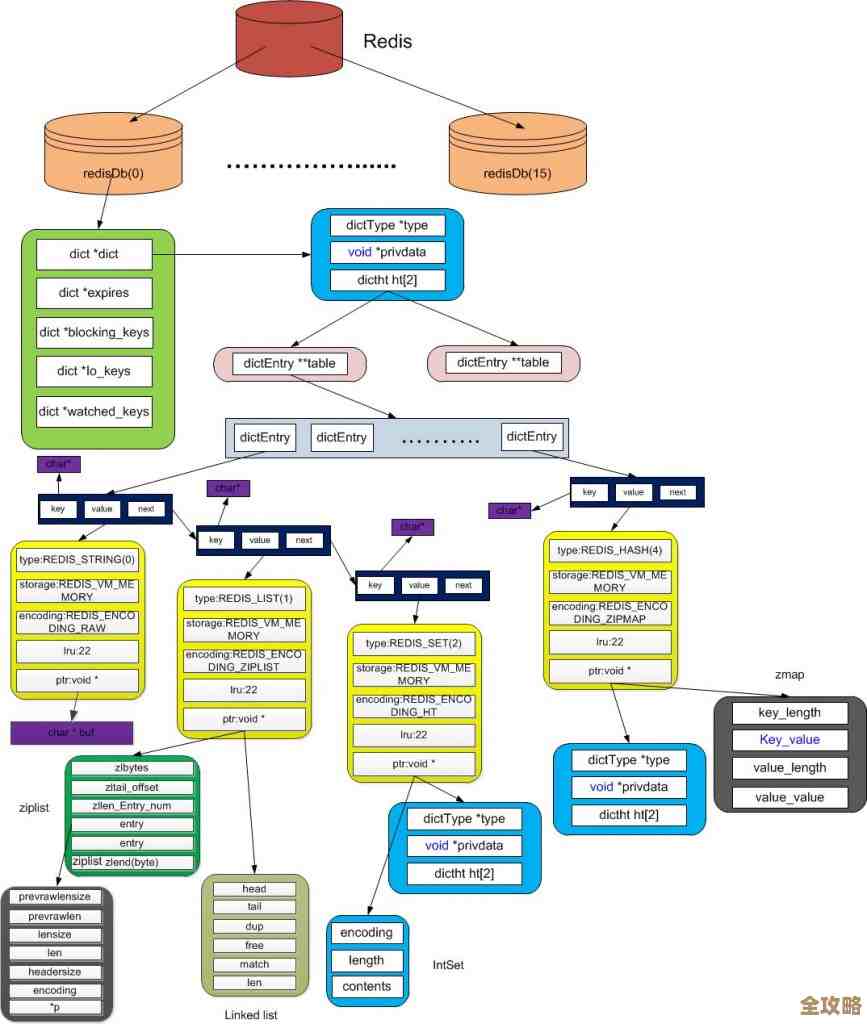
Redis数据统计功能强大,持续助力日常分析和决策优化

Redis数据统计功能强大,持续助力日常分析和决策优化,这个说法在很多技术社区和开发者分享中经常被提及,比如在一些知名的技术博客如InfoQ、CSDN的案例分享里,都能看到实际应用,其核心在于,Redis不仅仅是一个简单的缓存工具,它提供的一系列数据结构和命令,使其能够非常高效地处理各种实时统计需求。
想象一下一个电商平台的场景,每到大型促销活动,双十一”或“618”,运营团队迫切需要实时了解网站的动态:有多少人正在浏览商品?哪个商品被点击的次数最多?有多少商品已经被秒杀完毕?如果这些数据要等到活动结束后再从传统数据库中慢慢计算,那简直就是“马后炮”,完全失去了指导现场运营的意义,而Redis的出色之处就在于,它能以极快的速度应对这些高并发的统计请求。
统计网站的总访问量或者某个页面的浏览次数,这种需求非常普遍,使用Redis的INCR命令,可以轻松实现,每有一次访问,就对某个键(可以理解为某个计数器)执行一次INCR操作,这个操作是原子性的,意味着即使有成千上万个请求同时到来,也能确保每个都被准确计数,不会出现错乱,这个数值可以实时展示在管理后台,让运营人员对流量热度一目了然,CSDN上一位资深架构师在其文章《Redis在计数器场景下的应用》中就详细分析过这种方案的性能和可靠性优势。
再比如,要统计独立用户数,即判断在一段时间内有多少个不同的用户访问了网站(同一个用户多次访问只算一个),如果使用数据库去重查询,在海量数据下会非常缓慢,Redis提供的Set数据结构完美解决了这个问题,可以将每个访问用户的ID直接添加到同一个Set中,因为Set本身就有自动去重的特性,最后只需要一条命令就能获取到集合的元素总数,也就是独立用户数,这种实时统计对于分析用户活跃度和活动效果至关重要,InfoQ网站上一篇关于用户行为分析的文章曾以Redis的Set结构为例,说明了其在高并发场景下的高效性。
还有更复杂的统计场景,比如需要统计最近一小时内最常被搜索的关键词Top 10,这涉及到“排序”和“时间窗口”两个概念,Redis的ZSet(有序集合)结构在这里大显身手,可以将关键词作为成员(member),每次搜索时将其分数(score)增加1,可以利用ZSet的特性,轻松地按照分数从高到低获取排名前列的关键词,为了实现“一小时”的时间窗口,可以结合Redis的过期时间特性,或者每小时生成一个新的ZSet,这样就能持续追踪最新的热点趋势,这种实时热点统计对于编辑推荐、舆情监控或广告投放都具有 immediate 的指导价值,在掘金等技术平台,有众多开发者分享了利用ZSet实现实时排行榜的详细代码和实践心得。
除了这些,Redis还能通过HyperLogLog数据结构以极小的内存消耗估算海量数据的基数(比如估算一天内有多少个不同的IP地址访问),使用位图(Bitmap)来记录用户每天的签到情况等,这些功能共同构成了Redis强大的实时数据统计能力。
正是因为这些贴近业务、响应迅速的特性,Redis在助力日常分析和决策优化方面发挥着不可替代的作用,它让数据从“历史记录”变成了“实时仪表盘”,使得业务负责人能够基于最新、最鲜活的数据洞察,快速做出调整:发现某个商品突然受欢迎,可以立刻加大推广力度;看到某个页面跳出率异常升高,可以立即排查技术或内容问题,这种基于实时反馈的决策闭环,极大地提升了业务的敏捷性和竞争力,正如多位一线互联网公司的技术专家在公开分享中总结的,将Redis用于实时统计,是提升业务响应速度、实现数据驱动运营的一个低成本、高效益的经典实践。

本文由芮以莲于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74878.html