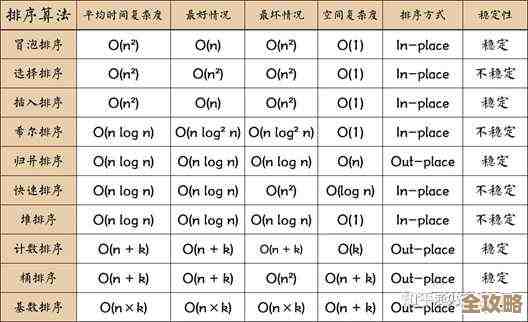
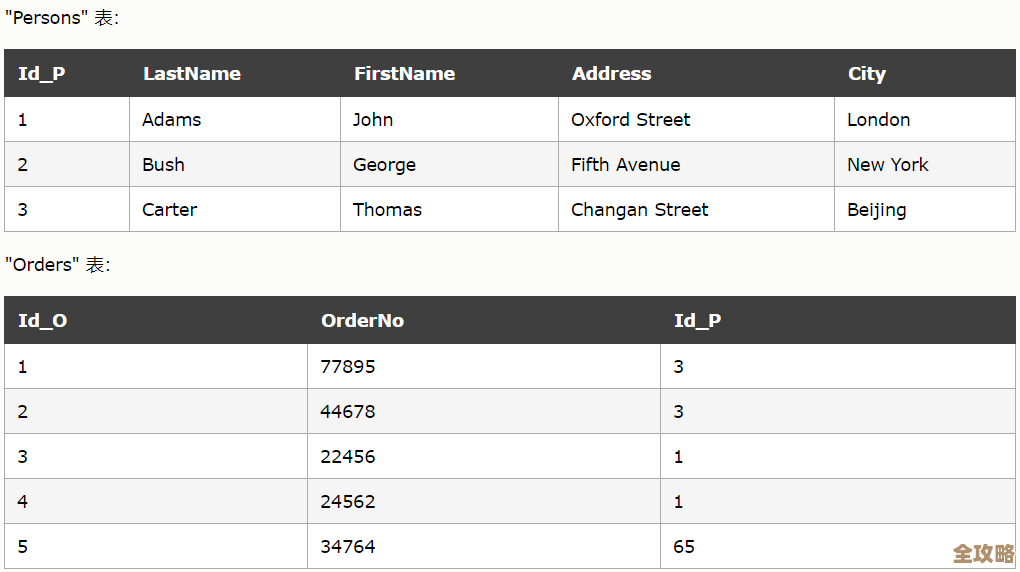
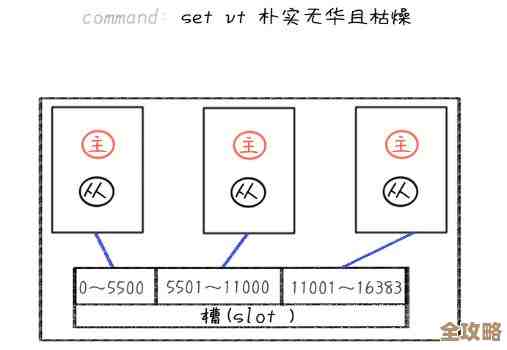
中国最大数据库到底有多大,存储量惊人还是还有更大的存在?

中国最大数据库到底有多大”这个问题,答案并不是唯一的,因为它取决于我们从哪个角度去定义“数据库”,如果我们将“数据库”理解为单一机构为特定目的(尤其是公共服务)所建设和维护的超大规模数据存储和处理系统,那么国家层面的基础设施无疑是体量最庞大的,但如果我们将视角放宽,将互联网巨头们为商业运营而构建的分布式数据集群也视为一个整体,那么其规模可能同样惊人,甚至在某些维度上更为复杂。

从国家战略资源的角度看,最具代表性的当属国家人口基础信息库,根据新华社等官方媒体的报道,这个数据库是全球覆盖人口数量最多的国家级人口数据库,它汇聚了来自公安部、人力资源和社会保障部、民政部、教育部、卫生健康委等数十个部委的公民基本信息,涵盖了超过14亿中国公民的身份、户籍、教育、职业、婚姻、健康等核心数据,其数据项之繁多、覆盖范围之广,是其他任何商业数据库难以比拟的,虽然具体的存储容量(例如以PB或EB为单位)属于敏感信息,并未公开,但可以想象,仅凭其服务对象的绝对数量,其数据体量就足以用“海量”来形容,它的“大”不仅体现在存储量上,更体现在其数据的权威性、全面性和作为国家治理现代化基石的战略价值上。
如果我们谈论的是日常应用中数据处理吞吐量和存储量巨大的系统,那么中国的互联网科技公司无疑是主角,根据腾讯官方在过往技术分享会上的介绍,其旗下的微信产品每天需要处理的海量信息就达到了惊人的级别,这些数据包括数以百亿计的文字消息、图片、短视频以及数十亿分钟的语音通话,支撑这些业务的后台数据库系统,必然是由成千上万台服务器组成的庞大集群,其总存储容量无疑是一个天文数字。

同样,阿里巴巴集团作为电商和云计算领域的巨头,其数据处理规模同样骇人听闻,根据阿里巴巴集团前董事局主席张勇在过往财报电话会议中的描述,仅“双十一”购物狂欢节这一天的实时交易创建峰值,就达到了每秒数十万笔的级别,这背后是支付宝和淘宝天猫后台数据库系统承受的极限压力,它们需要同时处理交易、库存、物流、支付等无数个环节产生的结构化数据,这种在极短时间内爆发的数据洪流,对数据库的写入能力和一致性要求是极端苛刻的,阿里巴巴自主研发的OceanBase分布式数据库,其设计目标就是为了应对这种世界级的挑战。
作为中国领先的搜索引擎公司,百度需要实时抓取、索引和存储整个中文互联网的海量网页内容,根据百度在技术开放日活动中披露的信息,其搜索引擎索引的网页数量早已超过万亿级别,这包含了难以估量的文本、图片、视频等多种格式的数据,百度的数据库系统需要不断地更新这些索引,以便为用户提供最新、最相关的搜索结果,其数据存储和处理的规模同样是“巨大”一词的直观体现。
是否存在比这些已知数据库更大的呢?答案是肯定的,并且可能以两种形式存在。
一种是“聚合的隐形巨人”,上述提到的互联网公司的数据库,虽然每个都已经非常庞大,但它们通常是按业务线划分的多个独立集群,而从整个公司集团的角度看,如果将阿里旗下淘宝、蚂蚁、阿里云等所有业务的数据存储汇总,或者将腾讯旗下社交、游戏、金融科技等所有数据汇总,其总体量将是一个更加难以想象的数字,这个“隐形的总和”很可能超过了任何单一的国家级公共数据库在纯存储容量上的规模。
另一种是面向未来的“下一代数据黑洞”,随着物联网、5G/6G通信、自动驾驶和人工智能技术的爆炸式发展,我们正步入一个数据产生速度呈指数级增长的时代,遍布城市的智能摄像头、工业生产线上的传感器、自动驾驶汽车采集的高清地图与环境信息,这些设备7x24小时不间断地产生着远超当前互联网用户行为数据的体量,一辆高级别的自动驾驶汽车一天就可能产生数个TB的数据,由国家或超大型企业建设的,专门用于存储和处理这类机器生成数据的专用数据库,其规模很可能将轻松超越现今我们所知的最大数据库,成为真正的“数据海洋”,可以说,中国最大数据库的纪录本身就是一个不断被刷新和超越的动态目标。

本文由芮以莲于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/75552.html