插曲里怎么把数据往Redis丢,顺便说说插曲数据存储那些事儿

主要基于日常开发中的常见做法和经验总结,非特定技术文档的转述。)
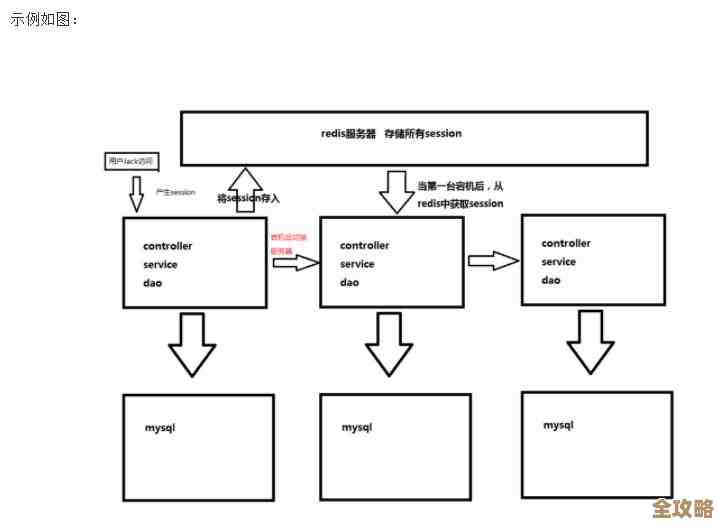
说到在项目里(你提到的“插曲”我理解为项目开发过程中的一个环节或场景)把数据存进Redis,这事儿其实就像往一个超级快的临时仓库里放东西,它不是最终放货物的永久大仓库(比如MySQL),而是门口那个临时周转区,东西放得快,拿得也快,目的是让整个业务流程更顺畅。
怎么把数据往Redis里“丢”?
最常见的方式就是通过代码来操作,比如你用Java写后端,可能会用Jedis或Lettuce这些库;用Python的话,redis-py则是常用工具,这个过程不复杂,大体就几步:

-
连上Redis:就像你要往仓库放东西,得先找到仓库地址、拿上钥匙(密码),在代码里,你需要配置Redis服务器的IP地址、端口号,如果有密码也得配上,连接一般会做成一个连接池,避免每次操作都重新连接,费时费力。
-
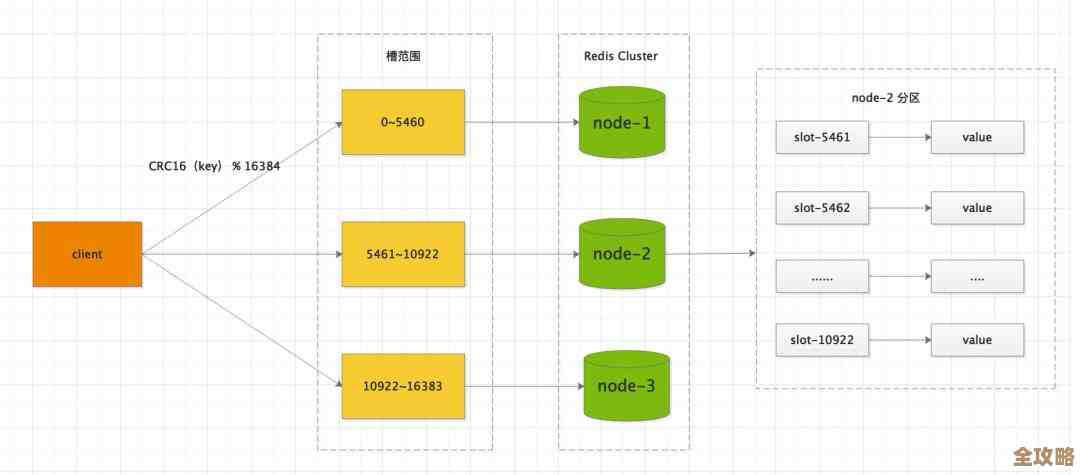
选择“货架”(数据库):Redis默认有16个编号的数据库(0-15),你可以选择把数据丢到哪个数据库里,默认是0号,这有点像大仓库里分不同区域,不过实际项目中,为了避免混淆,很多人干脆用不同的Redis实例来隔离不同业务的数据,而不是挤在同一个实例的不同编号里。
-
选择数据类型并“丢”进去:这是关键,Redis不是简单粗暴地只存字符串,它支持几种不同的“数据结构”,每种适合放不同的东西:

