数据库语句到底是怎么一步步被执行的,里面发生了啥过程呢

当我们打开一个软件,比如一个网站或者手机APP,点击一个查询按钮时,一句简单的数据库查询语句(SELECT * FROM users WHERE name = '小明')就会从你的应用发送到数据库,这个过程看起来瞬间完成,但数据库内部其实像一条高度自动化的流水线,为这个请求进行了一系列复杂而有序的操作,下面我们就一步步拆解这条流水线。
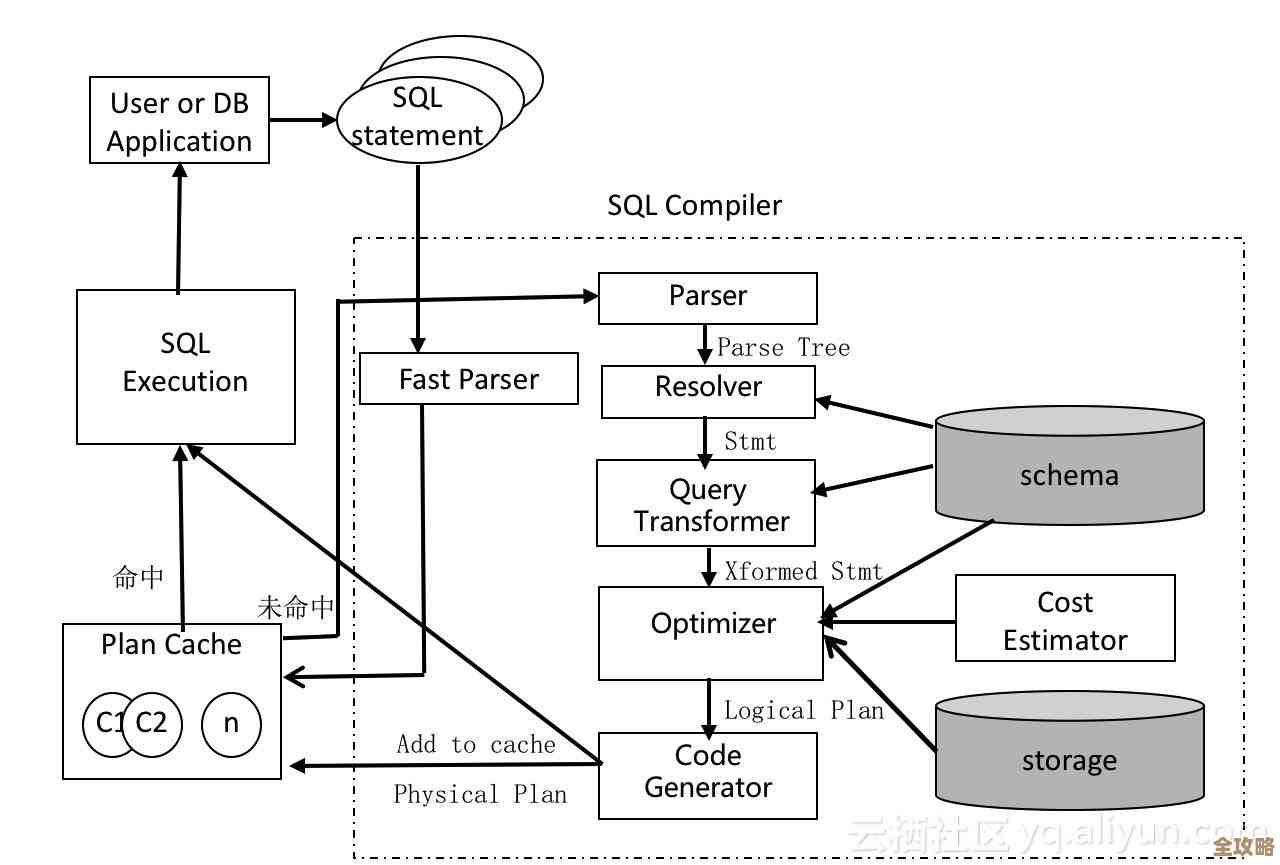
语句到达数据库后,第一个迎接它的是一个叫做 “解析器” 的部门(引用自《数据库系统概念》中关于查询处理的第一步),这个部门的工作是当“语法老师”,它会像检查句子有没有主谓宾一样,检查你写的SQL语句在语法上是否正确,它要确认关键词SELECT、FROM有没有拼错,表名users在数据库中是否存在,字段name是不是users表里的合法列,如果这里出错了,比如你把FROM写成了FORM,解析器会立刻抛出一个错误,告诉你“你的SQL句子写得不规范”,整个过程就会在这里中断。
语法检查通过后,解析器还要做一件事,叫做 “语义分析”,它会进一步检查这句话的“意思”是否合理,它要确认你有没有权限查询users表,‘小明’这个值的类型和name字段定义的类型(比如是文本类型)是否匹配,这一步确保请求不仅是形式正确的,也是被允许且逻辑上可行的。
语句被送到了数据库的“大脑”或“规划中心”,也就是 “查询优化器”(这是数据库核心组件,在多数数据库系统如MySQL、PostgreSQL的架构文档中均有重点描述),这是整个流程中最关键、最智能的一步,优化器接收到的是一条“要做什么”的指令,但它需要决定“怎么做”最高效,因为通往同一个目的地的路径可能有很多条。
我们的例子是查找名叫“小明”的用户,优化器会思考:users表里有上千万条数据,我该怎么找?是全表扫描,也就是从第一条数据开始,逐条比对name字段是不是等于‘小明’?还是说,name字段上有一个“索引”(类似一本书最后的索引目录)?如果有索引,我可以直接去索引里快速找到所有“小明”对应的数据位置,然后根据这些位置去表里精准抓取数据,显然,后一种方法在数据量大的时候要快得多。
