用Redis搞横向扩展,性能和规模怎么能不炸裂呢?

“用Redis搞横向扩展,性能和规模怎么能不炸裂呢?”这个问题问到了点子上,单机的Redis再快,内存和CPU也是有限的,硬盘再大有啥用,它主要还是靠内存干活,想把Redis用得风生水起,支撑起海量数据和高并发请求,横向扩展,也就是加机器组成集群,是唯一的出路,但这路怎么走才稳当,才不会“炸裂”,里面有不少门道,咱们就抛开那些晦涩的术语,用大白话聊聊几种主流玩法。
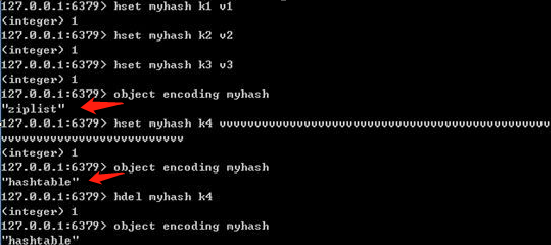
最经典、最广为人知的方法就是分片,有时候也叫分区,这思路特别直接:既然一台机器装不下也处理不过来,那就把数据切成小块,分给不同的Redis实例去保管和处理,好比一个超大的图书馆,书多到一個书库放不下,那就分到几个甚至几十个书库里,每个书库只负责管理某一类或者某一段编号的书,具体怎么分呢?常见的有几种法子,比如范围分片,就是按数据的键(Key)的字母顺序或者数字大小来划分,像把用户ID从1到100万的放到实例A,100万到200万的放到实例B,这个方法简单易懂,但容易导致数据倾斜,万一某个范围内的数据特别多,那台机器就压力山大了,另一种是哈希分片,对键算一个哈希值,再根据哈希值决定它去哪台机器,比如用CRC16算法算一下,然后取模,这种方式能让数据分布得更均匀些,但缺点是如果想增加或减少机器数量,也就是扩容或缩容时,大部分数据都需要重新计算位置并搬迁,动静非常大,这叫重哈希,为了解决这个痛点,Redis官方后来推出了Redis Cluster模式,它用的也是一种哈希分片,但不是简单的取模,而是引入了哈希槽的概念,它把整个数据空间预先分成16384个槽位,集群中的每个节点负责一部分槽位,当需要增删节点时,只需要把一部分槽位连同里面的数据从一个节点迁移到另一个节点就行了,不用全部重新洗牌,这就优雅多了,Redis Cluster自己会处理请求路由,客户端连接上任意一个节点,如果这个节点没有你要的数据,它会告诉你应该去哪个正确的节点找,它还具备主从复制和故障转移的能力,一定程度上保证了高可用,这就像是给每个书库(主节点)配了备份书房(从节点),主书库万一失火,备份书房能立刻顶上。(来源:Redis官方文档关于Redis Cluster的说明)

Redis Cluster也不是万能的,它有个限制,就是不支持跨多个键的操作,如果几个键刚好不在同一个节点上,像交集、并集这类命令就没法直接执行,它的架构和管理相对复杂一些。

那有没有更“懒人”一点的横向扩展方案呢?有,那就是代理模式,这个方法下,Redis实例本身还是一个个的单机或者简单的主从,但在客户端和Redis服务器之间,加一个代理层,这个代理就像一个超级前台,所有客户端的请求都先发给它,由这个代理根据预设的分片规则(比如一致性哈希),把请求转发到后面正确的Redis实例上,对于客户端来说,它只觉得在跟一个Redis打交道,简化了客户端的逻辑,著名的代理中间件有Twemproxy(昵称“nutcracker”)和Codis等,Codis在国内曾经非常流行,它在Twemproxy的基础上做了很多增强,比如支持平滑的扩容缩容,有友好的管理界面等,这种模式的优点是架构清晰,对客户端透明,但缺点是多了一层转发,性能上会有细微损耗,而且代理本身也可能成为单点瓶颈,需要做高可用。(来源:对开源项目Twemproxy和Codis架构设计的普遍认知)
除了在存储层面分片,还有一种思路是针对读多写少的场景,通过主从复制来扩展读性能,就是搭建一个主库(Master)负责写,然后挂多个从库(Slave)来分担读请求,这就像是一个专家负责创作(写),然后找了一大批助手(读)来传播他的思想,数据从主库异步地同步到从库,这样读请求可以分散到多个从库上,大大减轻了主库的压力,这会带来数据一致性的延迟问题,即刚写入主库的数据可能稍后才能在被从库读到,这种架构可以和其他分片方式结合使用,比如每个分片都是一主多从,这样既能分片分担数据和写压力,又能通过复制分担读压力。
回到问题本身,“怎么能不炸裂?”答案就在于根据你的业务特点,选择合适的分片策略和架构,如果追求官方原生支持、能接受跨键操作限制,Redis Cluster是稳健的选择,如果业务需要复杂的多键操作,或者希望更精细地控制,代理模式或许更合适,充分利用主从复制来提升读能力,关键是要提前规划,比如分片键的设计要尽量让数据均匀分布,避免热点;要预留好扩容的空间,避免临时抱佛脚,只要规划得当,Redis的横向扩展确实能让性能和规模都达到一个非常“炸裂”的水平,同时又保持整体的稳定。
本文由称怜于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/73815.html