扣款、库存更新)可能仍然使用Oracle或MySQL这类强一致性的关系型数据库,以确保财务数据的绝对准确,而前端的商品展示、用户评论、推荐系统等,则可能使用Elasticsearch来实现快速搜索,用Redis来缓存热点商品信息,减轻主数据库的压力,这种架构设计,在亚马逊云科技(AWS)的官方案例分享中屡见不鲜,它体现了在实际业务中权衡性能、成本与一致性需求的智慧。
除了选型,大型数据库的日常管理和维护本身就是一门大学问,数据库管理员(DBA)就像是这个数字仓库的超级管家,他们的工作远不止是备份和恢复数据那么简单,他们需要持续对数据库进行“调优”,比如建立合适的索引(就像书的目录,能让你快速找到内容),优化查询语句,合理分配存储空间和内存,并设置7x24小时的监控告警系统,确保数据库这个核心“心脏”能够平稳、高效地跳动,任何一次微小的性能下降或短暂的服务中断,都可能给企业带来巨大的经济损失和声誉风险。
大型数据库软件是现代数字世界的无声基石,从我们每次扫码支付、刷短视频,到企业的精准营销和科学决策,背后都是这些复杂系统在默默工作,理解它们的基本原理、不同类型的特点以及在实际中的灵活运用,对于任何与技术相关的从业者而言,都是一项极具价值的知识,随着人工智能和大数据分析时代的到来,数据库技术仍在不断演进,未来我们可能会看到更多能够智能优化自身、无缝融合事务处理与分析能力的下一代数据库系统。

本文由太叔访天于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/76317.html