- String(字符串):这是最基础的,比如存个验证码(
SET verification_code:13800138000 123456 EX 300)、某个用户的简单状态(SET user:1001:status online)。EX 300表示300秒后自动过期,这个特性非常常用。 - Hash(哈希):适合存一个对象的多个字段,比如用户信息(
HMSET user:1001 name 张三 age 30 city Beijing),这样一次就能存取一个用户的所有信息,比拆成多个String来存要高效。 - List(列表):像个队列,可以从两头放或取,常用于消息队列(虽然现在有更专业的消息中间件,但简单场景还行)、最新文章列表(
LPUSH latest_articles <article_id>)。 - Set(集合):自动去重的集合,可以用来存某个用户的粉丝列表、共同好友(求交集)、随机抽奖(
SRANDMEMBER)。 - Sorted Set(有序集合):带分数的集合,能按分数排序,排行榜是经典用法(
ZADD leaderboard 1000 player1),还有延迟队列等。
你根据要存的数据特点,选个合适的类型,用对应的命令(如SET, HSET, LPUSH, SADD, ZADD)往里“丢”就行了。
- String(字符串):这是最基础的,比如存个验证码(
-
设置过期时间:非常重要!因为Redis内存宝贵,不能啥都永久存着,对于会话(Session)、缓存数据,一定要记得设置过期时间(TTL),让Redis自动清理,避免内存撑爆。
插曲中的数据存储“那些事儿”

把数据存进Redis只是动作,背后要考虑的“事儿”更多,这些决定了你用得好不好。
-
为啥要用Redis?(选型思考)
- 速度极致:数据主要在内存里,读写飞快,轻松应对高并发,比如秒杀场景,库存检查直接读Redis,扛住第一波压力。
- 丰富的数据结构:如上所述,不只是KV,各种结构能让你更自然地建模,减少应用层处理逻辑。
- 持久化可选:虽然Redis是内存优先,但它也提供RDB(快照)和AOF(日志)两种方式把数据持久化到硬盘,防止重启后数据全丢,可以根据业务在速度和数据安全性间权衡。
- 高可用与扩展:通过主从复制、哨兵(Sentinel)、集群(Cluster)模式,可以实现故障自动切换、数据分片,保证服务可靠性和扩展性。
-
可能会遇到哪些“坑”?
- 数据一致性:这是分布式系统永恒的话题,如果你的数据在Redis(缓存)和MySQL(数据库)各存一份,更新的时候,是先更新数据库还是先删缓存?怎么保证两边数据最终一致?这就是经典的缓存一致性难题,策略有“Cache Aside”、“Read/Write Through”等。
- 缓存穿透:频繁查询一个根本不存在的数据(比如不存在的用户ID),请求会穿透缓存直接打到数据库上,解决办法可以是缓存空值(并设置短过期时间),或者用布隆过滤器提前拦截。
- 缓存雪崩:大量缓存数据在同一时间过期,导致所有请求瞬间涌向数据库,解决方法是为过期时间加上随机值,避免集体失效。
- 缓存击穿:某个热点key过期瞬间,大量请求同时来查这个key,击穿缓存打到DB,可以用互斥锁(比如Redis的SETNX)保证只有一个请求去重建缓存,其他请求等待。
- 内存管理:内存是有限的,当内存满了,Redis有各种淘汰策略(LRU、LFU等)来决定删掉哪些数据来腾地方,选错策略可能导致重要数据被误删。
-
Redis不是万能的
- 它毕竟是基于内存的,成本比硬盘高得多,不能啥都往里扔。
- 它不适合存储超大规模数据(比如TB级),虽然集群可以分片,但管理和成本都是问题。
- 复杂的关系查询、事务处理,还是得靠关系型数据库。
在“插曲”中往Redis丢数据,技术上不难,关键是理解Redis的特性(快、数据结构丰富、可持久化),并根据业务场景(是缓存、是会话、还是排行榜)选择合适的数据类型和操作,更要清醒地认识到它可能带来的问题(一致性、穿透/雪崩/击穿、内存限制),并提前做好预案,把它当成一把锋利的瑞士军刀,用对了事半功倍,用错了也可能伤到自己。
本文由盈壮于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74973.html