优化器就像一个老练的导航软件,它会根据数据的统计信息(比如表有多大、索引有哪些、数据分布情况等),估算每一种执行路径的“成本”(主要是需要读取的数据量大小和计算时间),然后从众多可能的执行计划中,选择一个它认为成本最低、速度最快的方案,这个最终确定的行动方案,就叫做 “执行计划”。
一旦最优的“执行计划”被制定出来,就进入了 “执行器” 的工作阶段(对应数据库引擎的执行层),执行器就像一个实干家,它严格遵循优化器产生的执行计划说明书,一步步地调用底层的组件去完成任务。
如果计划是“使用索引查找”,执行器就会先去访问索引结构,通过索引找到所有匹配‘小明’这个条件的数据行在磁盘上的位置(比如第100号数据页的第5行),它再根据这些位置信息,到真正的数据表文件(存储在硬盘上)中去把完整的一行行数据读取出来。
这里就涉及到另一个重要角色:“存储引擎”(如MySQL的InnoDB,引用自MySQL官方文档),存储引擎是真正负责数据存储和管理的组件,它管理着数据在磁盘上如何摆放、如何读取、如何缓存,执行器需要数据时,就向存储引擎“下单”,存储引擎会先检查需要的数据是否已经在内存的“缓存池”里了,如果在,就直接从内存返回,速度极快;如果不在,就需要发动一次相对缓慢的磁盘IO操作,把数据从硬盘读进内存,再交给执行器。
执行器收集齐所有符合条件的数据行后,会进行最后的整理,比如按照ORDER BY子句进行排序,或者计算一些聚合函数如COUNT,它将处理好的结果集返回给最初发起请求的客户端应用程序,你的软件界面上就显示出了“小明”的用户信息。
一个简单的数据库查询,背后是环环相扣的四个主要阶段:解析(检查语句对不对)、优化(选择最佳执行路径)、执行(按计划实际操作)、以及底层支撑的存储访问(读写数据),正是这套精密协作的机制,保证了我们能够高效、准确地从海量数据中获取想要的信息。

本文由寇乐童于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/71921.html