Redis缓存性能提升那些事儿,挖掘潜力别只盯着表面问题

说到提升Redis的性能,很多人第一反应就是:加内存!换更快的硬盘!或者抱怨网络延迟,这些确实是问题,但就像医生看病,不能头疼医头、脚疼医脚,很多时候,真正的性能瓶颈藏在你没留意的日常操作里,今天咱们就抛开那些表面的硬件问题,聊聊怎么从内部挖掘Redis的潜力。
咱们得有个共识:Redis最快的情况是什么?就是它纯粹在内存里操作,像个闪电侠,任何让它“分心”的事情,都会拖慢它的速度,提升性能的核心思路就是,让Redis能心无旁骛地做它的本职工作——读写内存。
第一件容易被忽略的事儿:那些不起眼的“慢操作”。
你可能觉得SET、GET命令已经快得飞起了,但Redis里可不是所有命令都这么快,获取一个超大的Hash结构的所有键值对(HGETALL),或者对一个包含百万成员的集合(SMEMBERS)进行操作,这种命令会一次性返回大量数据,不仅耗时长,还可能瞬间占满你的网络带宽,导致其他正常请求被阻塞,这就像在一条单行道上,突然来了一辆超长的货车,后面的车全都得等着。
那怎么办呢?根据“阿里云开发者社区”的一篇文章建议,对付这种“大Key”,要分而治之,用HSCAN代替HGETALL,分批少量地获取数据,虽然请求次数多了,但每次都很轻快,不会阻塞交通,或者,从设计上就避免产生这种大Key,比如把用户信息按日期拆分到不同的Key里。
第二件比慢操作更隐蔽的事儿:持久化带来的“暗耗”。
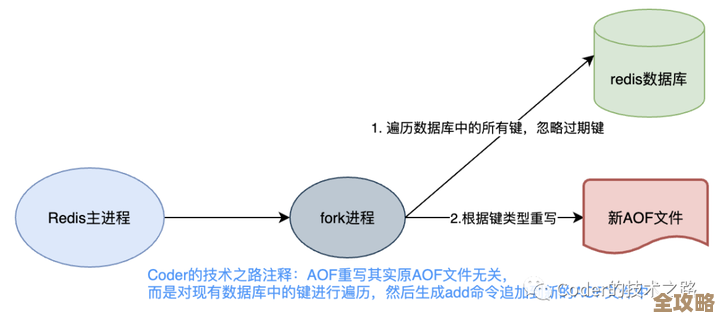
Redis为了数据不丢失,提供了RDB快照和AOF日志两种持久化方式,但这俩都是“后台任务”,RDB是隔一段时间fork一个子进程去生成快照,AOF是不断把写命令记到日志里,问题就出在fork上。

根据“腾讯云数据库”的技术解析,当你的Redis内存占用很大时(比如20GB),fork子进程的那一刻,虽然子进程共享父进程的内存数据,但一旦父进程有新的数据写入,操作系统就需要为子进程复制一份将要修改的内存页(写时复制机制),这个复制过程会消耗大量的CPU资源,并且如果你的机器内存紧张,还可能触发Swap,把内存数据换到硬盘上,那性能可就断崖式下跌了,你感觉Redis突然变卡了,一查CPU和内存都还好,罪魁祸首可能就是后台正在做RDB持久化。
解决方案是,根据业务对数据丢失的容忍度,合理配置持久化策略,可以适当延长RDB的快照间隔,或者使用混合持久化(AOF+RDB),减少fork的频率,确保服务器有足够的内存,绝对要避免使用Swap。
第三件看似无关实则致命的事儿:客户端的“笨”用法。
很多时候,性能瓶颈不在Redis服务器本身,而在你的应用程序里,最常见的就是“循环请求”,你要获取100个用户的姓名,如果你的代码是写一个for循环,执行100次HGET命令,那么网络往返的延迟就会累积100次,这在Redis的官方文档中被明确列为应避免的反模式。

正确的做法是使用“流水线(pipeline)”或者“批量操作”,还拿这个例子说,你应该用HMGET命令,一次就把100个用户的姓名都取回来,流水线技术则是把多个命令打包,一次发送给Redis,再一次性读取所有回复,极大地减少了网络往返次数,这就像搬东西,你一件一件地从仓库往外拿,效率肯定不如用一个小推车一次拉一车。
第四件关乎稳定性的长远事儿:内存碎片的“无声”侵蚀。
Redis用了自己的一套内存分配器,删除Key后释放的内存不一定能立刻被新写入的数据完美利用,久而久之就会产生内存碎片,内存碎片率高,意味着你明明看着还有几个GB的空闲内存,但Redis却可能因为找不到一块足够大的连续空间来存放新数据,而不得不先进行内存整理,或者甚至报错,这就像你的硬盘,文件删删写写多了,也会产生碎片,影响读写速度。
定期检查info memory命令输出中的mem_fragmentation_ratio(内存碎片率)指标很重要,如果这个值长时间过高(比如持续超过1.5),可以考虑重启Redis实例(在允许的情况下),或者使用Redis 4.0以上版本支持的MEMORY PURGE命令(针对Jemalloc分配器)来主动清理碎片。
提升Redis性能,不能只当个“甩手掌柜”,把问题推给硬件,更要像一个细心的管家,从Key的设计、持久化的配置、客户端的代码优化,再到内存的健康状况,进行全方位的审视和调优,把这些内在的潜力挖掘出来,往往能花小钱办大事,让你的Redis真正健步如飞。
本文由颜泰平于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75986.html