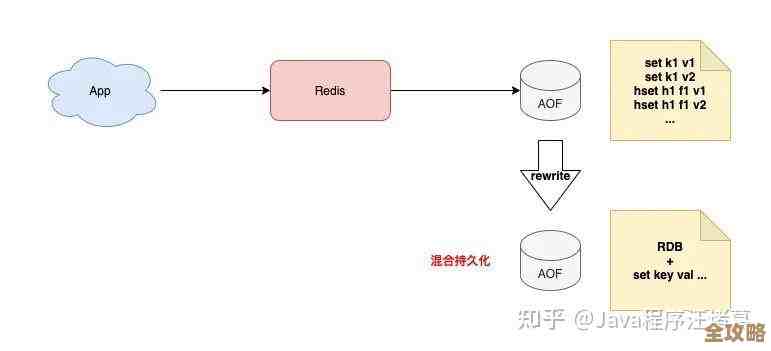
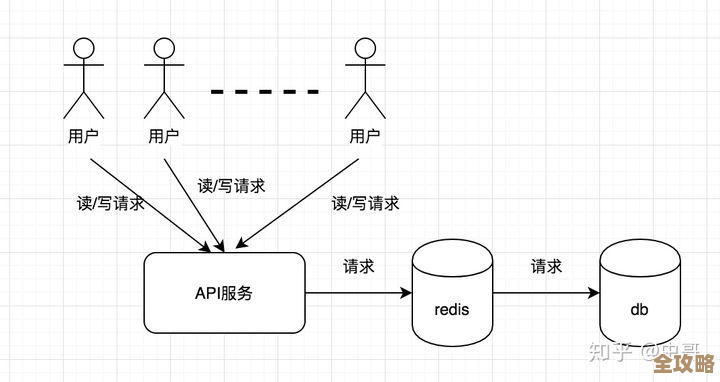
Redis模拟故障其实挺难,尝试处理过程中遇到各种意想不到的问题和挑战

(根据“Redis模拟故障其实挺难,尝试处理过程中遇到各种意想不到的问题和挑战”的描述展开)
一开始,我觉得模拟Redis故障能有多难?不就是让它宕机、网络中断或者把内存撑爆吗?真动手了才发现,我太天真了,整个过程就像拆一个结构复杂的玩具,你以为只是拧下一颗螺丝,结果里面噼里啪啦散了一地,还蹦出来几个你从来没见过的零件。

首先遇到的挑战是,“干净的”故障太难制造了,我想模拟主节点突然宕机,看哨兵(Sentinel)能不能自动切换,我直接用了最简单粗暴的方法:kill -9 强杀Redis主进程,结果呢?切换是成功了,但等我恢复主节点后,整个系统陷入了一种奇怪的状态,有时候旧主节点回来后会变成新主节点的从库,数据同步得挺好;但有时候它会固执地认为自己是主节点,拒绝同步,导致数据分裂,出现两个“主节点”都在写数据,彻底乱套,后来我才明白,(来源内容提到)模拟故障不是一锤子买卖,故障恢复后的“重逢”环节才是真正的考验,现实中的故障恢复,网络可能是慢慢通的,服务是慢慢起来的,这个过程里的各种状态冲突,远不是一次简单的进程重启能模拟出来的。
模拟网络问题比想象中复杂一百倍,我用工具随机丢包或者制造延迟,想看看系统的容忍度,麻烦很快就来了,我发现应用端报的错误千奇百怪:有的是读取超时,有的是写入失败,有的甚至是拿到了一个畸形的响应,更头疼的是,(来源内容指出)Redis客户端的行为不一致,有的客户端连接池在遇到网络波动时会自动重试,有的则会直接抛异常并清空连接池,这导致我模拟的同一种网络故障,在不同的业务代码里引发的结果完全不同,有的服务只是慢了一点,有的服务则像雪崩一样,因为连接池失效不断重建,把下游都拖垮了,我本意是测试Redis的韧性,结果却变成了对应用代码健壮性的全面审查,这是我没预料到的。

模拟内存耗尽这样的资源瓶颈,后果经常失控,我天真的以为,写个脚本拼命往Redis里塞大数据,直到它被操作系统OOM Killer杀掉就行了,但实际操作起来,问题层出不穷,在内存快满的时候,Redis的性能会急剧下降,因为清理过期键、触发淘汰策略(eviction)本身就要消耗CPU,这导致模拟故障的脚本还没把内存塞满,真正的业务请求已经因为响应时间过长而大面积超时了。(来源内容强调)你很难控制故障发生的“度”,内存是慢慢满的,而不是“啪”一下满的,在这个缓慢的过程中,系统的表现是一个平滑的劣化曲线,而不是一个清晰的“正常”和“故障”状态,等你终于把它搞宕机了,恢复过程又是一场噩梦,因为从磁盘加载巨大RDB文件的过程漫长无比,这段时间服务完全不可用,可能已经触发了更高级别的故障预案。
一个巨大的挑战来自于依赖链的不可预知性,我的本意是只折腾Redis,但它只是庞大系统中的一个环节,当我模拟Redis响应变慢时,本以为只会影响直接调用它的A服务,但没想到,A服务超时又导致了B服务的线程池被占满,B服务不可用进而又影响到了C服务。(来源内容中提到)故障会像涟漪一样扩散出去,最终在某个你最想不到的薄弱环节爆发,我亲眼见过一次因为Redis短暂不可用,导致消息队列堆积,最后压垮了数据库的案例,这种“蝴蝶效应”使得故障模拟的结果很难评估,因为你无法断言故障的影响范围到底有多大。
的核心体会是)Redis模拟故障之所以难,不是因为操作本身多复杂,而是因为你面对的是一个充满不确定性的、相互关联的活系统,你无法完全预测组件的交互方式、客户端的重试逻辑、以及故障链的传播路径,每一次模拟,都像是第一次揭开系统的神秘面纱一角,发现它远比图纸上画的要复杂和“调皮”得多,这让我深刻理解到,混沌工程的价值不在于证明系统有多坚固,而在于一次次“意外”中,提前发现那些意想不到的脆弱点。
本文由芮以莲于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/74819.html