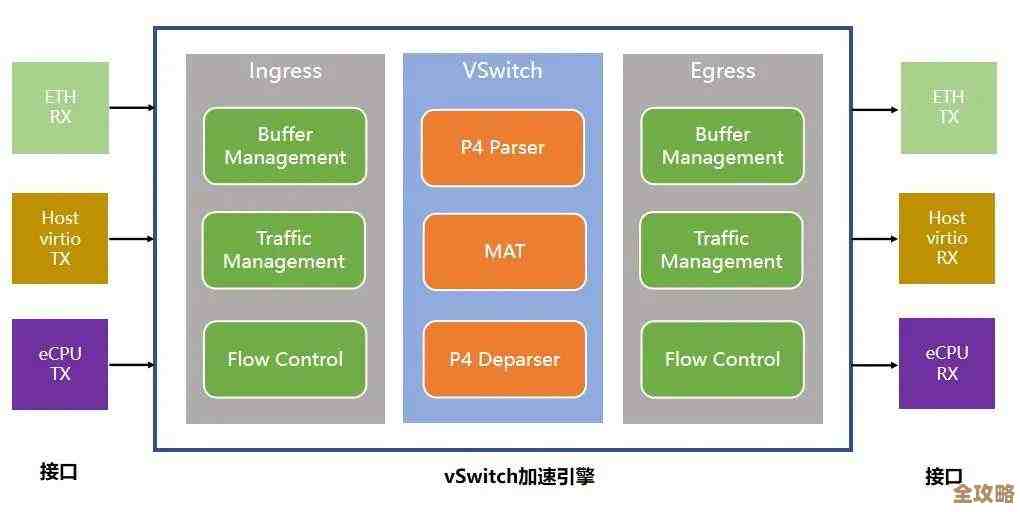
数据库性能提升其实不只是调参数,更多是从架构设计到查询优化全方位考虑

很多人一提到数据库性能不行,第一反应就是去调整几个参数,比如加大内存、改改缓存大小,这就像觉得汽车跑不快,只想着换个更好的火花塞,却忽略了发动机、变速箱甚至整条路况,根据阿里巴巴数据库团队在公开分享中的观点,数据库的性能提升是一个系统工程,必须从最顶层的架构设计开始,一路贯穿到最细粒度的SQL语句优化。
架构设计是决定性能上限的基石,如果架构本身有缺陷,后面再怎么调参数都像是用勺子给漏水的船舀水,事倍功半,这里有几个关键方向,第一是读写分离,大部分业务场景都是“读多写少”,也就是查看数据的请求远远多于修改数据的请求,如果所有请求都压到一台主数据库上,它很容易就不堪重负,一个自然的想法就是把读和写分开,主数据库只负责处理写操作(增、删、改)和少量核心读操作,然后通过数据同步机制,将数据复制到多个只读的从数据库上,这样,大量的查询请求就可以由多个从库来分担,主库的压力就大大减轻了,系统的整体处理能力得到质的提升,这在淘宝、京东这类大型电商网站中是非常普遍的做法。
第二是分库分表,当单张表的数据量达到千万甚至上亿级别时,即使有索引,查询速度也会变慢,而且数据库的备份、恢复都会变得非常困难,这时候就需要把一个大表拆分成多个小表,分表有两种常见方式:水平分表和垂直分表,水平分表好比把一本厚厚的电话簿按姓氏首字母拆成A-G、H-N、O-Z等多本小册子,查询时直接找对应的小册子,速度自然快很多,垂直分表则是把一张表的很多列拆分开,比如把不常用的商品描述信息单独放一张表,让核心的商品信息表变得更“瘦”,提高核心查询的效率,分库则是更进一步,不仅分表,还把不同的表分布到不同的数据库实例上,彻底分散了单台服务器的压力,像微信、支付宝这样的应用,用户数据量极其庞大,分库分表是必须采用的技术手段。
第三是引入缓存,缓存的思想很简单,就是把那些经常被读取、但又很少变化的数据(比如商品分类、用户基本信息、热门文章等)从速度较慢的数据库中搬出来,放到速度极快的内存里(比如Redis或Memcached),下次再需要这个数据时,应用程序首先去缓存里找,找到了就直接返回,找不到再去查数据库,这相当于在数据库前面加了一个高速屏障,绝大部分简单的查询请求在缓存层就被处理掉了,根本不会去打扰数据库,微博的热搜榜、知乎的首页信息流,都重度依赖缓存来支撑海量的并发访问。
架构搭好了,接下来就是应用程序层面的优化,核心是SQL查询语句的优化,再好的架构也架不住糟糕的SQL语句的轰炸,一条写得烂的SQL,可能会锁住整个表,拖慢所有操作,或者一次性扫描几十万行数据,让数据库CPU飙升,优化SQL有几个基本原则,首先要善用索引,索引就像书本的目录,能让你快速定位到想要的内容,为经常用于查询条件的字段建立合适的索引,是提升查询速度最直接有效的方法,但索引不是越多越好,因为索引本身也会占用空间,并且会在数据增删改时降低速度,需要平衡,要避免使用SELECT *,而是需要什么字段就查什么字段,这能减少网络传输和数据解析的开销,要警惕多表关联查询(JOIN),尤其是关联表很多或者数据量很大的时候,复杂的JOIN可能成为性能杀手,拆分成多个简单的查询,在应用程序里进行组合,效果反而更好,要学会使用数据库的执行计划分析工具(如MySQL的EXPLAIN),它能告诉你数据库是如何执行这条SQL的,有没有用上索引,在哪里出现了全表扫描,从而有针对性地进行优化。
才是我们常说的参数调优,比如调整数据库的内存缓冲区大小,让更多热数据可以留在内存中;调整连接数,避免连接过多导致资源争抢,但这些参数的调整必须建立在良好的架构和优秀的SQL之上,否则就是治标不治本,就像《高性能MySQL》这本书里强调的,不合理的Schema设计(数据库表结构设计)和查询语句,是性能问题的首要原因,而配置问题通常排在后面。
数据库性能提升是一个从宏观到微观、环环相扣的过程,正确的顺序应该是:先审视架构是否合理(读写分离?分库分表?缓存用好了吗?),再检查应用程序的SQL语句是否高效(索引是否缺失?查询是否臃肿?),最后才是根据具体的硬件和工作负载,对数据库参数进行精细的微调,只有这样全方位地考虑和行动,才能打造出一个真正健壮、高效的数据系统。

本文由邝冷亦于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/72021.html