MSSQL数据库分表那些事儿,聊聊怎么高效提升性能更靠谱

说到数据库,尤其是像MSSQL这样的关系型数据库,当数据量小的时候,一切都显得那么美好,但随着业务发展,数据像滚雪球一样越滚越大,一张表里存了几千万甚至上亿条记录,这时候问题就来了,你会发现,以前跑得飞快的查询,现在慢得像蜗牛;日常的备份和维护操作,时间长得让人无法忍受,这时候,有经验的老司机通常会提到一个词:“分表”。
分表,说白了,就是想办法把一张大表拆分成几个小的、更易于管理的部分,这听起来简单,但具体怎么做才能真的提升性能,而不是把事情搞得更复杂,这里面有不少门道,今天我们就来聊聊几种常见的分表方法,以及怎么选才更靠谱。
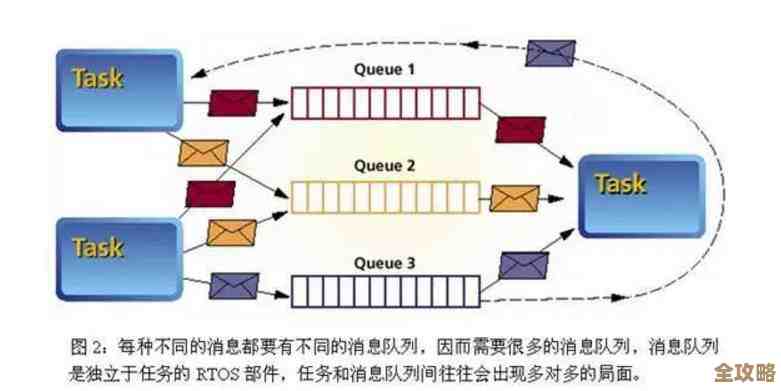
第一种常见的方法叫“水平分表”,也有人叫它“按行分表”。 这是最常用的一种分表方式,它的思路不是去动表的结构(比如把姓名、地址这些字段分到不同表里),而是按照某种规则,把表中的数据行分散到多个结构完全相同的表里去,举个例子,你有一张存储所有用户订单的Orders表,数据量太大了,你可以按时间分,比如把2023年的订单放在Orders_2023表里,2024年的订单放在Orders_2024表里,你也可以按用户ID的哈希值取模来分,比如把用户ID除以10的余数作为分表依据,这样就能把数据相对均匀地分到10张表里(Orders_00到Orders_09)。
这种方法的优点是查询范围缩小了,比如你要查某个用户最近三个月的订单,如果数据都在一张大表里,数据库需要扫描海量数据,但如果你是按月分表的,它可能只需要扫描Orders_202401、Orders_202312、Orders_202311这三张表,工作量瞬间小了很多。(思路参考自普遍的分库分表实践) 它的挑战在于,应用程序需要知道数据存在哪张表里,查询时要能动态地选择正确的表,跨分表的查询(比如统计全年数据)会变得复杂,可能需要用到UNION ALL操作。

第二种方法是“垂直分表”,也叫“按列分表”。 这种方法是根据数据列的访问频率和大小,把一张宽表拆分成多张窄表,通常会把经常访问的、核心的字段放在一张主表里,而把那些不常访问、数据长度很大的字段(比如文章内容、商品详情描述等文本,或者图片的二进制地址)拆分到另外的扩展表里,主表和扩展表通过主键(比如订单ID)进行关联。
这样做的好处是,当大多数查询只需要核心字段(比如订单号、金额、状态)时,数据库的一次I/O操作能加载更多的数据行到内存中,因为单行数据变小了,从而提高了缓存效率,加快了查询速度。(原理参考数据库优化中的“行溢出”和I/O效率概念) 查询订单列表时,只需要扫描窄小的主表,速度会快很多,只有当需要查看订单详情时,才去关联查询扩展表,这种方法对应用程序的改动相对较小,因为逻辑上它还是一笔完整的订单记录。
到底哪种方法更靠谱呢?这得看你的具体业务场景。

- 如果你的业务瓶颈在于单表数据量过大,导致查询、插入、索引维护变慢,特别是热点数据(比如总是操作最近的数据)和冷数据(历史数据)区分很明显,那么水平分表通常是更直接有效的选择。 比如日志系统、交易记录系统,按时间分表是非常自然的做法。
- 如果你的表字段非常多,但很多字段又大又长,且访问不频繁,导致即使数据量不大,简单查询也受影响,那么你应该优先考虑垂直分表。 比如用户表,把用户名、密码、最后登录时间等常用信息放在主表,把个人简介、头像地址等放在扩展表。
在实际生产中,这两种方法也经常结合使用,先对订单表进行垂直分表,拆出核心信息和详情信息,再对核心信息表按照用户ID进行水平分表,这样就形成了一个纵横交错的拆分方案,能从多个维度缓解单一大表的压力。
除了手动管理这些分表,MSSQL自己也提供了一些内置的功能来帮助我们,这就是分区表,分区表可以看作是数据库引擎原生支持的、更“自动化”的水平分表,你只需要定义一个分区函数(告诉数据库按什么规则分,比如按时间范围)和一个分区方案(告诉数据库每个分区对应到哪个文件组),剩下的数据分布、查询路由等工作就由MSSQL自己来管理。
使用分区表的最大好处是对应用程序透明,你的代码可以像操作一张普通表一样去查询和操作分区表,数据库优化器会自动判断需要访问哪些分区,这大大降低了应用程序的复杂度和维护成本。(特性描述基于Microsoft SQL Server官方文档关于分区表的部分) 特别是在做数据归档时,比如要快速删除一年的旧数据,在分区表上可以直接“切换”掉整个分区,这个操作是元数据级别的,速度极快,避免了耗时的DELETE操作,如果你的分表需求主要是基于范围(尤其是时间范围),并且希望尽量减少对应用的侵入性,MSSQL的分区表是一个非常靠谱的优先选择。
分表是提升MSSQL数据库性能的一把利器,但绝不是银弹,在选择分表方案前,一定要仔细分析你的业务数据特性和访问模式,是数据行太多,还是单行太宽?是查询慢,还是维护难?搞清楚问题的根源,才能选择最匹配的方案,对于大多数场景,从垂直分表入手优化往往性价比更高,当数据量增长到一定程度后,再考虑结合水平分表或直接使用分区表,这样循序渐进的方式通常更稳妥、更靠谱。
本文由召安青于2025-12-27发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://waw.haoid.cn/wenda/69351.html